如何实现一个具有表达式解析功能的功能模块?
解析一个表达式的目的:最基本的是能获取表达式的值;对后端获取数据的简单处理;具备一定的逻辑处理能力;
最简单的实现方法:
function parse (expr) { return function(scope) { with (scope) { return eval(expr); } } }
parse函数返回一个函数,执行返回的函数并传入作用域即可在传入的作用域中,计算出表达式的值。
当然,这种做法简单粗暴。with和eval在严格模式下往往不可用。
一个具有解析表达式能力的模块,其输入当然是字符串,其输出则是一个可执行函数,执行该函数即可获取到表达式的值。
表达式的常见种类如下:
主要包括:字面量;函数调用;运算符;声明;成员获取;

下面是一种在angular 1.x中被用作表达式处理的方法:
新写一个词法解析语言。
主要包括三个部分:词法分析Lexer;AST(Abstract Syntax Tree)构建;AST编译;
如:输入"a + b"; 1.先经过Lexer处理,输出tokens: [ {text: ‘a‘, identifier: true}, {text: ‘+‘}, {text: ‘b‘, identifier: true} ] 2.tokens输入到AST build中,输出AST { type: AST.BinaryExpression, operator: ‘+‘, left: { type: AST.Identifier, name: ‘a‘ }, right: { type: AST.Identifier, name: ‘b‘ } } 3.AST输入到AST compiler中,返回一个可执行函数 function(scope) { return scope.a + scope.b }
Lexer直接面对字符串text,输出tokens数组。具体地,通过Lexer.prototype.lex原型函数来实现
由于需要对字符串的每个字符进行处理,因此需要进行循环操作。
第一个循环:根据输入内容,确定采用何种方法进行处理;
针对常见的表达式类型:依次确定如下几种类型的输入,并给予相应的处理。
1)数字 readNumber();
2)字符串 readString();
3)标识符 readIdent();
4)空白字符 index++;
5)属性获取‘[]{}:()‘ just push到tokens中;
6)以上都不是 throw err;
具体代码如下:
while (this.index < this.text.length) { this.ch = this.text.charAt(this.index); if (this.isNumber(this.ch) || (this.is(‘.‘) && this.isNumber(this.peek()))) { this.readNumber(); } else if (this.is(‘\‘"‘)) { this.readString(this.ch); } else if (this.is(‘[],{}:.()?;‘)) { this.tokens.push({ text: this.ch }); this.index++; } else if (this.isIdent(this.ch)) { this.readIdent(); } else if (this.isWhitespace(this.ch)) { this.index++; } else { throw ‘Unexpected next character: ‘ + this.ch; } } }
第二个循环:进入处理函数内部,依次遍历每个字符。
readNumer: 返回tokens由text和value组成。
Lexer.prototype.readNumber = function() { var number = ‘‘; while (this.index < this.text.length) { // number = 1 * number; this.tokens.push({ text: number, value: Number(number) }); };
readString:返回tokens由text和value组成
Lexer.prototype.readString = function(quote) { this.index++; var string = ‘‘; while (this.index < this.text.length) { // this.index++; this.tokens.push({ text: rawString, value: string }); // } };
readIdent: 返回tokens由text和identifier标识组成
Lexer.prototype.readIdent = function() { var text = ‘‘; while (this.index < this.text.length) { // var token = { text: text, identifier: true }; this.tokens.push(token); };
输入的是构造函数Lexer的实例,执行实例的原型方法lex,获取返回值tokens。加工tokens获取AST
AST为抽象语法树。其作用在于牢牢抓住表达式的构造,从而方便编译过程的后续环节对表达式进行解读。例如,React中的虚拟DOM的实现,实际上也有AST的构造过程。准确的AST构建,是正确编译(如生成实际dom树)的前提。
根据表达式的分类。生成的AST树具有以下几种节点类型。
AST.Program = ‘Program‘; //根节点 AST.Literal = ‘Literal‘; //字面量节点 AST.ArrayExpression = ‘ArrayExpression‘; //数组 AST.ObjectExpression = ‘ObjectExpression‘; //对象 AST.Property = ‘Property‘; //属性 AST.Identifier = ‘Identifier‘; //标识符 AST.ThisExpression = ‘ThisExpression‘; // this AST.MemberExpression = ‘MemberExpression‘; //成员表达式 AST.CallExpression = ‘CallExpression‘; //函数调用 AST.AssignmentExpression = ‘AssignmentExpression‘; //赋值表达式 AST.UnaryExpression = ‘UnaryExpression‘; //一元表达式 AST.BinaryExpression = ‘BinaryExpression‘; //二元表达式 AST.LogicalExpression = ‘LogicalExpression; //逻辑表达式
根据输入的tokens数组,需要进行类似pipe的处理。这里的pipe处理实际上处理了表达式中的操作符优先级问题
1. AST.prototype.program
构建AST的根节点;返回
{
type: AST.Program,
body: body
}
2. AST.prototype.assignment
处理赋值表达式:返回
{
type: AST.AssignmentExpression,
left: left,
right: right
}
3. AST.prototype.logicalOR
处理逻辑或:返回
{ type: AST.LogicalExpression, operator: token.text, left: left, right: this.logicalAND() }
4. AST.prototype.logicalAND
