
static int hash( int h ) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ ( h >>> 12) ;
return h ^ (h >>> 7 ) ^ (h >>> 4);
}
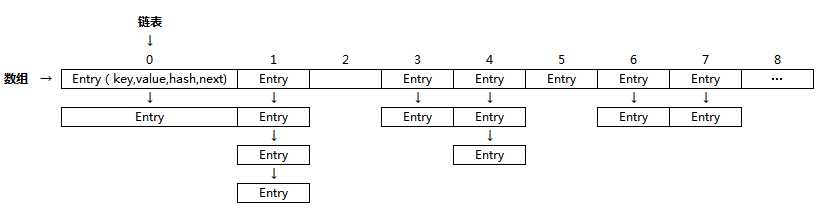
说明:该hash算法的内部实现乍一看的确很晦涩难懂。参数值h是key.hashCode(),很明显,该方法的意图就是根据key.hasCode()的值进行重新计算。为什么要这么做呢?因为HashMap要求key的hashCode值分布越均匀性能就越好(见上图,若hash函数计算出的hash值越均匀,链表的长度也就越均衡,就不会造成有的链表长度很短,而有的链表长度特别长的情况,我们知道,链表长度越长,检索效率就越慢)。而put到HashMap作为key的对象的hashCode可能五花八门,有的对象的hashCode可能还进行过重写,这可能导致put到HashMap中的key的hashCode值分布可能会不均衡,所以HashMap就利用这样一个算法对hashCode进行重新计算,以期望得到更加分布均衡的hashCode值。
static int indexFor( int h , int length) {
return h & (length - 1 );
}
说明:在计算机数学里有这么一个法则: 当SIZE满足大小是2的幂的时候,X % SIZE(取模操作)和 X & (SIZE-1)是等价的,不信?自己动手演算一下?因此我们知道了为什么HashMap要求我们提供的capacity大小是2的幂的原因了吧?用户提供给HashMap构造函数的capacity值可能不是2的幂,所以hashmap内部进行了验证并将其重设为最接近指定capacity值的2的幂的那个值:
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
介绍了前两个重要方法,下面欢迎我们熟悉的put方法出场:
public V put ( K key , V value ) {
if ( key == null)
return putForNullKey ( value) ;
int hash = hash (key . hashCode()) ;
int i = indexFor (hash , table . length) ;
for ( Entry <K , V> e = table [ i ]; e != null ; e = e. next ) {
Object k ;
//
if ( e .hash == hash && ((k = e .key ) == key || key .equals ( k))) {
V oldValue = e. value ;
e .value = value ;
e .recordAccess ( this) ;
return oldValue ;
}
}
modCount ++;
addEntry (hash , key , value , i ) ;
return null ;
}
原文:http://www.cnblogs.com/zpbolgs/p/6262379.html