我们在做数据分析的时候,对数据进行操作也是一项极其重要的内容,这里我们同样介绍强大包reshape2,其中的几个函数,对数据进行操作cast和melt两个函数绝对少不了。
首先是cast,把长型数据转换成你想要的任何宽型数据,
dcast(data, formula, fun.aggregate = NULL, ..., margins = NULL, subset = NULL, fill = NULL, drop = TRUE, value.var = guess_value(data))
acast(data, formula, fun.aggregate = NULL, ..., margins = NULL, subset = NULL, fill = NULL, drop = TRUE, value.var = guess_value(data))
参数:
data 要进行转换的数据框
formula 用于转换的公式
fun.aggregate 聚合函数,表达式为:行变量~列变量~三维变量~......,另外,.表示后面没有数据列,…表示之前或之后的所有数据列
margins 用于添加边界汇总数据
subset 用于添加过滤条件,需要载入plyr包
其他三个参数,用到的情况相对较少。
下面来看些具体的例子
先构建一个数据集
x<-data.frame(id=1:6,
name=c("wang","zhang","li","chen","zhao","song"),
shuxue=c(89,85,68,79,96,53),
yuwen=c(77,68,86,87,92,63))
x
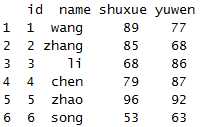
先使用melt函数对数据进行融化操作。
library(reshape2)
x1<-melt(x,id=c("id","name")) x1
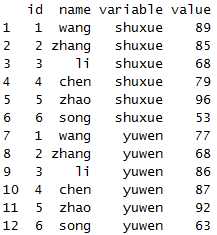
可以看到数据已经变成了长型数据(melt函数后面详细介绍)。
接下来就是对数据进行各种变型操作了。
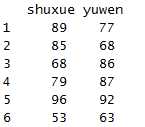
acast(x1,id~variable)
dcast(x1,id~variable)
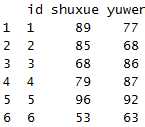
从以上两个执行结果来看,可以看出acast和dcast的区别
这里acast输出结果省略了id这个列,而dcast则输出id列
acast(x1,id~name~variable)
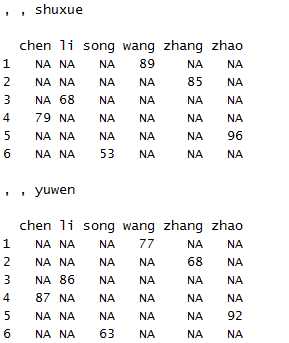
三维的情况下acast输出的是一个数组,而dcast则报错,因为dcast输出结果为数据框。
dcast(x1,id~variable,mean,margins=T)
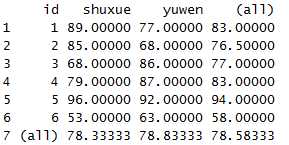
可以看到,边缘多了两列汇总数据是对行列求平均的结果。
dcast(x1,id~variable,mean,margins=c("id"))
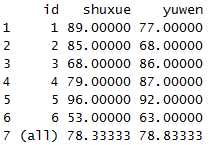
只对列求平均值,当然也可以只对行求平均值,把id改成variable就可以了。
library(plyr) dcast(x1,id~variable,mean,subset=.(id==1|id==3))
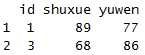
这里subset的筛选功能强大可以进行各种各样的筛选操作,类似filter的作用。
dcast(x1,id+name~variable)
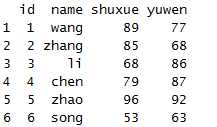
数据还原成原来的样子了。
dcast(x1,variable~name)
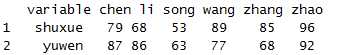
对行列进行对调。
acast(x1,variable~id+name)

到这里,我们已经着实体会了cast的强大,数据几乎可以转换成任何形式。
跟excel中的数据透视表功能类似。
原文:http://www.cnblogs.com/wkslearner/p/5731015.html