本文由博主原创,转载请注明出处
github爬虫项目(源码)地址(已完成,关注和star在哪~):https://github.com/MatrixSeven/ZhihuSpider
附赠之前爬取的数据一份(mysql): 链接:https://github.com/MatrixSeven/ZhihuSpider 只下载不点赞,不star,差评差评~蓝瘦香菇)
什么,爬虫爬起来数据太慢了,怎么办?你那当然是开启多线程了。那么多线程是什么我就不介绍了。如果还不知道的,请左移多线程百度百科。
恩,知道了多线程,但是多线程如果自己控制的话,会很不好控制,所以咱们还需要两个线程池,一个负责拿到个人信息,一个负责获取用户的token。接下来让咱们之前写的ParserBase类实现Runnable,然后在ParserFollower里和ParserUserInfo里分别实现run方法,其实也很简单了,就是把之前的爬去逻辑,丢到run方法里。然后咱们就开启了多线程之旅。
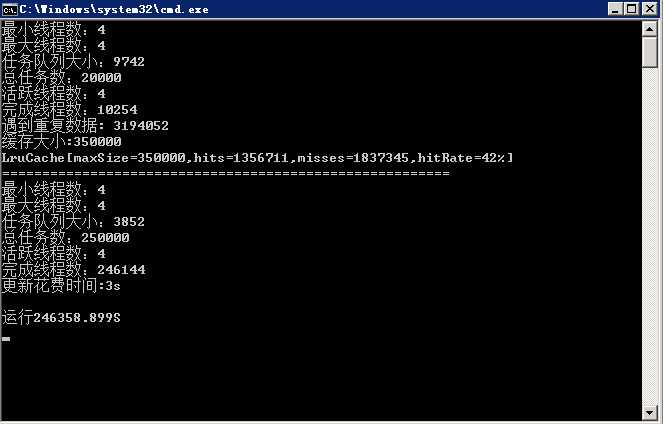
但是在存取数据的时候会遇到很多问题,比如数据会重复,这就出现了脏数据,那么咱们就是适当的加锁。来保证数据的干净。
如果说数据重复的问题解决的,那么咱们还有一个大问题,因为两次爬到的可能是同一个人,但是一份在数据库里,一份在正在跑的内存里,怎么办,当然是要连接下数据库,然后判断是数据是否已经在数据库中存在了,那么在多线程且获取速度很快的情况下,那么将会频繁访问数据库,造成速度缓慢,数据库链接数过多,cpu使用率过大,那咱们怎么除处理这个问题呢?
首先大家都一定知道,在现在内存非常大的今天,咱们完全可以把一部分数据直接缓存下载,而且程序访问内存的代价要比访问数据库的代价要小的太多。
因此,咱们可以用一个list把咱们已经有的token存下来,然后每次去这个list里去做验证,这样,就减少了数据库的访问了频率。
如上所说,用一个list的确是起到了减少数据库访问的目的,但是效果好像不如想象那么好,因为数据库里100k的数据,咱们不可能把所有数据都缓存下载,那么怎么才能在优化下呢?
这时候就要合理的处理这个list了,自己实现一个LRU缓存,来调高命中率。
那么lru是什么?y一句话LRU是Least Recently Used 近期最少使用算法,也叫淘汰算法。
具体实现和思想可见缓存淘汰算法–LRU算法。
按照这个思想,其实还有个优化,那就是根据碰撞次数和上次碰撞时间进行移除。咱们只是实现简单的,具体实现在MatrixSeven/ZhihuSpider
原文:http://www.cnblogs.com/seven007/p/6248578.html