1.Wordcount.scala(本地模式)
package com.Mars.spark import org.apache.spark.{SparkConf, SparkContext} /** * Created by Mars on 2017/1/11. */ object Wordcount { def main(args: Array[String]) { val conf = new SparkConf().setAppName("SparkwordcountApp").setMaster("local") val sc = new SparkContext(conf) //SparkContext 是把代码提交到集群或者本地的通道 val line = sc.textFile("D:/Test/wordcount.txt") //把读取的内容保存给line变量,其实line是一个MappedRDD,Spark的所有操作都是基于RDD的 line.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect.foreach(println) sc.stop } }
上述代码是基于IDEA运行的本地模式。
wordcount.txt
hadoop spark tez mllib mllib tez tez hive hadoop hive hive docker
运行结果:
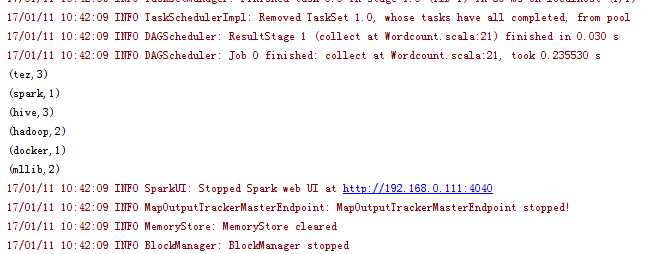
2.打成jar上传集群代码
package com.Mars.spark
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Mars on 2017/1/11.
*/
object Wordcount {
def main(args: Array[String]) {
if(args.length < 1) {
System.out.println("spark-submit --master yarn-client --class com.Mars.spark.Wordcount --name wordcount --executor-memory 400M --driver-memory 512M wordcount.jar hdfs://192.168.0.33:8020/tmp/wordcount.txt")
System.exit(1)
}
val conf = new SparkConf().setAppName("SparkwordcountApp")
val sc = new SparkContext(conf)
//SparkContext 是把代码提交到集群或者本地的通道
val line = sc.textFile(args(0))
//把读取的内容保存给line变量,其实line是一个MappedRDD,Spark的所有操作都是基于RDD的
line.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect.foreach(println)
sc.stop
}
}
原文:http://www.cnblogs.com/zeppelin/p/6272773.html