整体通服的架构图如下:
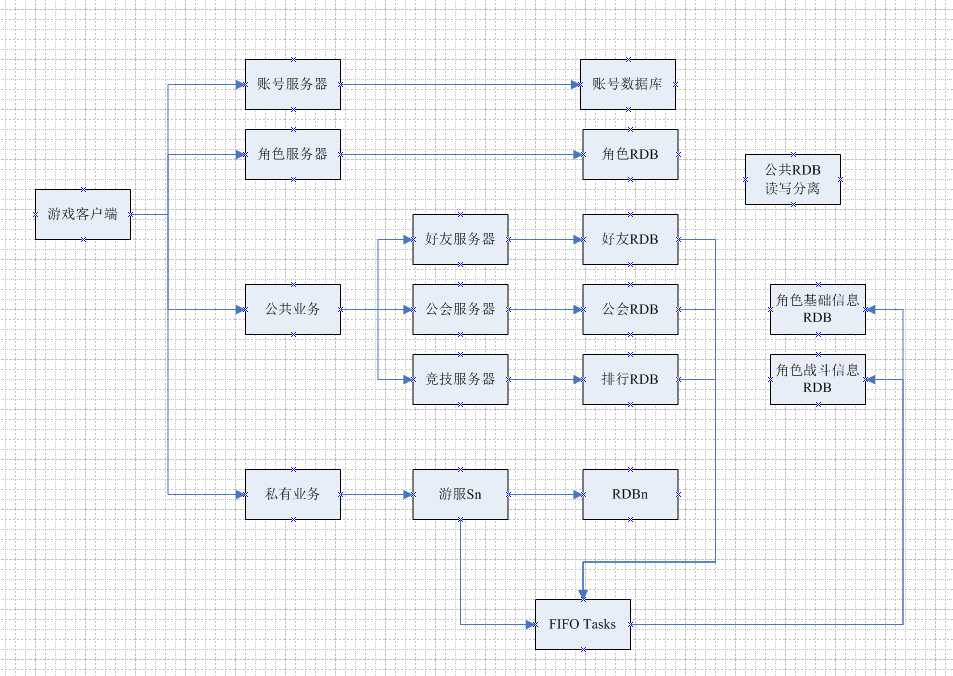
整体思路:
- 尽量将公共的业务逻辑分拆到单个业务服务器;
- 公共业务RDB读写分离,提高IO并发量;
- 单公共业务服务器,是以单机架构还是分布式架构?
- 方法一:采用单物理机构型,部署Scut,在对内存数据进行修改时加互斥锁,而且要考虑多线程操作时,向redis写缓存队列插入写操作的乱序问题;
- Scut 支持 ModifyLock 对数据进行原子操作;
- Scut 的redis写缓存队列是100ms定时批量处理一次,只会取最新数据;
- 方法二:在Scut基础上封装一组分布式套件:支持“redis读取-数据处理-redisWatch-redis写入”,利用redis的Watch机制做多线程同步;
- 优劣分析:
- 方法一的特点是单公共业务服务器对应单RDB实例,响应快、代码简单,瓶颈在单业务服务器的并发量上;
- 方法二的特点是多公共业务服务器对应单RDB实例,可充分挖掘Redis的并发读写能力(肯定比单业务服务器并发强),但单次请求响应更慢、代码更为复杂一些;
- 经典的分布式应用场景应该是:没有交互的、单服务器、单DB结构,通过简单扩展机器数量就可以实现大并发;
- 相比于方法二的横向扩展机器数量,也可以为方法一提升单台服务器的性能,使服务器与reds同时到达性能瓶颈;
使用 Scut 搭建通服架构
原文:http://www.cnblogs.com/Daniel-Liang/p/5966302.html