本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西
附上原创链接:
http://www.cnblogs.com/qiyeboy/p/5428240.html
基本思路是,查看网页元素,填写xpath表达式,获取信息。自动爬取策略是,找到翻页网页元素,获取新链接地址,执行翻页。网页分析部分不再赘述,原博讲的很好很清楚,很涨姿势
基于拿来主义,我们只需要知道怎么更改Scrapy框架就行了~
items.py:
import scrapy class TestprojItem(scrapy.Item): image_urls = scrapy.Field();
由于仅关注图片信息,所以这里item只定义了一个元素。
spider.py:
class FirstSpider(scrapy.Spider): name = "jiandan" allowed_domains = ["http://jiandan.net/ooxx"] new_url = None start_urls = [ "http://jiandan.net/ooxx" ] def parse(self, response): item = TestprojItem() item[‘image_urls‘] = response.xpath(‘//img//@src‘).extract() #print "extracting..." + ‘‘.join(item[‘image_urls‘]) yield item self.new_url = response.xpath(‘//a[@class="previous-comment-page"]//@href‘).extract_first() print ‘new_url:\t‘ + self.new_url if self.new_url: self.start_urls.append(self.new_url) yield scrapy.Request(self.new_url, callback=self.parse, dont_filter=True)
回顾并强调一下本次任务的目标:简单上的妹子图片!
上面是我自己修改的代码,可能allowed_domains字段设置有问题,每次重新爬取的时候会被认为是非法,所以在代码最后一行加了个 dont_filter=True.
parse: 对爬取页面进行解析。其中,new_url是获取翻页请求地址,然后在最后一行scrapy.Request重新请求。
pipelines.py:
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don‘t forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html import os import urllib from testProj import settings class TestprojPipeline(object): def process_item(self, item, spider): dir_path = ‘%s%s‘ % (settings.IMAGES_STORE, spider.name) print ‘dir_path:‘, dir_path if not os.path.exists(dir_path): os.makedirs(dir_path) for image_url in item[‘image_urls‘]: list_name = image_url.split(‘/‘) file_name = list_name[len(list_name)-1] file_path = ‘%s%s‘%(dir_path, file_name) if os.path.exists(file_name): continue with open(file_path, ‘wb‘) as fw: conn = urllib.urlopen(image_url) fw.write(conn.read()) fw.close() return item
对爬取的元素进行处理。本文直接放到某个本地文件夹中,所以最后有文件读写。
其中settings.IMAGES_STORE需要进入settings进行设置。
OK,基本完成。切入cmd, scrapy crawl jiandan 瞬间完成,进入文件夹,什么也没有啊?查看cmd输出信息
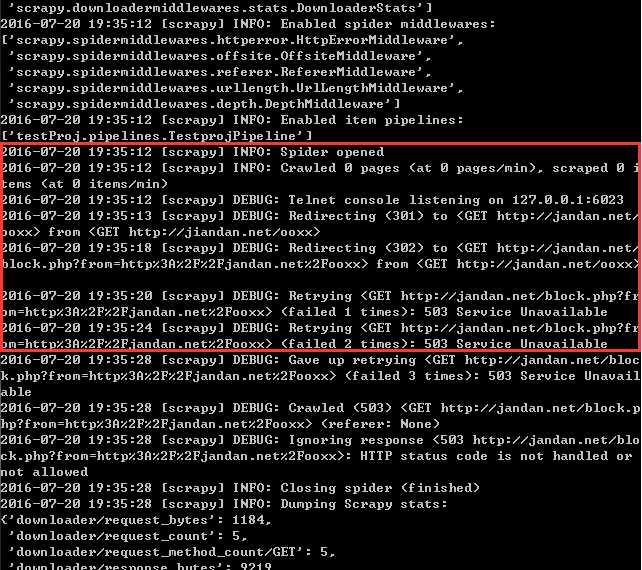
重定位到一个奇怪的url, 打开来看

我是小白,原来这就是被网站ban了。很多网站有反爬虫设置。如何突破?基本策略有以下几点:
好几条看不懂。我自己研究。浏览器再次打开简单网,能打开。说明需要伪装成浏览器想服务器发送请求。
工程下新建 middlewares.py文件,代码如下:
import random class RandomUserAgent(object): def __init__(self, agents): self.agents = agents @classmethod def from_crawler(cls, crawler): print ‘in from crawler‘ return cls(crawler.settings.getlist(‘USER_AGENTS‘)) def process_request(self, request, spider): print ‘in process request‘ request.headers.setdefault(‘User-Agent‘, random.choice(self.agents))
settings.py中做相应修改:
USER_AGENTS = [ "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)", #中间还有很多,这里省略了 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11", "Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10" ] COOKIES_ENABLED = False DOWNLOADER_MIDDLEWARES = { ‘scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware‘ : None, ‘testProj.middlewares.RandomUserAgent‘: 100 }
这里 DOWNLOADER_MIDDLEWARES 字段的修改很重要,它相当于是定位到之前写的middlewares.py文件。注意一下,我是吧middlewares.py文件放在testProj项目根目录下,和items.py之类在一起,才这样写,如果其他目录,可能需要改变名称。(但是我放在testProj/middlewares/middlewares.py,setting里面写 testProj.middlewares.middlewares.RandomUserAgent依旧没用,不知道为什么,调了很久)
OK。大致完成
但是我发现下载了大概2000张图片之后又下不动了,整个Scrapy就卡在那儿,也不输出日志,不清楚什么原因,可能是需要加入ip代理,下次再来研究吧。
原文:http://www.cnblogs.com/flowingcloud/p/5689513.html