就非西欧字符而言,比如中国以及港澳台,在任何编程语言的开发中都不得不考虑字符集及其表示。在c++中,对于超过1个字节的字符,有两种方式可以表示:
1、多字节表示法;通常用于存储(空间效率考虑)。
2、宽字符表示法,通常用于程序中(性能考虑)。
目前最主要或最常见的字符集应该来说包括:
ASCII,7位。
ISO-Latin-1/ISO-8859-1,8位。
UCS-2,16位定长。
UTF-8,8-32位变长。
UTF-16,16或32位变长。
UCS-4/UTF-32,32位定长。
对于特定的字符,各编码格式所占的字节数和编码值如下:
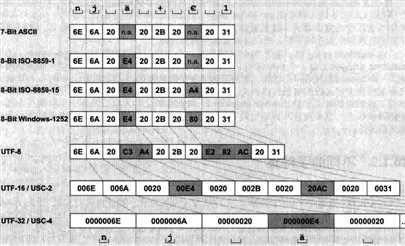
说到UTF-16/UTF-32,不得不说BOM(byte order mark),它的作用跟网络编程中的字节码顺序概念一样,用于标识使用big endian或者little endian。

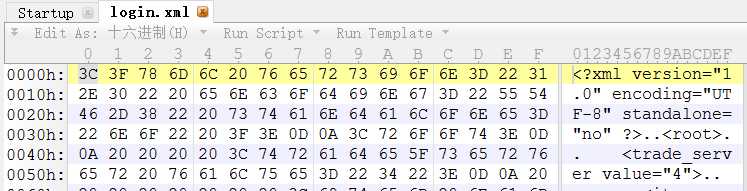
无BOM的字节流开始:
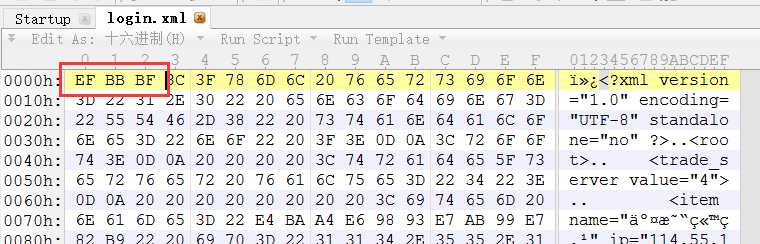
带BOM的字节流开始:
在c++中,并没有原生支持GBK/GB18050/UTF-8的编码,如下:

基本上广泛用的就是char和wchar_t。
对于常规控制台输入的,基本上网上很多demo了,所以接下去来看下从文件或者网络socket端过来的utf-8或者GBK编码如何处理的。
原文:http://www.cnblogs.com/zhjh256/p/6351266.html