链表结点类型定义:

1 class Node { 2 public: 3 int data = 0; 4 Node *next = nullptr; 5 6 Node(int d) { 7 data = d; 8 } 9 };
快行指针(runner)技巧:
同时使用两个指针来迭代访问链表,其中一个比另一个超前一些。快指针比慢指针先行几步或者快指针与慢指针的速度呈一定的关系。
dummy元素技巧:
在链表头部添加一个哑结点,通常可以简化首部或尾部的特殊情况的处理。
2.1 编写代码,移除未排序链表中的重复结点。
进阶:如果不得使用临时缓冲区,该怎么解决?
解答:如果可以使用临时缓冲区,那么可以建立一个Hash表,保存已出现的结点内容,遍历过程中如果发现重复元素,就删除该结点。
1 void deleteDups(Node *head) { 2 if (head == nullptr) return; 3 unordered_set<int> table; 4 Node *f = head, *p = head->next; 5 table.insert(head->data); 6 while (p != nullptr) { 7 if (table.find(p->data) == table.end()) { 8 table.insert(p->data); 9 f = p; 10 p = p->next; 11 } 12 else { 13 f->next = p->next; 14 delete p; 15 p = f->next; 16 } 17 } 18 }
如果不允许使用额外的数组,则暴力解决..
1 void deleteDups(Node *head) { 2 if (head == nullptr || head->next == nullptr) return; 3 Node *f = head, *p = head->next; 4 while (p != nullptr) { 5 Node *pc = head; 6 while (pc != p) { 7 if (pc->data == p->data) { 8 f->next = p->next; 9 delete p; 10 p = f; 11 break; 12 } else { 13 pc = pc->next; 14 } 15 } 16 p = p->next; 17 } 18 }
2.2 实现一个算法,找出单向链表中倒数第k个结点。
解答:利用快行指针技巧,让快指针先走k步,然后同步地挪动快慢指针,快指针到达链表尾时,慢指针恰好指向倒数第k个结点。(剑指offer上也有这道题)
1 Node * kthToLast(Node *head, int k) { 2 if (k < 0) return nullptr; 3 Node *p1 = head, *p2 = head; 4 for (int i = 0; i < k - 1; ++i) { 5 if (p2 == nullptr || p2->next == nullptr) 6 return nullptr; 7 p2 = p2->next; 8 } 9 while (p2->next != nullptr) { 10 p1 = p1->next; 11 p2 = p2->next; 12 } 13 return p1; 14 }
2.3 实现一个算法,删除单链表中的某个结点,假定你只能访问该结点。
解答:本题的意思是我们不知道链表的首结点位置。那么删除该结点的方法是:将其后继结点的值赋给该节点,然后删除后继结点。有一个问题是:如果给定的结点指针是空指针或是最后一个指针时会出错,我们可以通过程序的返回值来指明错误或抛出异常。
1 bool deleteNode(Node *node) { 2 if (node == nullptr || node->next == nullptr) { 3 return false; 4 } 5 Node *next = node->next; 6 node->data = next->data; 7 node->next = next->next; 8 delete next; 9 return true; 10 }
2.4 编写代码,以给定值x为基准将链表分割成两部分,所有小于x的结点排在大于或等于x的结点之间。
解答:维护两个链表,分别保存大于x和小于x的元素,然后将两个链表连接起来。尾插法可以保持元素的相对位置。加入dummy结点可以简化代码。Leetcode上也有这道题。
1 Node * partition(Node *head, int x) { 2 Node dummy_left(-1), dummy_right(-1); 3 Node *pl = &dummy_left, *pr = &dummy_right; 4 for (Node * p = head; p != nullptr; p = p->next) { 5 if (p->data < x) { 6 pl->next = p; 7 pl = pl->next; 8 } else { 9 pr->next = p; 10 pr = pr->next; 11 } 12 } 13 pl->next = dummy_right.next; 14 pr->next = nullptr; 15 return dummy_left.next; 16 }
2.5 给定两个用链表表示的整数,每个结点包含一个数位。这些数位是反向存放的,也就是个位排在链表首部。编写函数对这两个整数求和,并用链表形式返回结果。
进阶:假设这些数位是正向存放的,请再做一遍。
