Naive Bayes 朴素贝叶斯
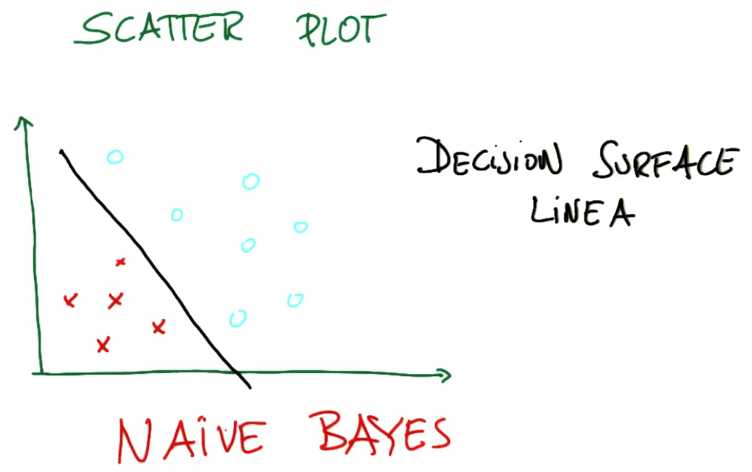
Scatter plot 散点图
Decision Surface Linea 决策线
朴素贝叶斯 是一个常见的寻找决策面的算法
Bayes Rule 贝叶斯规则
无人驾驶汽车是一个重要的监督分类(supervised classification)问题
监督:表示你有许多样本,我们可以说,你了解这些样本的正确答案
机器学习主要是从实例中学习,给机器举一大堆案例,每个案例都有许多特征和属性,
如果可以挑出正确的特征,它会给你正确的信息,然后就可以对新的案例进行分类
如何利用机器学习算法来正确处理这类问题?
第一个是的,第二个不是,因为并没有给出异常交易的明确定义,第三个是,第四个不是,属于聚类问题
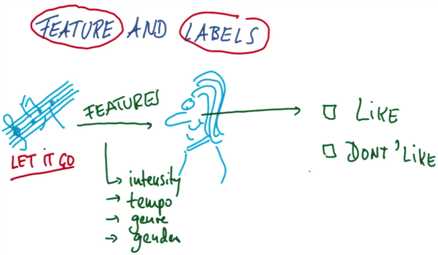
Features & Labels 特征和标签
在机器学习中,我们通常会把特征作为输入,然后尝试生成标签
比如你听一首歌,它的特征可能是强度、歌曲节奏或者流派或声音性别等信息
然后你的大脑会将它处理为两个类别中的一个喜欢或者不喜欢
机器学习算法能做什么呢?它们可以定义决策面 scatter plot decision surface
决策面通常位于两个不同的类之间的某个位置上
当决策面为直线的时候,我们称它为线性决策面
机器学习算法所做的是 获取数据->并将其转化成一个决策面(D.S)
Naive Bayes 是一个常见的寻找这样的决策面的算法
scikit-learn,经常缩写为sklearn
Google 搜索 sklearn navie bayes
打开链接http://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.GaussianNB.html
>>> import numpy as np >>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) >>> Y = np.array([1, 1, 1, 2, 2, 2])
#上面的代码是用来生成一些可以利用的训练点 >>> from sklearn.naive_bayes import GaussianNB
#把外部模块引入你编写的代码里 >>> clf = GaussianNB()#创建分类器,把GaussianNB赋值给clf(分类器) >>> clf.fit(X, Y)#fit替代了train,这里是我们实际提供训练数据的地方
#它会学习各种模式,然后就形成了我们刚刚创建的分类器(clf)
#我们在分类器上调用fit函数,接下来将两个参数传递给fit函数,一个是特征x一个是标签y
#在监督分类中这个过程都是如此,先调用fit函数,然后依次获得特征和标签 GaussianNB(priors=None)
#最后我们让已经完成了训练的分类器进行一些预测,我们为它提供一个新点[-0.8,-1]
#我们系那个知道的是,这个特定点的标签是什么?它属于什么类? >>> print(clf.predict([[-0.8, -1]])) [1] >>> clf_pf = GaussianNB() >>> clf_pf.partial_fit(X, Y, np.unique(Y)) GaussianNB(priors=None) >>> print(clf_pf.predict([[-0.8, -1]])) [1]
必须先训练好分类器,才能调用分类器上的预测函数。因为使用数据训练的过程是它实际学习模式的过程
然后分类器能利用学得的模式进行预测
原文:http://www.cnblogs.com/custer/p/6347331.html