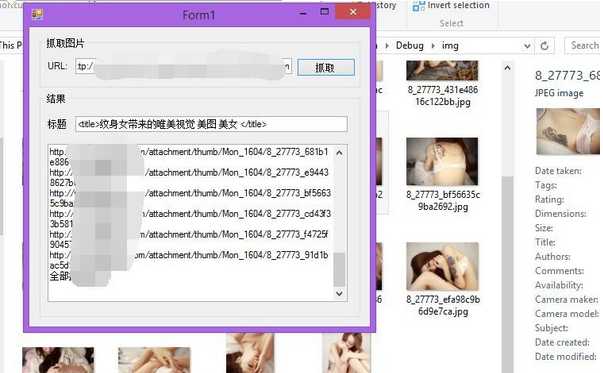
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.IO; using System.Linq; using System.Net; using System.Text; using System.Text.RegularExpressions; using System.Threading; using System.Windows.Forms; namespace ImageCollection { public partial class Form1 : Form { private static string Path = AppDomain.CurrentDomain.BaseDirectory + "img"; public Form1() { InitializeComponent(); } private void btnshuaqu_Click(object sender, EventArgs e) { string url = txturl.Text.Trim(); if (string.IsNullOrEmpty(url)) { MessageBox.Show("请输入URl"); return; } txtimg.AppendText("开始抓取中:\r\n"); Thread th = new Thread(() => ShuaQu(url)) { IsBackground = true }; th.Start(); } private void ShuaQu(string url) { DirectoryInfo di = new DirectoryInfo(Path); if (System.IO.Directory.Exists(Path)) { di.Delete(true); } System.IO.Directory.CreateDirectory(Path); string result = WebHttp.HttpGet(url, null, 3); string[] str = GetHtmlImageUrlList(result); txtimg.Invoke(new Action(() => { txtimg.AppendText("已经获取到数据!"+str.Count() + "\r\n"); })); //建立获取网页标题正则表达式 String regex = @"<title>.+</title>"; //返回网页标题 String title = Regex.Match(result, regex).ToString(); txttitle.Invoke(new Action(() => { txttitle.Text = Regex.Replace(title, @"[\""]+", ""); })); foreach (string s in str) { Uri u = new Uri(s); if (u.Host == "www.xxx.com") { Thread downimg = new Thread(() => Get_img(s)) { IsBackground = true }; downimg.Start(); txtimg.Invoke(new Action(() => { txtimg.AppendText(s + "\r\n"); })); } } txtimg.Invoke(new Action(() => { txtimg.AppendText("全部抓取完成!\r\n"); })); } public void Get_img(string imgpath) { string[] file = imgpath.Split(‘?‘); string name = System.IO.Path.GetFileName(file[0]); WebClient mywebclient = new WebClient(); mywebclient.DownloadFile(imgpath, Path + @"\" + name); //Bitmap img = null; //HttpWebRequest req; //HttpWebResponse res = null; //try //{ // System.Uri httpUrl = new System.Uri(imgpath); // req = (HttpWebRequest)(WebRequest.Create(httpUrl)); // req.Timeout = 180000; //设置超时值10秒 // req.UserAgent = "XXXXX"; // req.Accept = "XXXXXX"; // req.Method = "GET"; // res = (HttpWebResponse)(req.GetResponse()); // img = new Bitmap(res.GetResponseStream());//获取图片流 // img.Save(Path + @"\"+name);//随机名 //} //catch (Exception ex) //{ // string aa = ex.Message; //} //finally //{ // res.Close(); //} } /// <summary> /// 取得HTML中所有图片的 URL。 /// </summary> /// <param name="sHtmlText">HTML代码</param> /// <returns>图片的URL列表</returns> private string[] GetHtmlImageUrlList(string sHtmlText) { // 定义正则表达式用来匹配 img 标签 Regex regImg = new Regex(@"<img\b[^<>]*?\bsrc[\s\t\r\n]*=[\s\t\r\n]*[""‘]?[\s\t\r\n]*(?<imgUrl>[^\s\t\r\n""‘<>]*)[^<>]*?/?[\s\t\r\n]*>", RegexOptions.IgnoreCase); // 搜索匹配的字符串 MatchCollection matches = regImg.Matches(sHtmlText); int i = 0; string[] sUrlList = new string[matches.Count]; // 取得匹配项列表 foreach (Match match in matches) sUrlList[i++] = match.Groups["imgUrl"].Value; return sUrlList; } } }
#region 下载图片到Image public static Image UrlToImage(string url) { WebClient mywebclient = new WebClient(); byte[] Bytes = mywebclient.DownloadData(url); using (MemoryStream ms = new MemoryStream(Bytes)) { Image outputImg = Image.FromStream(ms); return outputImg; } } #endregion
原文:http://www.cnblogs.com/testsec/p/6095851.html