反向表示举例:(Leetcode)
7->1->6
+
5->9->2->1
___________________
2->1->9->1
1 Node * addList(Node *l1, Node *l2) { 2 Node dummy(-1); 3 Node *p = &dummy; 4 int carry = 0; //进位 5 while (l1 != nullptr || l2 != nullptr) { 6 int v = 0; 7 if (l1 != nullptr) { 8 v += l1->data; 9 l1 = l1->next; 10 } 11 if (l2 != nullptr) { 12 v += l2->data; 13 l2 = l2->next; 14 } 15 v += carry; 16 carry = v / 10; 17 v = v % 10; 18 Node *node = new Node(v); 19 p->next = node; 20 p = p->next; 21 } 22 if (carry > 0) { 23 Node * node = new Node(carry); 24 p->next = node; 25 p = p->next; 26 } 27 return dummy.next; 28 }
进阶问题:可以借助一个栈实现,或者先通过填零把两个链表的长度变为一致,然后递归求解。以下是后一种思路的代码:(partialSum是一个包裹类,把一个Node指针和一个表示进位的int捆绑在一起,方便函数返回)。把独立的处理逻辑分列到不同的函数中,使代码思路清晰,可读性强。
1 class partialSum { 2 public: 3 Node * node = nullptr; 4 int carry = 0; 5 }; 6 7 int length(Node *l) { 8 int len = 0; 9 while (l != nullptr) { 10 ++len; 11 l = l ->next; 12 } 13 return len; 14 } 15 16 Node * padList(Node *l, int n) { 17 //填零 18 Node * new_head = l; 19 for (int i = 0; i < n; ++i) { 20 Node *node = new Node(0); 21 node->next = l; 22 new_head = node; 23 } 24 return new_head; 25 } 26 27 partialSum * addListHelper(Node *l1, Node *l2) { 28 partialSum *sum = new partialSum; 29 if (l1->next == nullptr && l2->next == nullptr) { 30 int v = l1->data + l2->data; 31 sum->node = new Node(v % 10); 32 sum->carry = v / 10; 33 return sum; 34 } 35 else { 36 partialSum *part_sum = addListHelper(l1->next, l2->next); 37 int v = l1->data + l2->data + part_sum->carry; 38 sum->node = new Node(v % 10); 39 sum->carry = v / 10; 40 sum->node->next = part_sum->node; 41 } 42 return sum; 43 } 44 45 Node * addList(Node *l1, Node *l2) { 46 int len1 = length(l1); 47 int len2 = length(l2); 48 if (len1 < len2) 49 l1 = padList(l1, len2 - len1); 50 else if (len1 > len2) 51 l2 = padList(l2, len1 - len2); 52 if (l1 == nullptr && l2 == nullptr) 53 return nullptr; 54 partialSum *sum = addListHelper(l1, l2); 55 if (sum->carry > 0) { 56 Node *node = new Node(sum->carry); 57 node->next = sum->node; 58 return node; 59 } else return sum->node; 60 }
2.6 给定一个有环链表,实现一个算法返回环路的开头结点。
解答:链表环图示:
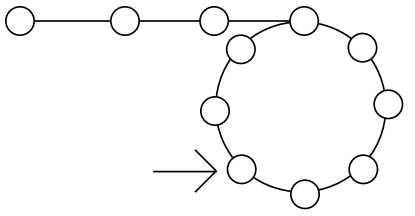
第一种方法:类似于找一个数组或链表中的重复元素的问题,这里实际上要找一个链表中next指针的重复问题(也可以与head重复)。所以同样可以用hash表解决,但是需要一定的额外存储空间。
1 Node * findLoopBeginning(Node *head) { 2 unordered_set<Node *> table; 3 while (head != nullptr) { 4 if (table.find(head) != table.end()) { 5 return head; 6 } else { 7 table.insert(head); 8 head = head->next; 9 } 10 } 11 return nullptr; 12 }
