1.flume概念介绍
1.1 常见的分布式日志收集系统

Scribe是facebook开源的日志收集系统,在facebook内部已经得到大量的应用。 Chukwa 是一个开源的用于监控大型分布式系统的数据收集系统。这是构建在 hadoop 的 hdfs 和 map/reduce 框架之上的,继承了hadoop 的可伸缩性和鲁棒性。
Flume 是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力 。这里的日志是一个统称,泛指文件、操作记录等许多数据。
1.2 flume的应用场景
flume主要是作为实时计算和离线计算的数据源采集工具在项目中使用,结构图如下:
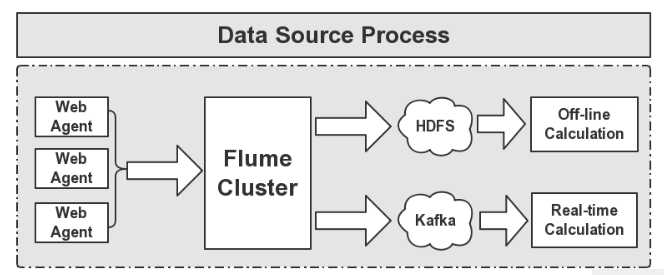
web agent是应用服务器,flume cluster是flume服务器部署的集群,日志从web agent到flume的方式主要有两种方式:主用获取与被动获取。
日志收集到flume服务器后,可以将数据存储到HDFS,Hbase,Hive,后续从这些地方获取数据进行数据的离线计算;也可以将数据发送到kafka中,kafka是拥有高吞吐特性的消息队列,数据经由kafka流转到storm或sparkstreaming中进行实时计算。
适用场景:日志--->Flume--->实时计算(Storm、sparkstreaming) ;日志--->Flume--->离线计算(如HIVE、HDFS、HBase)
1.3 flume-og与flume-ng
原文:http://www.cnblogs.com/jian-xiao/p/6272303.html