1、先在cmd中cd到想要建立项目的目录
2、输入scrapy startproject xxxx(xxxx为自己的项目名)
1 scrapy startproject maopu
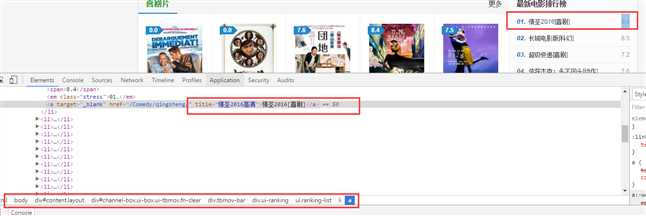
3、例如我想要http://www.diediao.com/movie/爬取电影名和电影评分,用谷歌浏览器打开,然后F12,在调试面板中跟踪右边的标签,然后右键copy->xpath
//*[@id="channel-box"]/div[2]/div[1]/ul/li[1]/a,清理一下得到//*[@id="channel-box"]/div/div/ul/li/a,这就是右边所有的a标签。
4、在item.py输入自己想要爬取的字段。(电影名和电影评分)
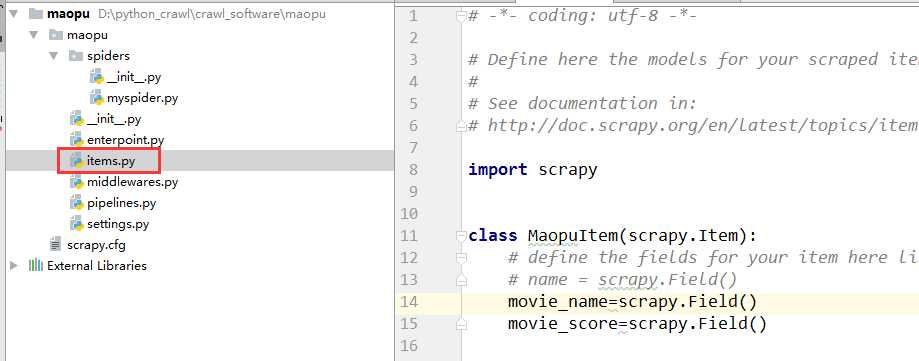
import scrapy class MaopuItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() movie_name=scrapy.Field() movie_score=scrapy.Field()
5、可以手工在根目录下的spider建立自己的爬虫.py
1 import scrapy 2 from maopu.items import MaopuItem 3 class MopSpider(scrapy.Spider): 4 name=‘myspider‘ 5 allowed_domains=[‘diediao.com‘] 6 7 start_urls = [ 8 "http://www.diediao.com/movie/", 9 ] 10 11 def parse(self, response): 12 for sel in response.xpath(‘//*[@id="channel-box"]/div/div/ul/li‘): 13 item=MaopuItem() 14 item[‘movie_name‘]=sel.xpath(‘a/text()‘).extract() 15 item[‘movie_score‘] = sel.xpath(‘span/text()‘).extract() 16 print(item) 17 yield item
关于parse,可以先去shell里测试测试:(不熟悉xpath的可以到http://www.w3school.com.cn/xpath/index.asp)
cmd里或者在pycharm下面的terminal中里输入
scrapy shell "http://www.diediao.com/movie/"
>>> response.xpath(‘//*[@id="channel-box"]/div/div/ul/li/a/text()‘).extract()
>>> response.xpath(‘//*[@id="channel-box"]/div/div/ul/li/span/text()‘).extract()

测试完后可以输入quit()或则ctrl+z退出
5、执行spider:方法1
cmd里或者在pycharm下面的terminal中里输入(需要cd到项目根目录)
scrapy crawl mySpider
执行spider:方法2
在项目根目录里新建entrypoint.py,在这执行和命令行是一样的效果
from scrapy.cmdline import execute execute([‘scrapy‘, ‘crawl‘, ‘mySpider‘])
原文:http://www.cnblogs.com/l-eon/p/6351544.html