| File names used > 100000 times | 24 |
| File names used between 10001 to 100000 times | 467 |
| File names used between 1001 to 10000 times | 4335 |
| File names used between 101 to 1000 times | 40031 |
| File names used between 10 to 100 times | 403975 |
| File names used between 2 to 9 times | 606579 |
| File names used between 1 times | 4114531 |
| Total file names | 5169942 |

bin/hadoop oiv -i fsimage_0000000015589116819 -o ovils -p NameDistribution Total unique file names 241275868 21 names are used by 2620832 files between 100000-214114 times. Heap savings ~89107574 bytes. 634 names are used by 20434805 files between 10000-99999 times. Heap savings ~703887328 bytes. 7593 names are used by 19447534 files between 1000-9999 times. Heap savings ~734908710 bytes. 49057 names are used by 16697480 files between 100-999 times. Heap savings ~729947272 bytes. 399464 names are used by 7812965 files between 10-99 times. Heap savings ~381085471 bytes. 638085 names are used by 4261035 files between 5-9 times. Heap savings ~223499710 bytes. 628335 names are used by 2513340 files 4 times. Heap savings ~118476621 bytes. 2550503 names are used by 7651509 files 3 times. Heap savings ~319960524 bytes. 3698086 names are used by 7396172 files 2 times. Heap savings ~230703725 bytes. Total saved heap ~3531576935bytes.
通过分析fsimage,可以减少3531576935bytes=3.289g的内存空间,还是很可观的

1 public class ByteArray { 2 private int hash = 0; // 字节数组的hashcode 3 private final byte[] bytes; 4 5 public ByteArray(byte[] bytes) { 6 this.bytes = bytes; 7 } 8 9 public byte[] getBytes() { 10 return bytes; 11 } 12 13 @Override 14 public int hashCode() { 15 if (hash == 0) { 16 hash = Arrays.hashCode(bytes); 17 } 18 return hash; 19 } 20 21 @Override 22 public boolean equals(Object o) { 23 if (!(o instanceof ByteArray)) { 24 return false; 25 } 26 return Arrays.equals(bytes, ((ByteArray)o).bytes); 27 } 28 }
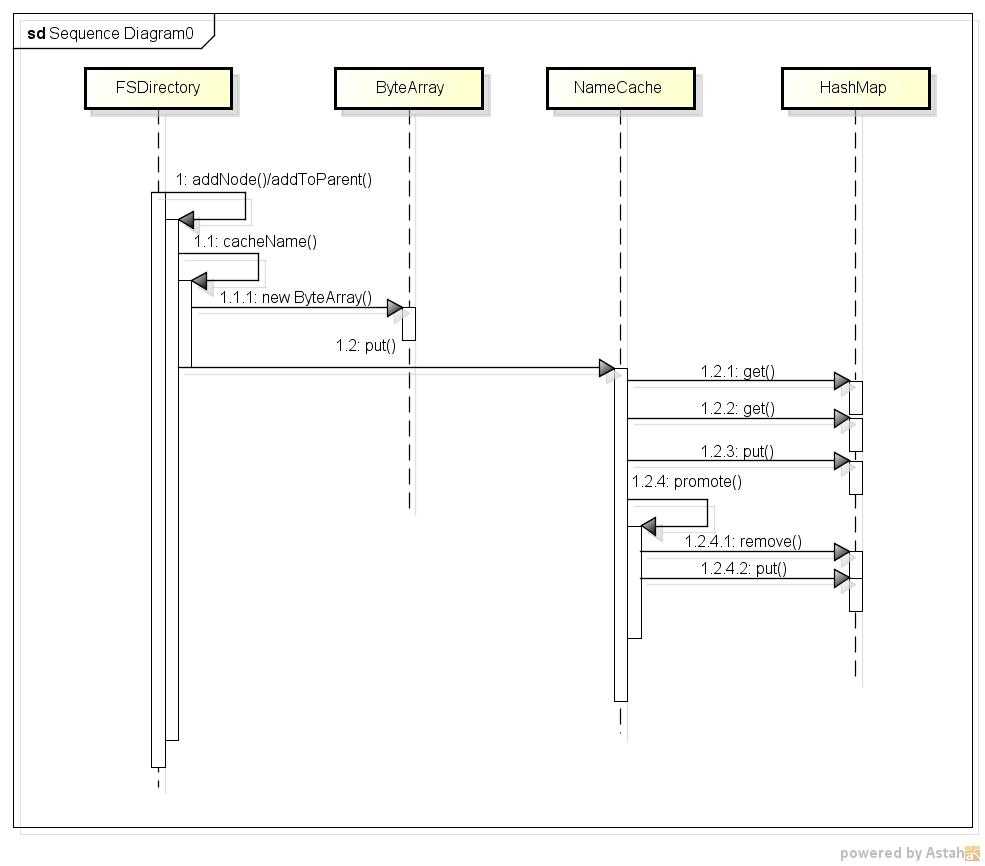
有了缓存项,还要有管理缓存项的缓存类NameCache,NameCache有两个重要的成员cache和transientMap,transientMap用来记录每个文件名被使用的次数,每次addFile时,先把文件名放入transientMap,当文件被重用的次数大于一个阀值时(dfs.namenode.name.cache.threshold配置项),文件名从transientMap 迁移到cache对象中。NameCache中最重要的方法是 K put(final K name),在该方法中,首先检查cache,如果cache中已经缓存了文件名,那么直接返回cache中的文件名;如果cache中没有那么先把文件名放入transientMap,文件的重用次数加1,如果加1后大于阀值,则执行void promote(final K name)方法,该方法中将transientMap中的对应项remove掉,然后放到cache中。该过程的时序图如下所示:
