之前学习过一些分布式计算的知识,但实际应用还是停留在hadoop,Map Reduce的阶段。最近研究了关于Spark的一些内容,对分布式计算中的流式处理以及实时处理有了一些全新的理解。本文介绍集中典型的框架。
Spark是最近炒得比较热的一种分布式计算框架,大有全面取代hadoop的势头。其实,Spark最初也不是完全针对流数据处理或者实时处理而设计的。Spark的主要特征是,在分布式文件系统(典型的是HDFS)和计算控制之前提供了一层数据结构RDD(弹性分布式数据集)。RDD本身就是在每个节点server里的内存中,因此,当进行分布式计算时,使用的数据存在内存之中,而不必频繁地往本地硬盘里存取数据。因此,Spark在处理迭代式计算上效果显著,也继承了hadoop批处理的优越性。
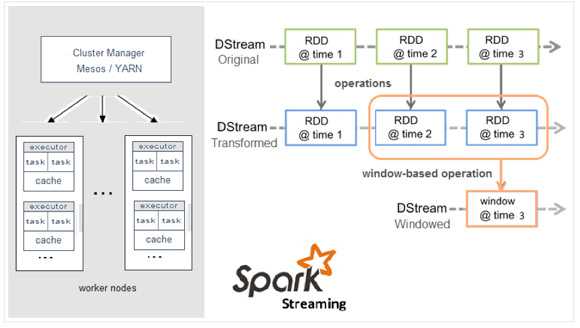
Spark在实时数据处理和流处理的支持其实后来Spark Streaming模块对Spark的一个扩展。虽然说是流处理后者接近实时的处理,但实质上是在处理前按时间间隔(间隔越小,越接近实时)预先将其切分为一段一段,从而进行批处理作业。Spark针对持续性数据流的抽象称为DStream(DiscretizedStream),一个DStream是一个微批处理(micro-batching)的RDD。RDD能够以两种方式并行运作,分别是任意函数和滑动窗口数据的转换。因此,Spark可以说只能是一种近似实时数据处理。
Storm是目前主流的流式处理和实时处理的分布式计算框架之一。Storm的流式处理计算模式保证了任务能够只进行一次初始化,就能够持续计算,同时使用了ZeroMQ(Netty)作为底层消息队列,有效地提高了整体架构的数据处理效率,避免了Hadoop的瓶颈。Storm的适用场景:
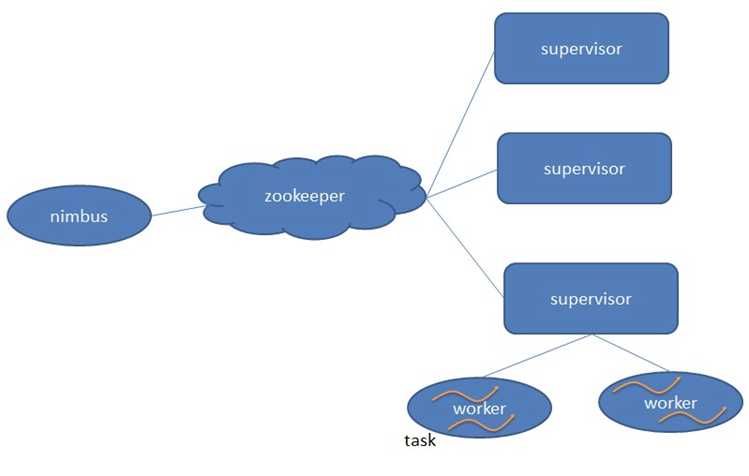
在Storm中,先要设计一个用于实时计算的图状结构,我们称之为拓扑(topology)。这个拓扑将会被提交给集群,由集群中的主控节点(master node)分发代码,将任务分配给工作节点(worker node)执行。一个拓扑中包括spout和bolt两种角色,其中spout发送消息,负责将数据流以tuple元组的形式发送出去;而bolt则负责转换这些数据流,在bolt中可以完成计算、过滤等操作,bolt自身也可以随机将数据发送给其他bolt。由spout发射出的tuple是不可变数组,对应着固定的键值对。
和Hadoop相比,Storm能够真正做到响应快、实时处理、使流数据处理。但是当每次接收到的流数据过多过大时,Storm的优越性能可能便无法持续保持。
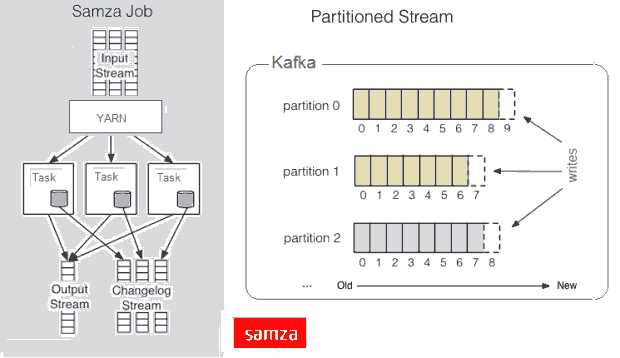
Samza的原理是将数据流当作接收到的消息进行处理。因此,Samza的流初始元素并不是一个tuple或一个DStream,而是一个消息,同时流被划分到分区,每个分区是一个只读消息的排序的序列,每个消息有一个唯一的ID(offset),系统也支持批处理,从同样的流分区以顺序消费几个消息。Samza主要是依赖于Hadoop的Yarn和Apache Kafka模块,但是它的Execution & Streaming模块是可设置的。Samza是分布式计算中流处理、实时处理的另一种选择。
总体上来说,Spark,Storm以及Samza都是比较适合于分布式计算流处理、实时处理场景的。当然它们之间也各有利弊,具体选择哪一种框架还是需要根据实际需求。比如,如果需要高速的事件处理,并且能够进行增量计算,那么Storm是首选;如果是图操作、机器学习或者SQL等,Spark的高可扩展性更方便进行开发;而计算任务中有大量的状态,比如每个分区存储了极大的数据,那么Samza协同存储的架构以及同一机器处理的机制能够在不塞满内存的情况下,有效地进行状态处理。
本篇文章参考了网上的一些相关博客,并加上了一些自己的理解,仅作交流学习用。
原文:http://www.cnblogs.com/jingyzzz/p/6239408.html