本周我们小组在分析上周用户需求之后,确定了网站的主要框架和功能、数据收集和存储方式,以及项目任务分配。
一、网站的主要框架和功能。
网站近期将要实现的主要功能有,先重点收集高校(华东五校)就业宣讲会的的信息,可以按宣讲会的发布时间、发布高校进行分类显示。后期再加入公司所属行业类别、公司简介、公司评价等信息。后期效果图:
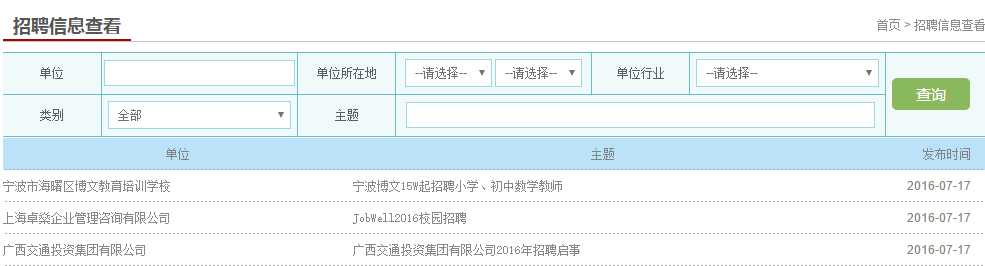
二、数据收集和存储方式。
数据搜集目标是高校就业官网的宣讲会信息,包括公司名称、宣讲会时间、宣讲会地点,宣讲会介绍(链接),所属高校。
搜集方法是python网络爬虫,主要用到的库为:requests、BeautifulSoup。python版本为2.7+。以复旦大学的就业网爬虫程序为例,如下所示:
1 # -*- coding:utf-8 -*- 2 3 import requests 4 from bs4 import BeautifulSoup 5 6 url = ‘http://www.career.fudan.edu.cn/jsp/career_talk_list.jsp‘ 7 front = ‘http://www.career.fudan.edu.cn/html/xjh/1.html?view=true&key=‘ 8 9 #查询count条记录 10 post_data = { 11 ‘count‘:‘20‘, 12 ‘list‘:‘true‘, 13 ‘Referer‘: "http://www.career.fudan.edu.cn/jsp/career_talk_list.jsp?count=20&list=true&page=1", 14 ‘Host‘:"www.career.fudan.edu.cn", 15 ‘User-Agent‘:"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0" 16 } 17 return_data = requests.post(url, post_data) 18 soup = BeautifulSoup(return_data.text,‘lxml‘) 19 for job in soup.find_all(id = ‘tab1_bottom‘): 20 url = front + job.get(‘key‘) 21 name = job.find(class_ = ‘tab1_bottom1‘).get_text() 22 types = job.find(class_ = ‘tab1_bottom2‘).get_text() 23 date = job.find(class_ = ‘tab1_bottom3‘).get_text() 24 time = job.find(class_ = ‘tab1_bottom4‘).get_text() 25 place = job.find(class_ = ‘tab1_bottom5‘).get_text() 26 print name, types, place, date, time 27 print url,‘\n‘
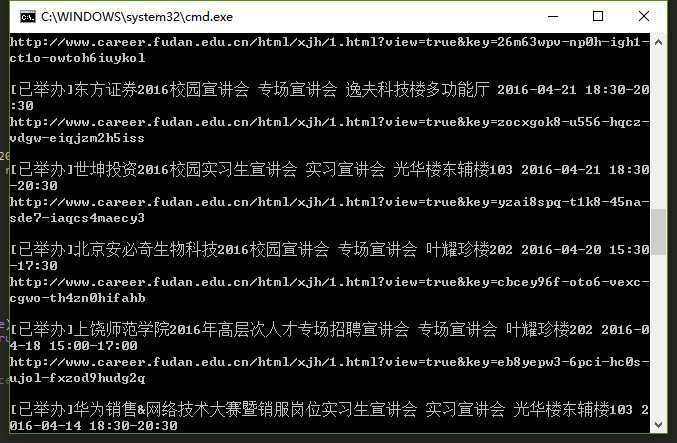
数据库存储选用Mysql,利用MYSQLdb进行python与数据库的连接,对于宣讲会信息存储,表内主要字段有公司名称(xjh_name)、宣讲会时间(xjh_time)、宣讲会地点(xjh_place),宣讲会介绍链接(xjh_url),所属高校(school_name)。
三、团队人员任务分配。
网页设计与后端:李嫣然、宫亚南、崔文祥、王涛。主要开发技术:Html、CSS、Javascript、Java Web(tomcat部署)
数据搜集与存储:冀若阳、尤东森
原文:http://www.cnblogs.com/HouseStark/p/5679713.html