查看大图:大图
需要注意的是HashMap相关方法的调用,并不是每次都调用所有的HashMap的方法。
1. 当cache中已经缓存了文件名,则直接返回,这个过程只调用了一次get方法;
2. 当cache中没有缓存文件名(判断过程调用一次get),并且transientMap中也没有这个文件名(判断过程再一次调用get),则向transientMap中put文件名和使用次数(调用一次put),共计2次get,1次put;
3. 当cache中没有缓存文件名(判断过程调用一次get),并且transientMap中也有这个文件名(判断过程再一次调用get)时,把transientMap中的对应文件名的的重用次数加1,如果文件名重用次数小于阀值不大于阀值则返回,共计调用2次get;
4. 当cache中没有缓存文件名(判断过程调用一次get),并且transientMap中也有这个文件名(判断过程再一次调用get)时,把transientMap中的对应文件名的的重用次数加1,如果文件名重用次数大于等于阀值,则调用promotion,把transientMap中的对应项remove掉,并把该文件名put到cache中,此过程共计调用2次get,1次remove,1次put。
还需要注意的是boolean型成员initialized,代表NameNode是否加载完fsimage了,初值为false,当fsimage加载完并回放了editlog,会调用NameCache的initialized()方法,将其设置为true,代码如下:
1 // <K> name to be added to the cache 2 class NameCache<K> { 3 /** 4 * Class for tracking use count of a name 5 */ 6 private class UseCount { 7 int count; 8 final K value; // Internal value for the name 9 10 UseCount(final K value) { 11 count = 1; 12 this.value = value; 13 } 14 15 void increment() { 16 count++; 17 } 18 19 int get() { 20 return count; 21 } 22 } 23 24 static final Log LOG = LogFactory.getLog(NameCache.class.getName()); 25 26 /** indicates initialization is in progress */ 27 private boolean initialized = false; 28 29 /** names used more than {@code useThreshold} is added to the cache */ 30 private final int useThreshold; 31 32 /** of times a cache look up was successful */ 33 private int lookups = 0; 34 35 /** Cached names */ 36 final HashMap<K, K> cache = new HashMap<K, K>(); 37 38 /** Names and with number of occurrences tracked during initialization */ 39 Map<K, UseCount> transientMap = new HashMap<K, UseCount>(); 40 41 /** 42 * Constructor 43 * @param useThreshold names occurring more than this is promoted to the 44 * cache 45 */ 46 NameCache(int useThreshold) { 47 this.useThreshold = useThreshold; 48 } 49 50 /** 51 * Add a given name to the cache or track use count. 52 * exist. If the name already exists, then the internal value is returned. 