Support Vector machines
为什么人们称一种算法为机器,我也不知道(俄罗斯人发明)
粗略的来说,支持向量机所做的就是去寻找分割线(separating)
或者通常称之为超平面,介于两个类别的数据之间
所以想象一下我们有一些两个不同类别的数据,SVM是一种算法,通过采用这些数据作为输入
然后输出一条线,来将这些数据分类。
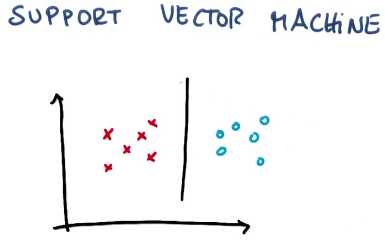
这条线它最大化了到最近点的距离,并且它对涉及的两个分类均最大化了此类距离
这是一条在每个分类里均最大化了到最近点的距离的线
而这个距离通常被称之为间隔(margin),这是一个被最大化了的东西
间隔 就是线与两个分类中最近点的距离
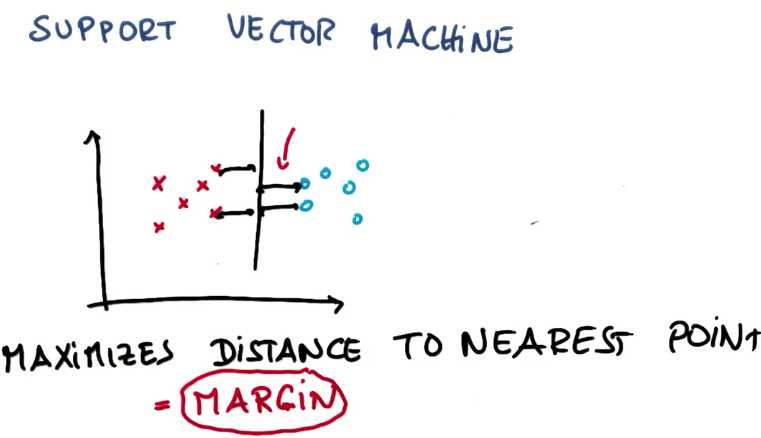
是因为这条线不容易出现分类误差,如果选择非常靠近现有数据的线,细微的噪声也会
使那边的标签倒转,从而感到没有那么稳定,所以支持向量机的内部原理是
SVM的原理是:最大限度地提升结果的稳定性(result)
SVM总是将正确的分类标签作为首要考虑,然后对间隔进行最大化
有时候对于SVM来说,可能无法正确 完成工作
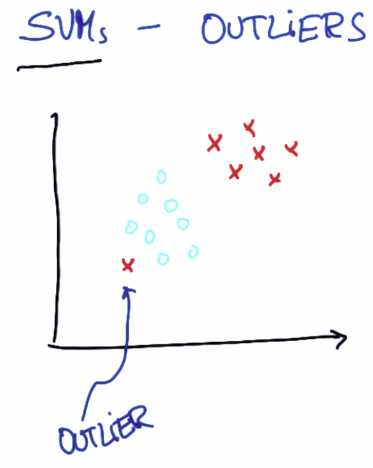
对于不存在能将两个类分割的决策面,你可以将这个点看作是异常值
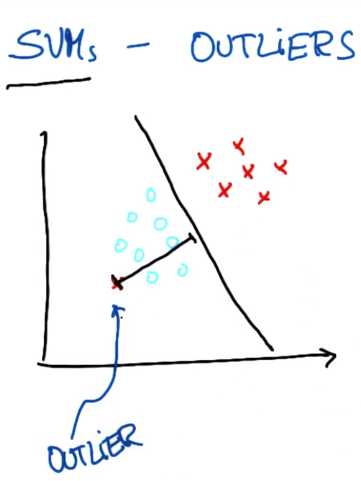
最好是像这样作为一个决策边界,直接把受影响的一点标在另一边
其实SVM足以做到这一点,它经常能找到使两个数据集间距最大化的决策边界
同时默许单个异常值(outliers),就像上图显示的
但应该知道的一点是SVM实际上对异常值的情况较为健壮,这在某种程度上
均衡了它找出最大距离的间隔和忽略异常值的能力
显然这也是有代价的,我们可以看到SVM参数决定了它如何检测新的异常值
http://scikit-learn.org/stable/modules/svm.html
from sklearn import svm X = [[0, 0], [1, 1]] y = [0, 1] clf = svm.SVC() clf.fit(X, y) clf.predict([[2., 2.]])
import statement, training features, traning labels,create classifier
导入语句,训练特征,训练标签,创建分类器,并使用训练特征和训练标签进行拟合,以及如何进行预测
scikit-learn的优点之一:基本上我们要查看的所有分类器以及未来你可能自行使用的所有分类器
都遵循这一相同的模式where you import it, you create it, you fit it, you make predictions
即导入、创建、拟合 然后预测,而且语法也相同
SVM Decision Bounddary
原文:http://www.cnblogs.com/custer/p/6351874.html