再使用hbase 命令之前先检查一下hbase是否运行正常

hadoop@Master:/usr/hbase/bin$ jps 2640 HMaster 27170 NameNode 27533 SecondaryNameNode 3038 Jps 27795 TaskTracker 27351 DataNode 2574 HQuorumPeer 27618 JobTracker 2872 HRegionServer
如果运行不正常的话,关闭hbase后重新启动一下
stop-hbase.sh
start-hbase.sh
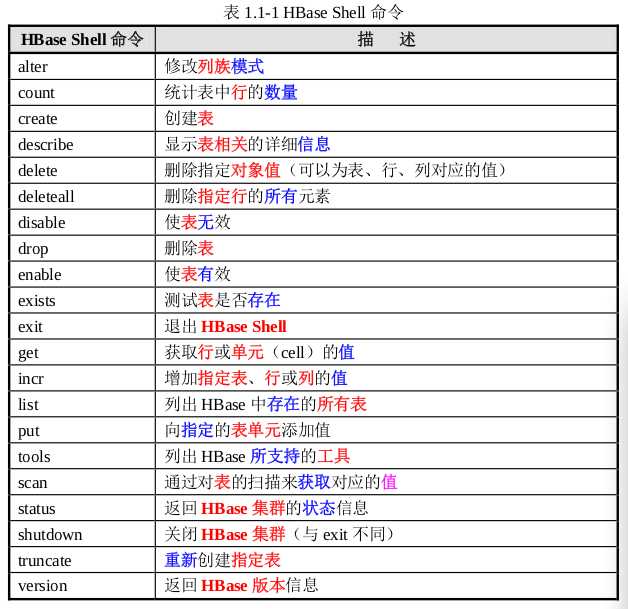
1. status命令
hbase(main):008:0> status 1 servers, 0 dead, 3.0000 average load
2. version命令
hbase(main):007:0> version 0.94.12, r1524863, Fri Sep 20 00:25:45 UTC 2013
3. create 命令
创建一个名为 test 的表,这个表只有一个列为 cf。其中表名、列都要用单引号括起来,并以逗号隔开。
hbase(main):001:0> create ‘test‘, ‘cf‘ 0 row(s) in 10.3830 seconds
4. list 命令
查看当前 HBase 中具有哪些表。
hbase(main):009:0> list TABLE test 1 row(s) in 0.3590 seconds
5. put 命令
使用 put 命令向表中插入数据,参数分别为表名、行名、列名和值,其中列名前需要列族最为前缀,时间戳由系统自动生成。
格式: put 表名,行名,列名([列族:列名]),值
例子:
加入一行数据,行名称为“row1”,列族“cf”的列名为”(空字符串)”,值位 value1。
我这里插入3条记录
hbase(main):003:0> put ‘test‘, ‘row1‘, ‘cf:a‘, ‘value1‘ 0 row(s) in 0.2350 seconds hbase(main):004:0> put ‘test‘, ‘row2‘, ‘cf:b‘, ‘value2‘ 0 row(s) in 0.0350 seconds hbase(main):005:0> put ‘test‘, ‘row3‘, ‘cf:c‘, ‘value3‘ 0 row(s) in 0.0040 seconds
6. describe 命令
查看表“test”的构造。
hbase(main):010:0> describe ‘test‘ DESCRIPTION ENABLED ‘test‘, {NAME => ‘cf‘, DATA_BLOCK_ENCODING => ‘NONE true ‘, BLOOMFILTER => ‘NONE‘, REPLICATION_SCOPE => ‘0‘, VERSIONS => ‘3‘, COMPRESSION => ‘NONE‘, MIN_VERSIO NS => ‘0‘, TTL => ‘2147483647‘, KEEP_DELETED_CELLS => ‘false‘, BLOCKSIZE => ‘65536‘, IN_MEMORY => ‘fal se‘, ENCODE_ON_DISK => ‘true‘, BLOCKCACHE => ‘true‘ } 1 row(s) in 1.6630 seconds
7.get 命令
a.查看表“test”中的行“row2”的相关数据。
hbase(main):011:0> get ‘test‘,‘row2‘ COLUMN CELL cf:b timestamp=1381568161926, value=value2 1 row(s) in 0.4500 seconds
b.查看表“test”中行“row2”列“cf :b”的值。
hbase(main):012:0> get ‘test‘,‘row2‘, ‘cf:b‘ COLUMN CELL cf:b timestamp=1381568161926, value=value2 1 row(s) in 0.3090 seconds
或者
hbase(main):012:0> get ‘test‘, ‘row2‘, {COLUMN=>‘cf:b‘} hbase(main):012:0> get ‘test‘, ‘row2‘, {COLUMNS=>‘cf:b‘}