53 * 54 * @param name name to be looked up 55 * @return internal value for the name if found; otherwise null 56 */ 57 K put(final K name) { 58 K internal = cache.get(name); 59 if (internal != null) { 60 lookups++; 61 return internal; 62 } 63 64 // Track the usage count only during initialization 65 if (!initialized) { 66 UseCount useCount = transientMap.get(name); 67 if (useCount != null) { 68 useCount.increment(); 69 if (useCount.get() >= useThreshold) { 70 promote(name); 71 } 72 return useCount.value; 73 } 74 useCount = new UseCount(name); 75 transientMap.put(name, useCount); 76 } 77 return null; 78 } 79 80 /** 81 * Lookup count when a lookup for a name returned cached object 82 * @return number of successful lookups 83 */ 84 int getLookupCount() { 85 return lookups; 86 } 87 88 /** 89 * Size of the cache 90 * @return Number of names stored in the cache 91 */ 92 int size() { 93 return cache.size(); 94 } 95 96 /** 97 * Mark the name cache as initialized. The use count is no longer tracked 98 * and the transient map used for initializing the cache is discarded to 99 * save heap space. 100 */ 101 void initialized() { 102 LOG.info("initialized with " + size() + " entries " + lookups + " lookups"); 103 this.initialized = true; 104 transientMap.clear(); 105 transientMap = null; 106 } 107 108 /** Promote a frequently used name to the cache */ 109 private void promote(final K name) { 110 transientMap.remove(name); 111 cache.put(name, name); 112 lookups += useThreshold; 113 } 114 115 public void reset() { 116 initialized = false; 117 cache.clear(); 118 if (transientMap == null) { 119 transientMap = new HashMap<K, UseCount>(); 120 } else { 121 transientMap.clear(); 122 } 123 } 124 }
最后在FSDrectory中添加一个NameCache类型成员,在addNode和addToParent方法中调用cacheName方法,在cacheName方法中用byte[]类型的文件名构造ByteArray实例,并调用nameCache的put方法,代码如下:
1 private <T extends INode> T addNode(String src, T child, 2 long childDiskspace) 3 throws QuotaExceededException, UnresolvedLinkException { 4 byte[][] components = INode.getPathComponents(src); 5 byte[] path = components[components.length-1]; 6 child.setLocalName(path); 7 cacheName(child); 8 INode[] inodes = new INode[components.length]; 9 writeLock(); 10 try { 11 rootDir.getExistingPathINodes(components, inodes, false); 12 return addChild(inodes, inodes.length-1, child, childDiskspace); 13 } finally { 14 writeUnlock(); 15 } 16 } 17 18 19 INodeDirectory addToParent(byte[] src, INodeDirectory parentINode, 