---恢复内容开始---
赫夫曼编码为文件压缩的重要部分。
这次的代码是在文件“in.txt”中读取其中的字符串,并对其进行赫夫曼编码。
操作者可以对in.txt进行更改,输出会显示每个字符在文本中的个数,并可以输入你想要查找的字符,得到在本文中的赫夫曼编码。
先说一下这次代码的几点不足:
首先这次的存储空间为静态,全文没有malloc,而是固定的数组100,因此在txt中的字符串长度不要超过100,也不要小于3;
其次赫夫曼树的存储结构为结构体数组形式,没有用指针(链式)存储;
再有赫夫曼树构造时的权值为个数,而不是该字符在全文中所占的比例。
这几点不足主要是因为这样比较简单。。。
上代码
#include <stdio.h> #include <string.h> static int length=0; static int tree_length; struct per { char let; int num=0; } per[100];//每个字符为一个per,let为其字符名称,num为其在文中的个数 struct tree { int weight; int lchild=-1,rchild=-1,parent=100; char letter=‘<‘; char code=‘x‘; } tree[200];//赫夫曼树结构体,几个字母都是默认值,都是随便取得 void getpercentage(char l[])//得到每个字符在文本中的个数 { for(int i=0; i<strlen(l); i++)//获得个数 { if(l[i]!=‘<‘) { per[length].let=l[i]; per[length].num=1; for(int j=i+1; j<strlen(l); j++) if(l[i]==l[j]) { per[length].num++; l[j]=‘<‘; } length++; } } } void gethuffmantree(char l[])//构造赫夫曼树 { for(int i=0; i<length-1; i++)//先进行从小到大的排序 for(int j=0; j<length-i-1; j++) if(per[j].num>per[j+1].num) { per[100]=per[j]; per[j]=per[j+1]; per[j+1]=per[100]; } for(int i=0; i<length; i++) printf("%c %d\n",per[i].let,per[i].num);//按从小到大的顺序输出 // tree[0].weight=per[0].num; tree[1].weight=per[1].num; tree[2].lchild=0; tree[2].rchild=1; tree[0].parent=2; tree[1].parent=2; tree[0].letter=per[0].let; tree[1].letter=per[1].let; tree[2].weight=per[0].num+per[1].num; int tempw=tree[2].weight; int temp=2; //先用最小的两个构造一个树,temp为构造到的结点的编号,tempw为顶部结点(即当前最大的那个)的权值 for(int i=2; i<strlen(l)-1&&per[i].num!=0; i++) { if((per[i].num<tempw&&per[i+1].num<tempw)&&(per[i+1].num!