处理逻辑与:返回
{ type: AST.LogicalExpression, operator: token.text, left: left, right: this.equality() }
5. AST.prototype.equality
处理比较表达式(‘==‘,‘!=‘,‘===‘,‘!==‘):返回
{ type: AST.BinaryExpression, operator: token.text, left: left, right: this.relational() };
6. AST.prototype.relational
处理关系表达式(‘<‘,‘>‘,‘<=‘,‘>=‘):返回
{ type: AST.BinaryExpression, operator: token.text, left: left, right: this.additive() };
7. AST.prototype.additive
处理加减操作:返回
{ type: AST.BinaryExpression, operator: token.text, left: left, right: this.multiplicative() }
8. AST.prototype.multiplicative
处理乘除操作: 返回
{ type: AST.BinaryExpression, operator: token.text, left: left, right: this.unary() }
9. AST.prototype.unary
处理一元操作符:返回
{ type: AST.UnaryExpression, operator: token.text, argument: this.unary() }
此时存在递归调用unary,当边界条件满足时,其最终返回this.primary()
10. AST.prototype.primary
核心处理函数:
if (this.expect(‘[‘)) { primary = this.arrayDeclaration(); } else if (this.expect(‘{‘)) { primary = this.object(); } else if (this.constants.hasOwnProperty(this.tokens[0].text)) { primary = this.constants[this.consume().text]; } else if (this.peek().identifier){ primary = this.identifier(); } else{ primary = this.constant(); }
其中首先需说明的是从第2步执行到第10步,最核心的工具方法,expect函数。其用来判断当前tokens的数组项是否是期望的内容,并且shift移除这个tokens项。以实现在pipe中依次过滤处理的效果。
AST.prototype.expect = function(e1, e2, e3, e4) { var token = this.peek(e1, e2, e3, e4); if (token) { //注意shift的使用 return this.tokens.shift(); } }; AST.prototype.peek = function(e1, e2, e3, e4) { if (this.tokens.length > 0) { var text = this.tokens[0].text; if (text === e1 ||text === e2 ||text === e3 ||text === e4 || (!e1 && !e2 && !e3 && !e4)) { return this.tokens[0]; } } };
接着primary函数的处理逻辑,首先判断
1)AST.ArrayExpression 数组类型
-->this.arrayDeclaration() 返回
AST.prototype.arrayDeclaration = function() { var elements = []; if (!this.peek(‘]‘)) { do { if (this.peek(‘]‘)) { break; } //对每个数组元素都需递归进行this.primary()处理。 elements.push(this.assignment()); } while (this.expect(‘,‘)); } this.consume(‘]‘); return {type: AST.ArrayExpression, elements: elements}; };
2) AST.ObjectExpression 对象类型
--> this.object() 返回
AST.prototype.object = function() { var properties = []; if (!this.peek(‘}‘)) { do { var property = {type: AST.Property}; //key处理 if (this.peek().identifier) { property.key = this.identifier(); } else { property.key = this.constant(); } this.consume(‘:‘); //value的primary处理 property.value = this.assignment(); properties.push(property); } while (this.expect(‘,‘)); } this.consume(‘}‘); return {type: AST.ObjectExpression, properties: properties}; };
3)AST.Identifier和AST.Literal
标识符和字面量的处理
{type: AST.Identifier, name: this.consume().text}
{type: AST.Literal, value: this.consume().value}
primary中,除了上述三种以外,仍有key.value;key[‘value‘];key();三种类型的表达式需要处理。
具体地构建两种类型的节点:AST.MemberExpression;AST.CallExpression。构建过程需递归处理key和value
while((next = this.expect(‘.‘,‘[‘,‘(‘))){ if(next.text === ‘[‘){ primary = { type: AST.MemberExpression, object: primary, //注意[]内的量需要重新primary确定 property: this.primary(), computed: true }; this.consume(‘]‘); } else if(next.text === ‘.‘){ primary = { type: AST.MemberExpression, object: primary, //.的时候只能采用identifier,无需再primary property: this.identifier(), computed: false }; } else if(next.text === ‘(‘){ primary = { type: AST.CallExpression, callee: primary, arguments: this.parseArguments() //函数形参 } this.consume(‘)‘); } }
AST Compiler编译函数,关键是对AST树进行编译,即进行递归处理。核心函数compile返回的是new Function()
返回:
