Given n, how many structurally unique BST‘s (binary search trees) that store values 1...n?For example,Given n = 3, there are a total of 5 unique BST‘s.

首先,需要明确binary search tree的定义。这里引用一下wiki的链接。
另外,需要明确什么是structurally unique。这里按照我的理解,应该是指两个BST之间的关系,structurally unique可以这么递归定义,两个BST均从根起,根节点不同或者对应的左子树或右子树structurally unique.
联想得到的一些结论:
二叉树-由于结构的特殊性,常使用递归的方法解决问题,分而治之。
二分查找树-由于二分查找树本身的有序性,可以考虑是否通过遍历不同结构的BST可能会得到不同的序列,通过查找不同序列的数目来确定BST不同结构的数目。通过验证n=3,发现这种思路不可行,已经可以排除这种情况。
演绎推理:
首先,考虑如何从特殊、小规模情况分析获得规律。设num代表unique BST的数目。
n=1,num=1
n=2,num=2
n=3,num=5
这里特别观察了一下题目中给出了图片的n=3的情况,发现根节点出现过1,2,3,考虑是否可以通过分析1~n分别为root的时候num的值,得到它们的累加和即为结果。
结合联想中提到的分而治之的用法,如果我选取了一个j(1 < j < n)作为root,根据BST的定义,1~j-1一定是在左子树上,j+1~n一定是在右子树上,问题可以分解为,得到左、右子树的不同结构数目,它们的乘积就是选定j的时候,num的值。这是依据排列组合的乘法原理。
同时我们考虑分而治之的方法,结合上面的分析,我们要求num值,即需要求对1~n中每一个值j作为root,1~j-1的num和j+1~n的num的乘积,这就将问题划分为了更小的规模。
递归处理问题的时候,一定需要注意边界条件。在这里先统一假设已经确定了某一个j作为root。假设左子树只有一个元素的时候,可得左子树的num=1,倘若左子树为空,这个时候对应的左子树num值应该是没有意义的,设右子树num=k(k>0),这个时候对应的总num应该是k,我们可以通过检查某个子树为空时,进行特殊的判断,取另外的不为空的子树的num值作为总num值,我们也可以巧妙地给空子树设定一个num=1的值,让这种情况也可以通过乘法定理计算出来,可以保持代码的简洁性和一致性,不用再做特殊判定。
回到边界条件的判定上来,到底什么才是边界条件,如何得到边界条件。我的考虑是,首先结合当前问题,我们是将规模为1..j..n的问题,划分为1...j-1和j+1...n,规模越来越小,最后会收缩成为子树只包含1个元素,最后子树为空的情况。这个时候只要给出子树为空的值就可以终结整个递归的过程。
代码:
感觉到这里,已经想的差不多了,可以开始写写代码。本来想直接定义一个f(n),发觉这样不行,因为我会将问题分解为1~j-1,j+1~n,f(n)不能代表j+1~n的情况,所以这里我用f(lst)来定义,lst就代表一个有序数组。
代码见此:
class Solution:
def get_num_trees(self, lst):
if not lst:
return 1
r = 0
for index, item in enumerate(lst):
left_num = self.get_num_trees(lst[:index])
right_num = self.get_num_trees(lst[index + 1:])
r += left_num * right_num
return r
# @return an integer
def numTrees(self, n):
return self.get_num_trees(range(1, n + 1))
很不幸,这段代码超时了,如果我多添加一个len(lst)==1的判断,代码是能过的,不过耗时780ms,那么接下来就需要分析一下这段代码的时间复杂度以及到底还有没有优化的空间吧。
时间复杂度分析这一块内容暂时略过,具体可以参考算法导论第二章使用递归树分析合并排序复杂度的部分。分析结果是这种做法的复杂度会是n + 2*(n -1) + 4 * (n - 2) + 8 * (n - 3)....比O(2^n)还要大,小于O(n*2^n),怪不得如此之慢。
怎么优化呢?看了看上面的代码,考虑貌似num值与lst里面具体的元素无关,只和这个列表的长度相关,发散一下,是否是对于任何一个排好序的数组a1,a2,a3...an,它们的num值应该是相同的?考虑到BST自身的性质,也就是规定了左子树任一节点<root<右子树任一节点,这个结论直觉上是成立的。我这里不太清楚严谨的数学证明应该怎样给出。
这个时候,之前设函数f(n),现在的子问题就划分为了f(j), f(n - j -1),这里出现了更小规模的重复子问题,一下子就联想到了动态规划。这里考虑对于n的序列,不断的将n分割成另外两个小序列。即可以得到状态方程f(n) = f(0) * f(n-1) + f(1) * f(n-2)+....+f(n-1)*f(0)
class Solution:
# @return an integer
def numTrees(self, n):
r = [1] + [0] * n
for i in xrange(1, n + 1):
for j in xrange(0, i):
r[i] += r[j] * r[i - j - 1]
return r[n]
这个算法一看就知道是o(n^2),还勉强可以接受吧。
再晃眼一看,这个序列看起来像是有通项公式的数组,去网上搜了一下,发现这个序列正好叫做卡特兰数,果然有递推公式存在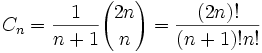
那就再来一段code吧。
class Solution:
# @return an integer
def factorial(self, n):
r = 1
for i in xrange(1, n+1):
r *= i
return r
def numTrees(self, n):
return self.factorial(2 * n) / (self.factorial(n + 1) * self.factorial(n))由于通项公式里面有阶乘计算,所以得到了o(n)的复杂度。
这到题目就分析到这个地方,关于O(N)是否是最佳的解决方案,我并不能证明,不知道还有没有其他牛逼的做法。
LeetCode - Unique Binary Search Trees,布布扣,bubuko.com
LeetCode - Unique Binary Search Trees
原文:http://blog.csdn.net/xianyubo_lisp/article/details/25094087