本文仍然使用MapReduce的经典例子 WordCount来测试eclipse的开发环境。
与大部分教程不同的是,本文使用的hadoop是2.5.2的版本,相较于之前的0.X版本,hadoop 2.X有较大改动
在jar包方面,Hadoop 2.x 版本中 jar 不再集中在一个 hadoop-core*.jar 中,而是分成多个 jar,如使用 Hadoop 2.5.2 运行 WordCount 实例至少需要如下三个 jar:
实际上,通过命令 hadoop classpath 我们可以得到运行 Hadoop 程序所需的全部 classpath 信息。如下图所示:

弄清楚jar包的添加后下面开始编译hadoop程序
编译MapReduce程序常见的有两种方法:
下面介绍一种比较快捷的编译方法
在eclipse中新建Java程序之后,导入相应的jar包,这样在编写MapReduce程序时,就可以直接import jar包。这种方法相较于前面两张方法要快捷。需要导入哪些jar包需根据程序用到的Java类来确定,要注意的是包的路径,因为与0.X有所不同,可以按照上述方法先查看jar包的路径。jar包的导入如下:
右键所创建的Java工程--->Properties,然后选择Java Build Path,再选择Libraries项,点击 Add External JARs 添加所需的jar包
打包JAR文件
编辑好Java程序之后,将MapReduce工程打包成JAR文件,然后发送到hadoop的Master节点上即可运行MapReduce程序。步骤如下:
右键Java工程--->Export--->JAR file。
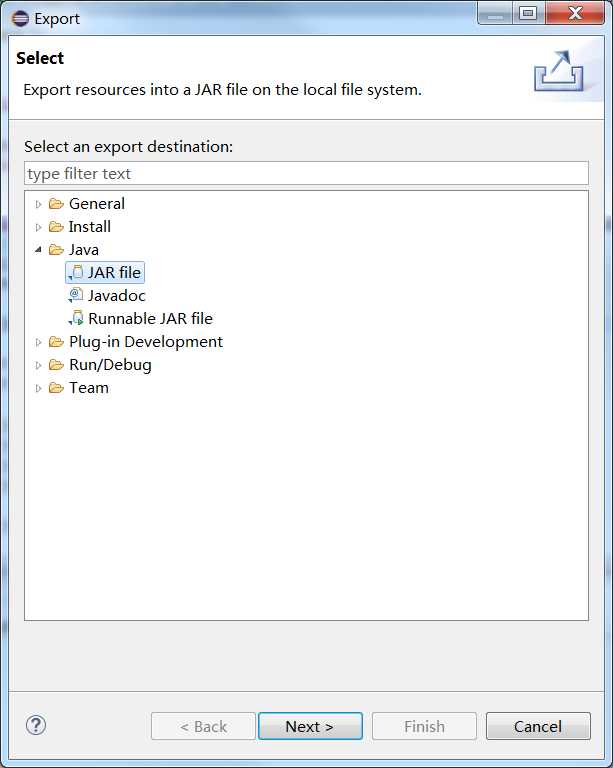
选择JAR file之后,点击 Next按钮,进入JAR文件过滤对话框
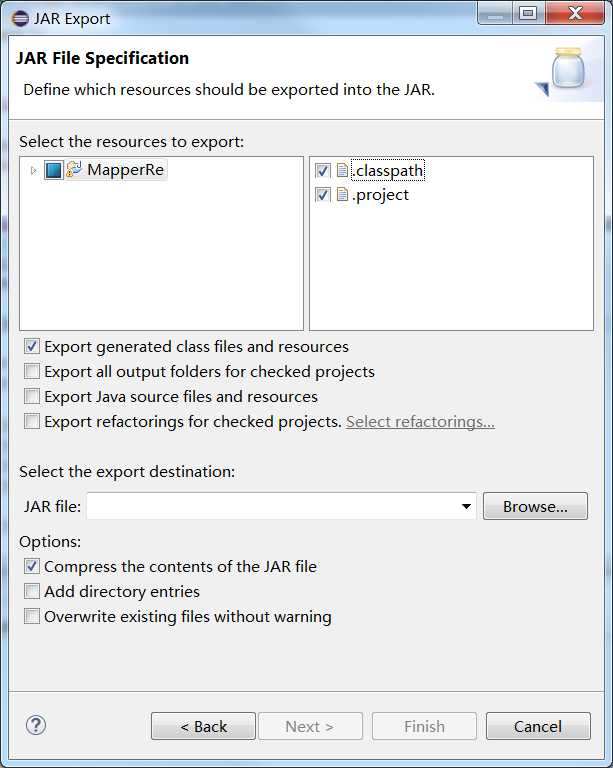
注意:只选择src文件夹就可以,不能把classpath和project文件添加到JAR文件中。
然后在Select the export destination 下的JAR file中选择JAR文件的存放目录与JAR的文件名。
部署运行
1、将生成的JAR包发送到Hadoop集群的Master节点的$HADOOP_HOME目录下面
2、运行MapReduce程序,使用的命令行为:
hadoop jar jar_name.jar package_name.classname /inputfile_dir /outputfile_dir
注意:在运行MapReduce程序之前应确保inputfile_dir存在,outputfile_dir不存在。
在将JAR文件发送到Hadoop集群是的Master节点时,可使用 SSH Secure File Transfer Client 将windows下的JAR文件发送的linux下的Master节点上
使用下面命令查看生成的结果文件
hadoop fs -text /outputfile_dir/part-r-00000
参考:
使用命令行编译打包运行自己的MapReduce程序 Hadoop2.6.0
使用Eclipse编译运行MapReduce程序 Hadoop2.6.0_Ubuntu/CentOS
原文:http://www.cnblogs.com/wujing-hubei/p/6009838.html