function (file, ignoreBlanks = TRUE, handlers = NULL, replaceEntities = FALSE, asText = FALSE, trim = TRUE, validate = FALSE, getDTD = TRUE, isURL = FALSE, asTree = FALSE, addAttributeNamespaces = FALSE, useInternalNodes = FALSE, isSchema = FALSE, fullNamespaceInfo = FALSE, encoding = character(), useDotNames = length(grep("^\\.", names(handlers)))>0, xinclude = TRUE, addFinalizer = TRUE, error = htmlErrorHandler, isHTML = TRUE, options = integer(), parentFirst = FALSE){#asText=T则file作为XML文本处理 isMissingAsText = missing(asText)#地址大于一个时要中止程序并抛出异常if(length(file)>1){ file = paste(file, collapse ="\n")if(!missing(asText)&&!asText) stop(structure(list(message ="multiple URLs passed to xmlTreeParse. If this is the content of the file, specify asText = TRUE"),class= c("MultipleURLError","XMLParserError","simpleError","error","condition"))) asText = TRUE}#当isURL非空时且是XML的时候,才修改URL为数值型#比如这里isURL=1if(missing(isURL)&&!asText) isURL <- length(grep("^(http|ftp|file)://", file, useBytes = TRUE, perl = TRUE))#isHTML 默认为 TRUEif(isHTML){ validate = FALSE getDTD = FALSE isSchema = FALSE docClass ="HTMLInternalDocument"}else docClass = character()#checkHandlerNames返回的是一个逻辑值,其作用是 checkHandlerNames(handlers,"DOM")if(missing(fullNamespaceInfo)&& inherits(handlers,"RequiresNamespaceInfo")) fullNamespaceInfo = TRUE oldValidate = xmlValidity() xmlValidity(validate) on.exit(xmlValidity(oldValidate))if(!asText && isURL == FALSE){if(file.exists(file)== FALSE)if(!missing(asText)&& asText == FALSE){ e = simpleError(paste("File", file,"does not exist"))class(e)= c("FileNotFound",class(e)) stop(e)}else asText <- TRUE}if(asText && length(file)>1) file = paste(file, collapse ="\n") old = setEntitySubstitution(replaceEntities) on.exit(setEntitySubstitution(old), add = TRUE)if(asText && length(grep(sprintf("^%s?\\s*<",BOMRegExp), file, perl = TRUE, useBytes = TRUE))==0){if(!isHTML ||(isMissingAsText &&!inherits(file,"AsIs"))){ e = simpleError(paste("XML content does not seem to be XML:", sQuote(file)))class(e)= c("XMLInputError",class(e))(if(isHTML) warningelse stop)(e)}}if(!is.logical(xinclude)){ xinclude =as.logical(xinclude)}if(!asText &&!isURL) file = path.expand(as.character(file))if(useInternalNodes && trim){ prevBlanks =.Call("RS_XML_setKeepBlanksDefault",0L, PACKAGE ="XML") on.exit(.Call("RS_XML_setKeepBlanksDefault", prevBlanks, PACKAGE ="XML"), add = TRUE)}.oldErrorHandler = setXMLErrorHandler(error) on.exit(.Call("RS_XML_setStructuredErrorHandler",.oldErrorHandler, PACKAGE ="XML"), add = TRUE)if(length(options)) options = sum(options) ans <-.Call("RS_XML_ParseTree",as.character(file), handlers,as.logical(ignoreBlanks),as.logical(replaceEntities),as.logical(asText),as.logical(trim),as.logical(validate),as.logical(getDTD),as.logical(isURL),as.logical(addAttributeNamespaces),as.logical(useInternalNodes),as.logical(isHTML),as.logical(isSchema),as.logical(fullNamespaceInfo),as.character(encoding),as.logical(useDotNames), xinclude, error, addFinalizer,as.integer(options),as.logical(parentFirst), PACKAGE ="XML")if(!missing(handlers)&& length(handlers)&&!as.logical(asTree))return(handlers)if(!isSchema && length(class(ans)))class(ans)= c(docClass, oldClass(class(ans)))if(inherits(ans,"XMLInternalDocument")) addDocFinalizer(ans, addFinalizer)elseif(!getDTD &&!isSchema){class(ans)= oldClass("XMLDocumentContent")} ans}<environment: namespace:XML>#test#导包library(XML)#链接url <-"http://www.r-datacollection.com/materials/html/fortunes.html"#handers函数h2 <- list( startElement = function(node,...){ name <- xmlName(node)if(name %in% c("div","title")){NULL}else{node}}, comment = function(node){NULL})#正式开始,函数参数file=urlignoreBlanks = TRUEhandlers = h2replaceEntities = FALSEasText = FALSEtrim = TRUEvalidate = FALSEgetDTD = TRUEisURL = FALSEasTree = TRUEaddAttributeNamespaces = FALSEuseInternalNodes = FALSEisSchema = FALSEfullNamespaceInfo = FALSE encoding = character()useDotNames = length(grep("^\\.", names(handlers)))>0xinclude = TRUEaddFinalizer = TRUEerror = XML:::htmlErrorHandlerisHTML = TRUEoptions = integer()parentFirst = FALSE#函数体部分#asText参数没有传入#我们将其从missing(asText)改为TRUE isMissingAsText = TRUE#file的长度是否大于1,大于1如果asText未传入则要报错:传入了多个URL#不大于1,则跳过if(length(file)>1){ file = paste(file, collapse ="\n")if(!missing(asText)&&!asText) stop(structure(list(message ="multiple URLs passed to xmlTreeParse. If this is the content of the file, specify asText = TRUE"),class= c("MultipleURLError","XMLParserError","simpleError","error","condition"))) asText = TRUE}# 本来是if (missing(isURL) && !asText)# 我们修改为if (TURE && !asText)#isURL参数没有传递且asText参数为假才执行if(TRUE &&!asText) isURL <- length(grep("^(http|ftp|file)://", file, useBytes = TRUE, perl = TRUE))#只要有http|ftp|file中的一个协议开头,比如http://,就是URL了。# 此时isURL=1#是否为HTML,是的if(isHTML){ validate = FALSE getDTD = FALSE #从默认值T改为了F isSchema = FALSE docClass ="HTMLInternalDocument"}else{docClass = character()}#否则创建空的# class(docClass)#返回TRUE通过检验了,否则函数会中止并抛出异常 XML:::checkHandlerNames(handlers,"DOM")#fullNamespaceInfo参数whether to provide the namespace URI and prefix on each node#其实就是是否在节点面前带上URI信息#fullNamespaceInfo为空且handlers含有该属性,才执行这一步#missing(fullNamespaceInfo)被替换为TRUE#handlers并没有RequiresNamespaceInfo属性,所以不执行if( TRUE && inherits(handlers,"RequiresNamespaceInfo")) fullNamespaceInfo = TRUE#以下两行的结果都是integer(0)#奇妙~,先保存原有的配置 oldValidate = XML:::xmlValidity()#当前的配置 XML:::xmlValidity(validate)#还原原来的配置 on.exit(XML:::xmlValidity(oldValidate))#asText为假,且isURL是假的#结果为TFALSE,我们不必管他if(!asText && isURL == FALSE){if(file.exists(file)== FALSE)#如果本地文件不存在if(!missing(asText)&& asText == FALSE){#抛出异常,文件不存在 e = simpleError(paste("File", file,"does not exist"))class(e)= c("FileNotFound",class(e)) stop(e)}else asText <- TRUE}#此时asText是FALSE,这个跟我们无关if(asText && length(file)>1) file = paste(file, collapse ="\n")#replaceEntities的默认值是FALSE old = XML:::setEntitySubstitution(replaceEntities)#old的值是FALSE on.exit(XML:::setEntitySubstitution(old), add = TRUE)#BOMRegExp是一个内置的常量吧#看名字应该是基于BOM的正则表达式#因为是FALSE,所以我们也先不去管它if(asText && length(grep( sprintf("^%s?\\s*<", XML:::BOMRegExp), file, perl = TRUE, useBytes = TRUE))==0){if(!isHTML ||(isMissingAsText &&!inherits(file,"AsIs"))){ e = simpleError(paste("XML content does not seem to be XML:", sQuote(file)))class(e)= c("XMLInputError",class(e))(if(isHTML) warningelse stop)(e)}}#xinclude默认值是TRUE#以下三个if都是F,所以不管了if(!is.logical(xinclude)){ xinclude =as.logical(xinclude)}if(!asText &&!isURL) file = path.expand(as.character(file))if(useInternalNodes && trim){ prevBlanks =.Call("RS_XML_setKeepBlanksDefault",0L, PACKAGE ="XML") on.exit(.Call("RS_XML_setKeepBlanksDefault", prevBlanks, PACKAGE ="XML"), add = TRUE)}.oldErrorHandler = XML:::setXMLErrorHandler(error)#所以,这种点开头的命名是什么鬼?# class(.oldErrorHandler)# [1] "list" on.exit(.Call("RS_XML_setStructuredErrorHandler",.oldErrorHandler, PACKAGE ="XML"), add = TRUE)# length(options)是0,所以不执行if(length(options)) options = sum(options)#调用一个叫做RS_XML_ParseTree的函数 getAnywhere("RS_XML_ParseTree") ans <-.Call("RS_XML_ParseTree",as.character(file), handlers,as.logical(ignoreBlanks),as.logical(replaceEntities),as.logical(asText),as.logical(trim),as.logical(validate),as.logical(getDTD),as.logical(isURL),as.logical(addAttributeNamespaces),as.logical(useInternalNodes),as.logical(isHTML),as.logical(isSchema),as.logical(fullNamespaceInfo),as.character(encoding),as.logical(useDotNames), xinclude, error, addFinalizer,as.integer(options),as.logical(parentFirst), PACKAGE ="XML")print(ans)print("-------我是可爱的分割线------------------")#这里的missing(handlers)我们就不改了哈#毕竟只要有默认值,他都觉得是TRUE#和我们的确传递了处理函数的效果TRUE是一样的if(!missing(handlers)&& length(handlers)&&!as.logical(asTree))return("呵呵")if(!isSchema && length(class(ans)))class(ans)= c(docClass, oldClass(class(ans)))if(inherits(ans,"XMLInternalDocument")){ addDocFinalizer(ans, addFinalizer)}elseif(!getDTD &&!isSchema){print("看我的类型")print(class(ans))class(ans)= oldClass("XMLDocumentContent")print(class(ans))}print("看条件判断的逻辑值")print("1")print(!missing(handlers)&& length(handlers)&&!as.logical(asTree))print("2")print(!isSchema && length(class(ans)))print("3")print(inherits(ans,"XMLInternalDocument"))print("4")print(!getDTD &&!isSchema)print(class(ans)) ans
