本系列意在长期连载分享,内容上可能也会有所增删改减;
因此如果转载,请务必保留源地址,非常感谢!
知乎专栏:https://zhuanlan.zhihu.com/data-miner
博客园:http://www.cnblogs.com/data-miner(暂时公式显示有问题)
Fuzzy C-Means 是一种模糊聚类算法。K-means中每一个元素只能属于一个类别,而Fuzzy C-Means中一个元素以不同的概率属于每一个类别。
Fuzzy C-Means最早出自J. C. Dunn. "A Fuzzy Relative of the ISODATA Process and Its Use in Detecting Compact Well-Separated Clusters." 1973,而后在Bezdek, James C. Pattern recognition with fuzzy objective function algorithms, 1981书中被改进。由于后者是一本书,我就没有去翻看原著了。以下给出的是现在常用的版本
类似于K-means,FCM的损失函数如下

其中,满足如下限制
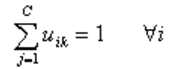
求取FCM损失函数极小值,依然是迭代进行,步骤如下。其中参数更新的公式,可以通过对1中公式用拉格朗日法求解。

Hierarchical Clustering即层次聚类。它有两种类型:
自上而下:即最初将所有样本看做一个类别,然后依据一定规则进行分裂,直到每个样本单独一个类别;这个方法在实际中应用很少
Hierarchical Clustering最早出自Johnson, Stephen C. "Hierarchical clustering schemes." 1967,步骤如下:
其中在步骤3中计算距离,有几种不同的计算方式:
DBSCAN即Density-Based Spatial Clustering of Applications with Noise,是一种基于密度的聚类算法,最早出自Ester, Martin, et al. "A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise." 1996。作者认为聚类算法应该尽量满足以下三点要求:
对大规模数据的性能要好
针对以上三点,作者提出了DBSCAN算法。这种算法本质是认为同一个类别的数据点集在空间中的密度是比较大的,而不同类别的数据集间的点在空间中密度很小。如下图,应该被分割成四个类别

DBSCAN算法首先需要定义一些概念:
密度相连:存在样本集合D中的一点o,如果对象o到对象p和对象q都是密度可达的,那么p和q密度相联
DBSCAN算法的具体步骤如下(引用的DBSCAN伪代码,比原文中的易懂)
DBSCAN(D, eps, MinPts) {# 找到核心对象PC = 0for each point P in dataset D {if P is visitedcontinue next pointmark P as visitedNeighborPts = regionQuery(P, eps)if sizeof(NeighborPts) < MinPtsmark P as NOISEelse {C = next clusterexpandCluster(P, NeighborPts, C, eps, MinPts)}}}expandCluster(P, NeighborPts, C, eps, MinPts) {# 找到所有从核心对象P密度可达的点add P to cluster Cfor each point P‘‘ in NeighborPts {if P‘‘ is not visited {mark P‘‘ as visitedNeighborPts‘‘ = regionQuery(P‘‘, eps)if sizeof(NeighborPts‘‘) >= MinPtsNeighborPts = NeighborPts joined with NeighborPts‘‘}if P‘‘ is not yet member of any clusteradd P‘‘ to cluster C}}regionQuery(P, eps)# 查询点P的E邻域的点集return all points within P‘‘s eps-neighborhood (including P)
原文中还有如何探索式的选择合适的参数,这里不再赘述。
原文:http://www.cnblogs.com/data-miner/p/6298468.html