=0)) { // temp=temp+4; tree[temp-1].lchild=temp-3; tree[temp-1].rchild=temp-2; tree[temp-3].letter=per[i].let; tree[temp-2].letter=per[i+1].let; tree[temp-3].weight=per[i].num; tree[temp-2].weight=per[i+1].num; tree[temp-1].weight=tree[temp-2].weight+tree[temp-3].weight; tree[temp-3].parent=temp-1; tree[temp-2].parent=temp-1; tree[temp].lchild=temp-4; tree[temp].rchild=temp-1; tree[temp].weight=tree[tree[temp].lchild].weight+tree[tree[temp].rchild].weight; tree[temp-4].parent=temp; tree[temp-1].parent=temp; i++; tempw=tree[temp].weight; } //分为两种情况,上面的为在一旁构建新树的情况,要用两个per //下面的为用一个per继续生长的情况 else { temp=temp+2; tree[temp].lchild=temp-2; tree[temp].rchild=temp-1; tree[temp-1].parent=temp; tree[temp-2].parent=temp; tree[temp-1].weight=per[i].num; tree[temp-1].letter=per[i].let; tree[temp].weight=tree[tree[temp].lchild].weight+tree[tree[temp].rchild].weight; tempw=tree[temp].weight; } } tree_length=temp+1; } void getcode(int t)//得到每个结点的编码,即‘0’或‘1’,并将其写入结构体数组中 { if(t==-1) return; else { tree[tree[t].lchild].code=‘0‘; tree[tree[t].rchild].code=‘1‘; getcode(t-1); } } void findcode(int w)//得到想要的赫夫曼编码,并将其输出 { int p; char code[20]; int code_length=0; for(int i=0; i<tree_length; i++) if(tree[i].letter==w) { p=i; code[0]=tree[i].code; break; } for(int j=1; p<tree_length; j++) { code[j]=tree[tree[p].parent].code; p=tree[p].parent; code_length++; }//方法为从要查找节点开始,找他的父节点,并记录编码值,最后将其倒序输出 for(int i=code_length-2; i>=0; i--) printf("%c",code[i]); printf("\n"); } int main() { char letter[100]; // FILE *fp=fopen("in.txt","r"); if(!fp) { printf("can‘t open file\n"); return -1; } fgets(letter,100,fp); fclose(fp); //打开文件部分 getpercentage(letter); gethuffmantree(letter); getcode(tree_length-1); char want; printf("Please enter the letter you want to find,and end with ‘EOF‘:\n"); while(scanf("%c",&want)!=EOF) findcode(want); }
样例
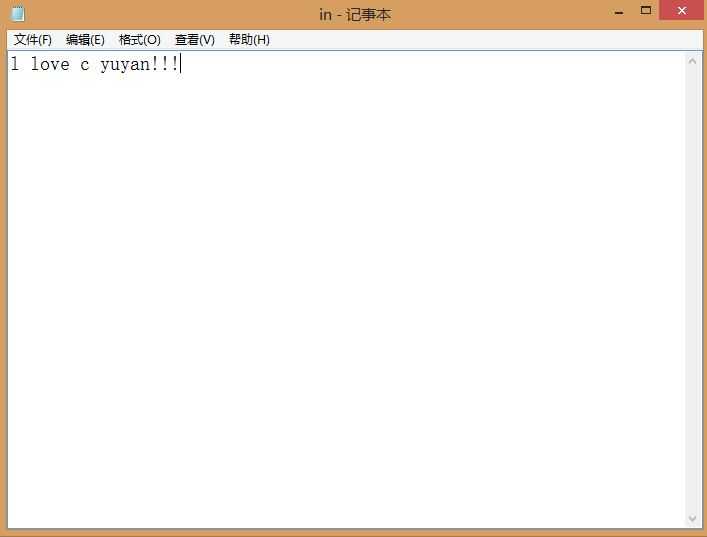
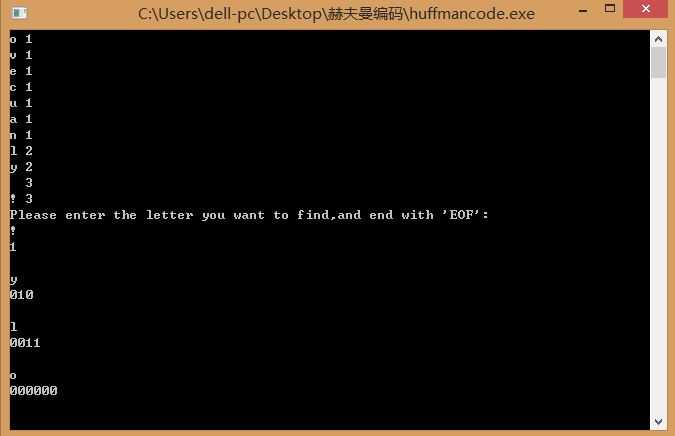
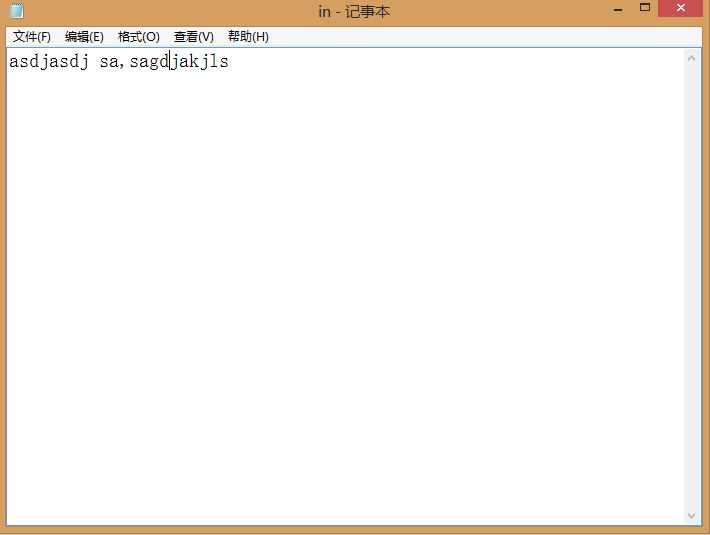
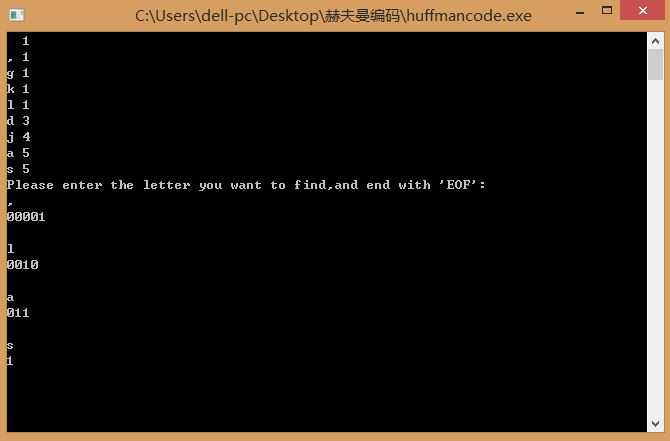
欢迎大家指正和教导!!!
---恢复内容结束---
原文:http://www.cnblogs.com/superxinyu/p/6308409.html