#例子1testMissing<-function(a=TRUE,b=FALSE){if(missing(b))return("b is missing")else"b is here "+b}testMissing(F)# [1] "b is missing"#例子2if(missing(b))return("b is missing")# Error in missing(b) : ‘missing‘ can only be used for arguments#例子3b=NULLif(missing(b))return("b is missing")#没有输出if(isHTML){ validate = FALSE getDTD = FALSE #从默认值T改为了F isSchema = FALSE docClass ="HTMLInternalDocument" }else{docClass = character()}#否则创建空的}else docClass = character()function(){if(isHTML){ validate = FALSE getDTD = FALSE #从默认值T改为了F isSchema = FALSE docClass ="HTMLInternalDocument"}else docClass = character()#否则创建空的}function (handlers, id ="SAX") { if(is.null(handlers)) #为空,则返回TRUE return(TRUE) ids = names(handlers) #取出handlers中的函数名 i = match(ids,GeneralHandlerNames) #匹配,返回逻辑值向量 prob = any(!is.na(i))#任一个回空才是TRUE if(prob){ warning("future versions of the XML package will require names of general handler functions to be prefixed by a . to distinguish them from handlers for nodes with those names. This _may_ affect the ", paste(names(handlers)[!is.na(i)], collapse =", ")) } #任意一个handler中的函数不是函数类型,则抛出异常 if(any(w <-!sapply(handlers,is.function))) warning("some handlers are not functions: ", paste(names(handlers[w]), collapse =", ")) #返回TRUE,后续代码继续运行 !prob}<environment: namespace:XML>> XML:::GeneralHandlerNames$SAX[1]"text" "startElement" [3]"endElement" "comment" [5]"startDocument" "endDocument" [7]"processingInstruction""entityDeclaration" [9]"externalEntity" $DOM[1]"text" "startElement" [3]"comment" "entity" [5]"cdata" "processingInstruction"> h2 <- list(+ startElement = function(node,...){+ name <- xmlName(node)+ if(name %in% c("div","title")){NULL}else{node}+ },+ comment = function(node){NULL}+)> handlers<-h2> ids = names(handlers) > ids[1]"startElement""comment" > i = match(ids, XML:::GeneralHandlerNames)> i[1] NA NA>?matchstarting httpd help server ... done>!is.na(i)#如果i中有NA,则返回F,没有NA则返回T[1] FALSE FALSE> prob = any(!is.na(i))#当i中的任意一个元素都不是NA的时候,prob才返回T> prob[1] FALSE> testMatch<-c("a","c")> testSet <- c(‘a‘,‘b‘,‘c‘)> match(testMatch,testSet)[1]13x <-10class(x)# "numeric"oldClass(x)# NULL#看了下文档,我个人觉得oldClass是S语言的余毒啊!!!inherits(x,"a")#FALSE class(x)<- c("a","b")# x# [1] 10# attr(,"class")# [1] "a" "b"#即,x为10这个变量被赋予了两个class,分别名为"a"和 "b"inherits(x,"a")#TRUEinherits(x,"a", TRUE)# 1inherits(x, c("a","b","c"), TRUE)# 1 2 0 #以下两行的结果都是integer(0) #奇妙~,先保存原有的配置 oldValidate = XML:::xmlValidity() #使用当前的配置 XML:::xmlValidity(validate) #还原 on.exit(XML:::xmlValidity(oldValidate))> XML:::xmlValidity()integer(0)> getAnywhere(xmlValidity)A single object matching ‘xmlValidity’ was foundIt was found in the following places namespace:XMLwith valuefunction (val = integer(0)) { .Call("RS_XML_getDefaultValiditySetting",as.integer(val), PACKAGE ="XML")}<environment: namespace:XML>> opar <- par(bg=‘lightblue‘)> on.exit(par(opar))> plot(c(1,2,3),c(4,5,6))#蓝色背景> plot(c(1,2,3,4,5),runif(5))#蓝色背景#此时关闭绘图窗口> plot(c(1,2,3,4,5),rnorm(5))#白色背景plot_with_big_margins <- function(...){ old_pars <- par(mar = c(10,9,9,7)) on.exit(par(old_pars)) plot(...)}plot_with_big_margins(with(cars, speed, dist))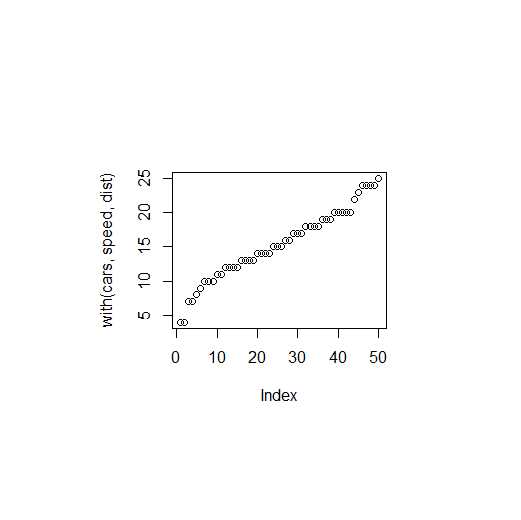