备注:COLUMN 和 COLUMNS 是不同的,scan 操作中的 COLUMNS 指定的是表的列族, get操作中的 COLUMN 指定的是特定的列,COLUMNS 的值实质上为“列族:列修饰符”。COLUMN 和 COLUMNS 必须为大写。
8. scan 命令
a. 查看表“test”中的所有数据。
hbase(main):006:0> scan ‘test‘ ROW COLUMN+CELL row1 column=cf:a, timestamp=1381568140492, value=value1 row2 column=cf:b, timestamp=1381568161926, value=value2 row3 column=cf:c, timestamp=1381568176693, value=value3 3 row(s) in 0.0770 seconds
注意:
scan 命令可以指定 startrow,stoprow 来 scan 多个 row。
例如:
scan ‘user_test‘,{COLUMNS =>‘info:username‘,LIMIT =>10, STARTROW => ‘test‘, STOPROW=>‘test2‘}
b.查看表“scores”中列族“course”的所有数据。
hbase(main):012:0> scan ‘scores‘, {COLUMN => ‘grad‘} hbase(main):012:0> scan ‘scores‘, {COLUMN=>‘course:math‘} hbase(main):012:0> scan ‘scores‘, {COLUMNS => ‘course‘} hbase(main):012:0> scan ‘scores‘, {COLUMNS => ‘course‘}
9.count 命令——统计出表中有多少条记录
hbase(main):013:0> count ‘test‘ 3 row(s) in 1.6530 seconds
10. exists 命令——查看表是否存在
hbase(main):014:0> exists ‘test‘ Table test does exist 0 row(s) in 1.1620 seconds
11. incr 命令
给‘test’这个列增加 uid 字段,并使用counter实现递增
连续执行incr以上,COUNTER VALUE 的值会递增,通过get_counter
hbase(main):010:0> incr ‘test‘, ‘row2‘, ‘uid‘, 2 COUNTER VALUE = 2 hbase(main):011:0> incr ‘test‘, ‘row2‘, ‘uid‘, 3 COUNTER VALUE = 5
查看表可以看到:
hbase(main):012:0> scan ‘test‘ ROW COLUMN+CELL row1 column=uid:1, timestamp=1381571789416, value=buym:1 row2 column=uid:, timestamp=1381572436088, value=\x00\x00\x00\x 00\x00\x00\x00\x05 row2 column=uid:2, timestamp=1381571805008, value=buym:20 2 row(s) in 0.0790 seconds
12. delete 命令
删除表“test”中行为“row3”, 列族“cf”中的“c”。
hbase(main):015:0> delete ‘test‘,‘row3‘,‘cf:c‘ 0 row(s) in 0.4640 seconds
13. truncate 命令——将表删除后再重新创建
hbase(main):018:0> truncate ‘test‘ Truncating ‘test‘ table (it may take a while): - Disabling table... - Dropping table... - Creating table... 0 row(s) in 5.6480 seconds
14. disbale、drop 命令
通过“disable”和“drop”命令删除“test”表。
hbase(main):001:0> disable ‘test‘ hbase(main):003:0> drop ‘test‘ 0 row(s) in 3.9310 seconds
原文:http://blog.csdn.net/cqboy1991/article/details/25625037