一、百度指数的发现
首先,我们先进入百度指数的官网:https://index.baidu.com/,如下图所示:

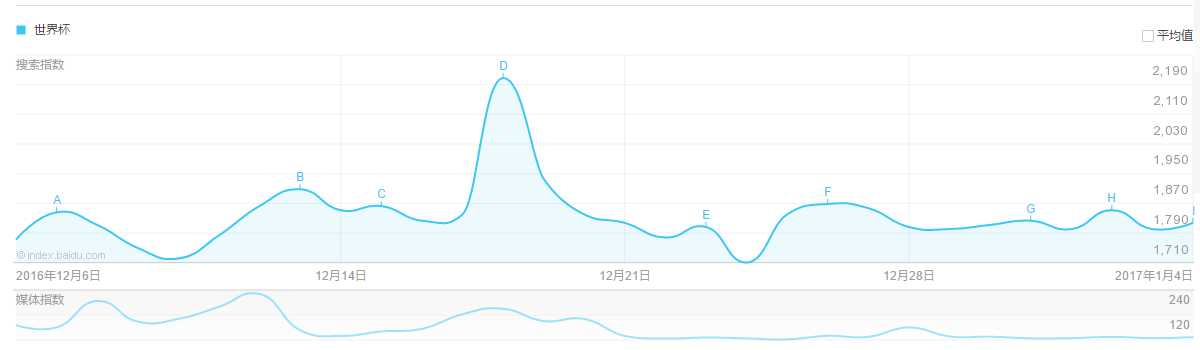
经过进入百度指数发现百度指数并没有公开的API可以获取,因为百度似乎在有意的增加百度指数的抓取难度. 返回的数据进行了加密,并且数据并不直接出现在页面上.javascript把加密的数据直接变成了页面上看到的图形。比如我输入世界杯,就会出现指数的格式如下图所示:
1、考虑能否直接采用抓取html协议
直接通过get或者post参数来获取百度指数的返回页面,然后用网页DOM模型提取对应标签数据,或者用正则表达式来提取。然后这种方法是行不通的,要不然谁都可以去拿了,就不需要我们这么费劲了,,真的够可以的,看来百度真会玩哦。。。但是我相信一定可以解决这个会玩的家伙,嘻哈。
既然她是一个图片,那我们就使用可以破解图片(也就是识别图片的方法来试一下,要是可以那就更好了,要是不可以,也不需要gg,路是慢慢的探索的)
好了,回归正题,听说Tesseract OCR框架可以识别图片耶,真的还是假的,都说是听说啦,肯定需要试一下,才知道是真的还是假的了。
首先,肯定需要安装很多需要的库拉。
谷歌图像识别Tesseract OCR需要很多库,首先是
pip install pillow
pip install pyocr
因为涉及到模拟点击,肯定需要安装火狐浏览器或者谷歌浏览器
首先安装selenium (2.53.6) 这个版本最好是这个的以下,否则火狐浏览需要安装多一点东西,很麻烦的。(再提示一下,火狐也是最好是4.6得版本)
如果是安装谷歌的话,那就需要再安装一个插件chromedriver.exe.
2、进行实战
首先要进行模拟登陆百度,所以就必须要密码和账号,然后手动输入验证码。
没空了,有时间继续。。。。
原文:http://www.cnblogs.com/caicaihong/p/6252162.html