20 INode newNode, boolean propagateModTime) throws UnresolvedLinkException { 21 // NOTE: This does not update space counts for parents 22 INodeDirectory newParent = null; 23 writeLock(); 24 try { 25 try { 26 newParent = rootDir.addToParent(src, newNode, parentINode, 27 propagateModTime); 28 cacheName(newNode); 29 } catch (FileNotFoundException e) { 30 return null; 31 } 32 if(newParent == null) 33 return null; 34 if(!newNode.isDirectory() && !newNode.isLink()) { 35 // Add file->block mapping 36 INodeFile newF = (INodeFile)newNode; 37 BlockInfo[] blocks = newF.getBlocks(); 38 for (int i = 0; i < blocks.length; i++) { 39 newF.setBlock(i, getBlockManager().addBlockCollection(blocks[i], newF)); 40 } 41 } 42 } finally { 43 writeUnlock(); 44 } 45 return newParent; 46 } 47 48 void cacheName(INode inode) { 49 // Name is cached only for files 50 if (inode.isDirectory() || inode.isLink()) { 51 return; 52 } 53 ByteArray name = new ByteArray(inode.getLocalNameBytes()); 54 name = nameCache.put(name); 55 if (name != null) { 56 inode.setLocalName(name.getBytes()); 57 } 58 } 59 }
| 优化前 | 优化后 | |
| fsimage加载时间 | 898秒 | 1102秒 |
| Heap Used |
115.252G |
112.148G |
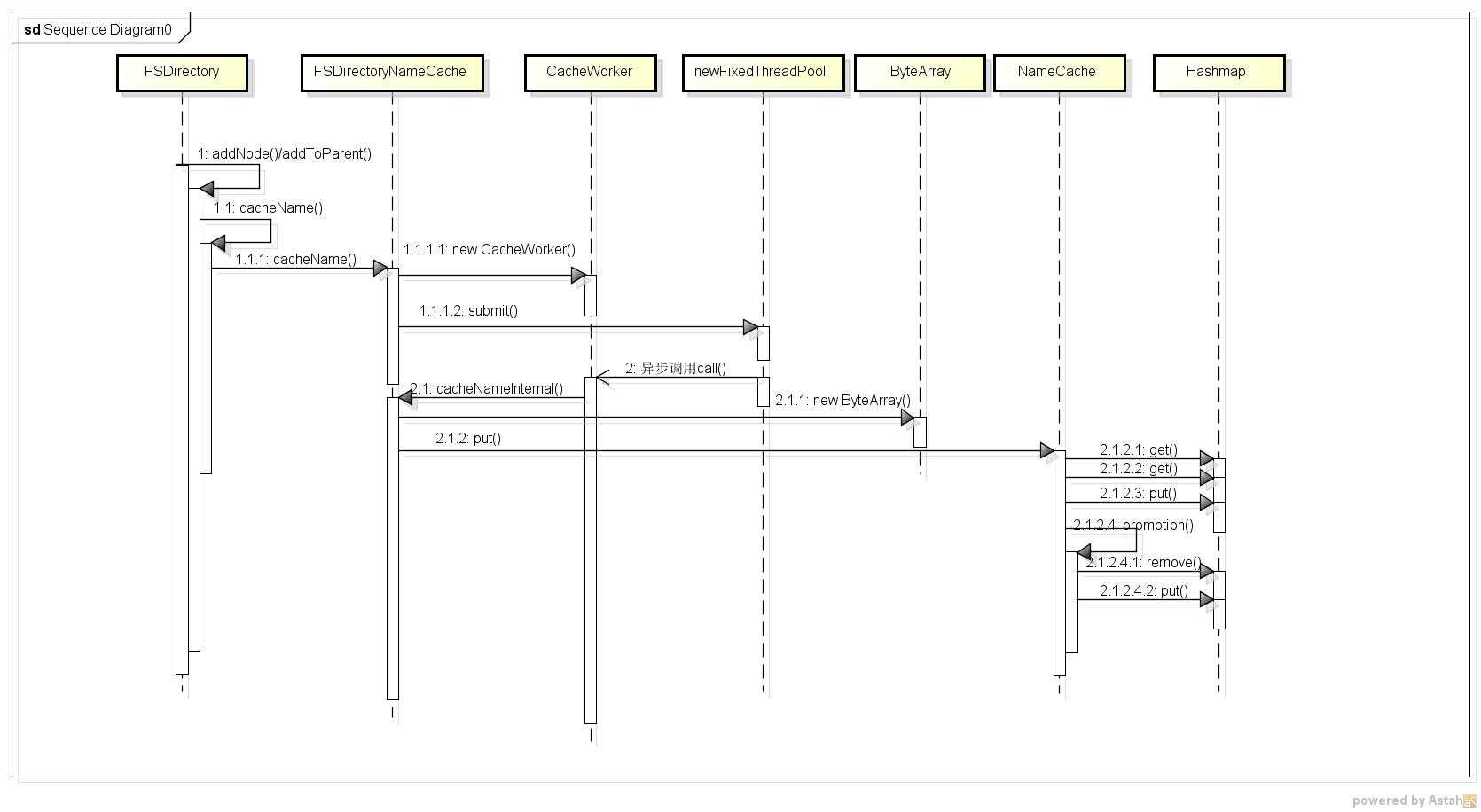
1 public class FSDirectoryNameCache { 2 // buffer this many elements in temporary queue 3 private static final int MAX_QUEUE_SIZE = 10000; 4 5 // actual cache 6 private final NameCache<ByteArray> nameCache; 7 private volatile boolean imageLoaded; 8 9 // initial caching utils 10 private ExecutorService cachingExecutor; 11 private List<Future<Void>> cachingTasks; 12 private List<INode> cachingTempQueue; 13 14 public FSDirectoryNameCache(int threshold) { 15 nameCache = new NameCache<ByteArray>(threshold); 16 imageLoaded = false; 17 18 // executor for processing temporary queue (only 1 thread!!) 19 cachingExecutor = Executors.newFixedThreadPool(1); 20 cachingTempQueue = new ArrayList<INode>(MAX_QUEUE_SIZE); 21 cachingTasks = new ArrayList<Future<Void>>(); 22 } 23 24 /** 25 * Adds cached entry to the map and updates INode 26 */ 27 private void cacheNameInternal(INode inode) { 28 // Name is cached only for files 29 if (inode.isDirectory()) { 30 return; 31 } 32 ByteArray name = new ByteArray(inode.getLocalNameBytes()); 33 name = nameCache.put(name); 