Node.js在v0.6.0版本下内置了集群功能,作为cluster模块,用于nodejs的多核处理,也比较容易通过脚本实现一个负载均衡的集群。
脚本参考了其他人的材料,建立一个server.js(因为虚拟机只有1核,为模拟多线程,所以采用numCPUs+4)
|
启动服务器可以看到日志
$ node server.js [master] start master... [worker] start worker ...1 [master] listening: worker1,pid:2925, Address:0.0.0.0:3000 [worker] start worker ...3 [master] listening: worker3,pid:2931, Address:0.0.0.0:3000 [worker] start worker ...4 [master] listening: worker4,pid:2932, Address:0.0.0.0:3000 [worker] start worker ...2 [master] listening: worker2,pid:2930, Address:0.0.0.0:3000 worker4 worker2 worker1 worker3 worker4 worker2 worker1
通过curl访问可以看到route到不同的进程
curl 192.168.1.20:3000
worker4,PID:2932
curl 192.168.1.20:3000
worker2,PID:2930
但如何和我们的Express框架结合起来呢,通过npm start实际上是启动了package.json上的script脚本
node ./bin/www
具体打开www文件,发现详细的创建Server的命令,所以需要直接修改这个文件.修改如下:
|
#!/usr/bin/env node /** var cluster = require(‘cluster‘); if (cluster.isMaster) { for (var i = 0; i < numCPUs+4; i++) { cluster.on(‘listening‘, function (worker, address) { } else if (cluster.isWorker) { }).listen(3000);*/ |
启动后能正常访问网页

但在后台的日志中无法显示调用的process的信息所以我们不知道是否真的作到负载均衡了.
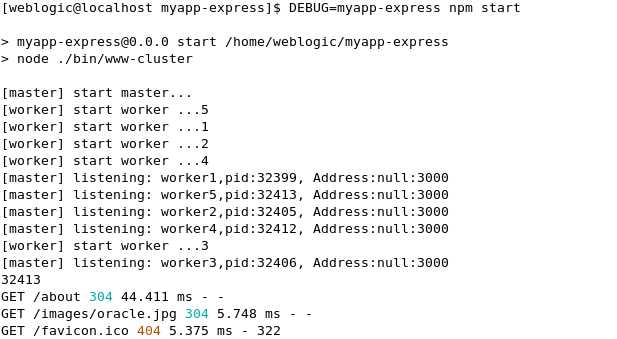
研究了一下,页面还是走到routes目录下的index.js模块,所以在index.js下加入console.log信息,这样基本上访问的时候就知道是走到哪个进程实现调用
|
router.get(‘/about‘,function(req,res) { |
经过实践,同一个firefox的请求会路由到同一个进程pid,关闭在重新打开会路由到另一个pid.
原文:http://www.cnblogs.com/ericnie/p/5958562.html