上段时间学习caffe,caffe的solver优化方法中涉及到梯度下降法。当时对梯度下降法的概念和原理都很模糊,就专门去学习了下,现在把自己的理解记录下来,一方面加深印象,一方面也方便随时查阅。如果有理解错误的地方,希望看到的予以指正,谢谢。
一、什么是梯度?梯度和方向导数的关系是什么?(简述,需要详细了解的可以自行搜索)
方向导数:对于一个函数f,在其定义域内存在一点k,我们把函数f在点k上任一方向的导数,叫做方向导数。
梯度:经过数学推理可以证明,函数f在k点的梯度方向,等于函数f在k点方向导数取最大值的方向,梯度的模为方向导数最大值。这里我们可以理解为:方向导数代表着函数在k点的变换率,当变换率最大时,梯度最长,此时函数在该点的梯度方向是向上的。
二、损失函数--loss function
损失函数描述的是预测函数“不好”的程度。
假设对于一组数据集(x1,y1),(x2,y2),...,(xn,yn),假设其预测函数为hΘ(x),Θ为参数权重,是一个向量,x为参数,其loss函数可以定义为:
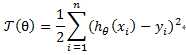
其中hΘ(xi)对应xi的预测值,而yi为其对应的真实值。
我们的目的:寻找到一个 ,使得损失函数最小。
,使得损失函数最小。
三、如何使得损失函数最小--梯度下降法
1、梯度下降法的流程
(1) 首先对随机赋值;
(2) 对进行求导,并且使得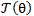 按照梯度下降的方向进行减少。
按照梯度下降的方向进行减少。
(3) 当梯度下降到预设值时,停止下降。此时认为损失函数在处收敛,变化率最小。
2、梯度下降法公式:
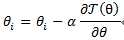
含义:对于每一个,函数都沿着其下降最多的方向进行变化,直到达到一个极小值。
理解:因为梯度的方向是方向导数取最大值时的方向,此时函数在点的变化率最大且为正值,即当前梯度的方向为上升最多的方向。如果想要获得向下下降最多的方向,即取当前梯度方向的反方向即可。
3、举例说明(注:本例子图片来自http://blog.csdn.net/zengdong_1991/article/details/45563107)
看下图:
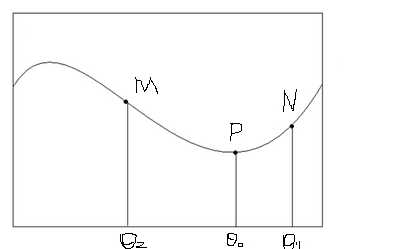
分析:

Ps:个人理解--因为梯度的方向是方向导数取最大值的方向,方向导数取最大值,一定大于0,所以此时梯度的方向就是函数变化率最大的方向且方向向上。而梯度下降发用负号使得变化的方向变为梯度下降最多的方向。
四、梯度下降与梯度上升
1、梯度上升公式:
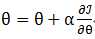
2、梯度下降与梯度上升区别与联系
其实梯度下降与梯度上升,描述的是在迭代过程中参数值更新的方向。梯度下降即参数值更新的方向与梯度本身的方向相反,即向下的方向更新;而梯度上升即参数值更新的方向与梯度的方向相同,即向上的方向更新。但是注意:无论梯度的方向是向上还是向下,在迭代过程中,梯度的模是一直下降的,因为随着梯度方向的改变,函数的变化率都是逐渐降低的,变化率降低,方向导数的最大值下降,即梯度的模值降低。
搞不清楚的,可以参考上图理解。
PS:写完发现自己其实理解的还是很浅显,在博文中很多表达其实都不够准确,先写成这样,等以后理解加深了,再进行修正。刚开始写博文,搞的很丑,还需改进。
参考博文:
1.http://blog.csdn.net/wolenski/article/details/8030654
2.http://blog.csdn.net/zengdong_1991/article/details/45563107
3.http://blog.csdn.net/xiazdong/article/details/7950084
4.http://www.cnblogs.com/hitwhhw09/p/4715030.html
原文:http://www.cnblogs.com/yyxf1413/p/6291312.html