new Function(*,*,fnString)(*,*)
其中,fnString作为新返回函数的函数体,其构成实际上即为一组解析后的字符串。
函数体内部定义var fn;并且将其返回。
var fnString = ‘var fn=function(s,l){‘ + (this.state.vars.length ? ‘var ‘ + this.state.vars.join(‘,‘) + ‘;‘ : ‘‘ ) + this.state.body.join(‘‘) + ‘}; return fn;‘;
关键是this.state.body.join(‘‘),编译出的内容均存放在state.body中。
编译函数为:ASTCompiler.prototype.recurse
根据AST树种的type类型进行依次处理
ASTCompiler.prototype.recurse = function(ast, context, create) { var intoId; switch (ast.type) { case AST.Program: //
case AST.Literal:
// case AST.ArrayExpression: //case AST.ObjectExpression: //case AST.Identifier: //case AST.ThisExpression: //case AST.CallExpression: //case AST.AssignmentExpression: //case AST.UnaryExpression: //case AST.LogicalExpression: // };
1)AST.Program
根节点:作用是分派递归recurse处理state的body。
2)AST.Literal
字面量:如果是字符串,返回的是‘\‘‘ + value + ‘\‘‘,否则返回的是其value值。
3)AST.ArrayExpression
数组:递归rescure处理数组的每一项,返回
‘[‘ + elements.join(‘,‘) + ‘]‘;
4) AST.ObjectExpression
对象:递归rescure处理对象的每一个value,返回
var properties = _.map(ast.properties, _.bind(function(property) { var key = property.key.type === AST.Identifier ? property.key.name : this.escape(property.key.value); var value = this.recurse(property.value); return key + ‘:‘ + value; }, this)); return ‘{‘ + properties.join(‘,‘) + ‘}‘;
5) AST.Identifier
标识符:判断标识符是否在‘l‘或者‘s’作用域上,如果有返回获取标识符值得字符串标识。
this.if_(this.getHasOwnProperty(‘l‘, ast.name), this.assign(intoId, this.nonComputedMember(‘l‘, ast.name)));
ASTCompiler.prototype.getHasOwnProperty = function(object, property) { return object + ‘&&(‘ + this.escape(property) + ‘ in ‘ + object + ‘)‘; }; ASTCompiler.prototype.nonComputedMember = function(left, right) { return ‘(‘ + left + ‘).‘ + right; //返回的标识符值为类似 ‘(scope).key‘ };
6)AST.ThisExpression
this对象。由返回的var fn = function(s)中的s来实现,简单的
return ‘s‘;
即可。
7) AST.MemberExpression
成员表达式。
根据表达式的类型:key.value还是key[value],存在两种类型的处理方法。一种是上文提到的nonComputedMember。另一种是需要计算的。即:
return ‘(‘ + left + ‘)[‘ + right + ‘]‘;
其中,left直接进行rescure递归操作,而right则根据是否需要计算,来确定是否需要rescure操作。
8) AST.CallExpression
函数调用:重新构造一下arguments,返回:
return callee + ‘&&‘ + callee + ‘(‘ + args.join(‘,‘) + ‘)‘;
9) AST.AssignmentExpression
赋值表达式
return this.assign(leftExpr, ‘‘ + this.recurse(ast.right));
其中,assign函数为赋值表达式,本质上返回的即是一个字符串形式的赋值语句。
10) AST.UnaryExpression、AST.BinaryExpression、AST.LogicalExpression
操作符表达式;本质上即使将对应的操作符与相应的rescure后的内容进行组合:
case AST.UnaryExpression: return ast.operator + ‘(‘ + this.recurse(ast.argument) + ‘)‘; case AST.BinaryExpression: if (ast.operator === ‘+‘ || ast.operator === ‘-‘) { return ‘(‘ + this.recurse(ast.left) + ‘)‘ + ast.operator + ‘(‘ + this.recurse(ast.right) + ‘)‘; } else { return ‘(‘ + this.recurse(ast.left) + ‘)‘ + ast.operator + ‘(‘ + this.recurse(ast.right) + ‘)‘; } break; case AST.LogicalExpression: intoId = this.nextId(); this.state.body.push(this.assign(intoId, this.recurse(ast.left))); this.if_(ast.operator === ‘&&‘ ? intoId : this.not(intoId), this.assign(intoId, this.recurse(ast.right))); return intoId;
Parser
上述三个函数,最终通过Parser构造函数融合在一起
function Parser(lexer) { this.lexer = lexer; this.ast = new AST(this.lexer); this.astCompiler = new ASTCompiler(this.ast); } Parser.prototype.parse = function(text) { return this.astCompiler.compile(text); }; function parse(expr) { var lexer = new Lexer(); var parser = new Parser(lexer); return parser.parse(expr); }
采用流程图的形式表示上述内容如下:
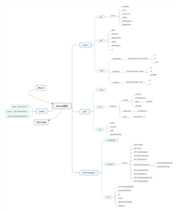
原文:http://www.cnblogs.com/lightsun/p/6362490.html