#不关闭图像窗口,此时再运行如下语句plot(c(1,2,3),c(4,5,6))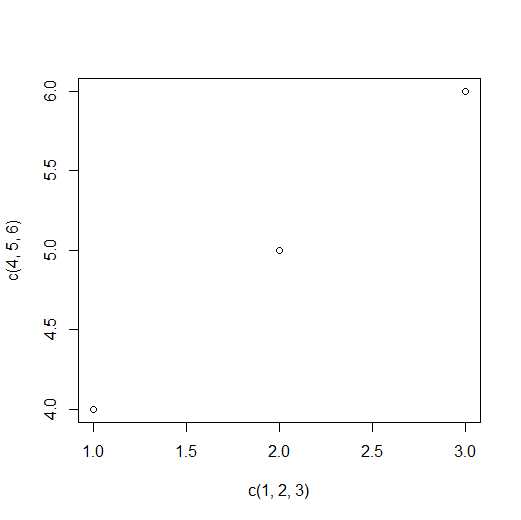
对比 plot_with_big_margins <- function(...){ par(mar = c(10,9,9,7)) plot(...)}plot_with_big_margins(with(cars, speed, dist)) 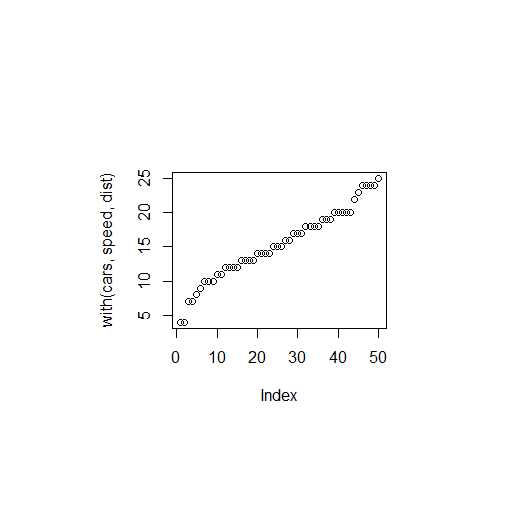
#不关闭图像窗口,此时再运行:plot(c(1,2,3),c(4,5,6)) 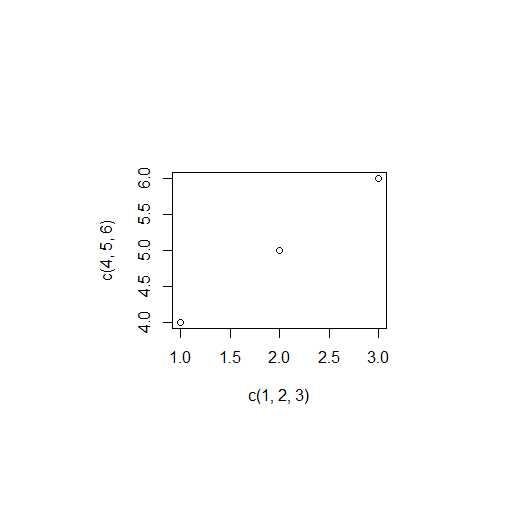
old_pars <- par(mar = c(10,9,9,7)) on.exit(par(old_pars))> old_pars <- par(mar = c(10,9,9,7))> old_pars$mar [1]5.14.14.12.1> op <- options(stringsAsFactors = FALSE)> op$stringsAsFactors[1] TRUEpar() #得到的mar是5.14.14.12.1plot_with_big_margins <- function(...){ old_pars <- par(mar = c(10,9,9,7)) #原参数被保存,新参数设置生效 print(par()) #得到的mar是10,9,9,7 on.exit(par(old_pars)) #参数被还原为原来的参数 plot(...)}plot_with_big_margins(with(cars, speed, dist)) par() #得到的mar是5.14.14.12.1 my_plot <- function(){ with(cars, plot(speed, dist))}save_base_plot <- function(plot_fn, file){ png(file) on.exit(dev.off()) plot_fn()}save_base_plot(my_plot,"testcars.png") #replaceEntities的默认值是FALSE old = XML:::setEntitySubstitution(replaceEntities) #old的值是FALSE on.exit(XML:::setEntitySubstitution(old), add = TRUE)> XML:::setEntitySubstitutionfunction (val) .Call("RS_XML_SubstituteEntitiesDefault",as.logical(val), PACKAGE ="XML")<environment: namespace:XML>.oldErrorHandler = XML:::setXMLErrorHandler(error) #所以,这种点开头的命名是什么鬼? # class(.oldErrorHandler) # [1] "list" on.exit(.Call("RS_XML_setStructuredErrorHandler",.oldErrorHandler, PACKAGE ="XML"), add = TRUE) > XML:::htmlErrorHandlerfunction (msg, code, domain, line, col, level, filename,class="XMLError") { e = makeXMLError(msg, code, domain, line, col, level, filename, class) dom = names(e$domain) class(e)= c(names(e$code), sprintf("%s_Error", gsub("_FROM_", "_", dom)),class(e)) if(e$code == xmlParserErrors["XML_IO_LOAD_ERROR"]) stop(e)}<environment: namespace:XML> > XML:::setXMLErrorHandlerfunction (fun) { prev =.Call("RS_XML_getStructuredErrorHandler", PACKAGE ="XML") sym = getNativeSymbolInfo("R_xmlStructuredErrorHandler", "XML")$address .Call("RS_XML_setStructuredErrorHandler", list(fun, sym), PACKAGE ="XML") prev}<environment: namespace:XML>> getAnywhere(BOMRegExp)A single object matching ‘BOMRegExp’ was foundIt was found in the following places namespace:XMLwith value[1]"(\\xEF\\xBB\\xBF|\\xFE\\xFF|\\xFF\\xFE)"
untar(download.packages(pkgs ="XML", destdir =".", type ="source")[,2])
R自动数据收集第二章HTML笔记2(主要关于htmlTreeParse函数)
原文:http://www.cnblogs.com/xuanlvshu/p/6238408.html