第二种方法:如果不允许用额外的数组空间,那么还有另一种技巧性比较强的方法:快慢指针法。
首先:如何判断是否有环?定义两个指针fast和slow,以不同的速度遍历链表。fast每次走两步,slow每次走一步,这样如果链表存在环,则两个指针一定会相遇。而且相遇的位置在环内。
然后:环入口点怎么找?当fast若与slow相遇时,slow肯定没有走遍历完链表,而fast已经在环内循环了n圈(1<=n)。假设slow走了s步,则fast走了2s步(fast步数还等于s
加上在环上多转的n圈),设环长为r,则:
2s = s + nr
s=
nr
设整个链表长L,入口环与相遇点距离为x,起点到环入口点的距离为a。
a + x =
nr
a + x = (n – 1)r +r = (n-1)r + L - a
a =
(n-1)r + (L – a – x)
(L – a –
x)为相遇点到环入口点的距离,由此可知,从链表头到环入口点等于(n-1)循环内环+相遇点到环入口点,于是我们从链表头、与相遇点分别设一个指针,每次各走一步,两个指针必定相遇,且相遇第一点为环入口点。
1 Node * findCircleBeginning(Node *head) { 2 Node *fast = head, *slow = head; 3 while (fast && fast->next) { 4 fast = fast->next->next; 5 slow = slow->next; 6 if (fast == slow) { 7 break; 8 } 9 } 10 if (fast == nullptr || fast->next == nullptr) { 11 return nullptr; 12 } 13 slow = head; 14 while (slow != fast) { 15 slow = slow->next; 16 fast = fast->next; 17 } 18 return slow; 19 }
2.7 编写一个函数,检查链表是否是回文(正看反看相同)。
解答:
方法1:反转链表,判断与原链表是否一致,实际上只需判断两个链表的前面一半即可。
方法2:反转链表的前半部分,与后半部分比较,借助栈来实现。
1 bool isPalindrome(Node *list) { 2 Node *fast = head, *slow = head; 3 stack<int> s; 4 while (fast != nullptr && fast->next != nullptr) { 5 s.push(slow->data); 6 slow = slow->next; 7 fast = fast->next->next; 8 } 9 if (fast != nullptr) { 10 slow = slow.next; 11 } 12 while (slow != nullptr) { 13 if (s.top() != slow->data) { 14 return false; 15 } 16 slow = slow->next; 17 } 18 return true; 19 }
方法3:递归,逐层判断收尾对应元素是否相等。如:0(1(2(3)2)1)0。
1 class Result { 2 public: 3 Node *node = nullptr; //该段后接的第一个结点 4 bool result = false; //该段是否满足回文性质 5 }; 6 7 8 Result isPalindromeRecurse(Node *list, int length) { 9 Result ret; 10 if (length <= 0) { 11 ret.result = true; 12 } 13 else if (length == 1) { 14 ret.node = list->next; 15 ret.result = true; 16 } 17 else if (length == 2) { 18 ret.node = list->next->next; 19 ret.result = (list->data == list->next->data); 20 } 21 else { 22 Result part_ret = isPalindromeRecurse(list->next, length - 2); 23 if (part_ret.result == false) { 24 ret.node = nullptr; 25 ret.result = false; 26 } 27 else { 28 ret.node = part_ret.node->next; 29 ret.result = (list->data == part_ret.node->data); 30 } 31 } 32 return ret; 33 } 34 bool isPalindrome(Node *list) { 35 return isPalindromeRecurse(list, length(list)).result; 36 }
【Cracking the Code Interview(5th edition)】二、链表(C++),布布扣,bubuko.com
【Cracking the Code Interview(5th edition)】二、链表(C++)
原文:http://www.cnblogs.com/dengeven/p/3737703.html