34 if (name != null) { 35 inode.setLocalName(name.getBytes()); 36 } 37 } 38 39 void cacheName(INode inode) { 40 if (inode.isDirectory()) { 41 return; 42 } 43 if (this.imageLoaded) { 44 // direct caching 45 cacheNameInternal(inode); 46 return; 47 } 48 49 // otherwise add it to temporary queue 50 cachingTempQueue.add(inode); 51 52 // if queue is too large, submit a task 53 if (cachingTempQueue.size() >= MAX_QUEUE_SIZE) { 54 cachingTasks.add(cachingExecutor 55 .submit(new CacheWorker(cachingTempQueue))); 56 cachingTempQueue = new ArrayList<INode>(MAX_QUEUE_SIZE); 57 } 58 } 59 60 /** 61 * Worker for processing a list of inodes. 62 */ 63 class CacheWorker implements Callable<Void> { 64 private final List<INode> inodesToProcess; 65 66 CacheWorker(List<INode> inodes) { 67 this.inodesToProcess = inodes; 68 } 69 70 @Override 71 public Void call() throws Exception { 72 for (INode inode : inodesToProcess) { 73 cacheNameInternal(inode); 74 } 75 return null; 76 } 77 } 78 79 /** 80 * Inform that from now on all caching is done synchronously. 81 * Cache remaining inodes from the queue. 82 * @throws IOException 83 */ 84 void imageLoaded() throws IOException { 85 if(cachingTasks == null) { 86 return; 87 } 88 for (Future<Void> task : cachingTasks) { 89 try { 90 task.get(); 91 } catch (InterruptedException e) { 92 throw new IOException("FSDirectory cache received interruption"); 93 } catch (ExecutionException e) { 94 throw new IOException(e); 95 } 96 } 97 98 // will not be used after startup 99 this.cachingTasks = null; 100 this.cachingExecutor.shutdownNow(); 101 this.cachingExecutor = null; 102 103 // process remaining inodes 104 for(INode inode : cachingTempQueue) { 105 cacheNameInternal(inode); 106 } 107 this.cachingTempQueue = null; 108 109 this.imageLoaded = true; 110 } 111 112 void initialized() { 113 this.nameCache.initialized(); 114 } 115 116 int size() { 117 return nameCache.size(); 118 } 119 120 int getLookupCount() { 121 return nameCache.getLookupCount(); 122 } 123 124 public void reset() { 125 nameCache.reset(); 126 } 127 }
加载淘宝云梯fsimage,测试结果如下所以:
| 优化前 | 同步cache | 异步cache | |
| fsimage加载时间 | 898秒 | 1102秒 | 956秒 |
| Heap Used | 115.252G | 112.148G | 112.147G |
原文:http://www.cnblogs.com/yangjiandan/p/3535125.html
