
IJCAI-17 口碑商家客流量预测 第 1 赛季截止日期 2017/03/14
重要时间
2月8日 08:00: 评测启动
3月7日 10:00: 报名截止&队伍融合截止
3月8日16:00: 更新评测集
3月14日 16:00: 最后一次评测触发 & 比赛结束
3月19日 23:59: 代码 & 解题思路提交截止
3月24日 10:00: 获胜队伍公布
参赛对象
面向全社会开放,高等院校、科研单位、互联网企业等人员均可报名参赛。
注:大赛主办和协办单位,以及有机会接触赛题背景业务及数据的员工,则自动退出比赛,放弃参赛资格;
阿里巴巴集团、蚂蚁金服、菜鸟的员工参赛,可参与排名,但不得领取奖金。
组队规则
参赛队伍可以是单人组队或自由组合,但最多不超过三人。3月7日10:00后将不再允许队伍的融合/拆分。
注:
1、每人只能参加一支队伍;
2、保证参赛队员报名信息准确有效,不得使用小号,否则会被取消参赛资格及激励;
3、报名方式:用淘宝或阿里云账号登入官网,完成个人信息注册,即可报名参赛。
评测
2月8日-3月7日:评测将在每天的8:00, 16:00 和24:00 触发 。评测触发前可多次提交,新版本将覆盖原版本;
3月8日-3月14日:评测将在每天的16:00 触发,评测触发前可多次提交,新版本将覆盖原版本;
最终线上成绩与排名以3月14日16:00排行榜成绩与排名为准;
奖项设置及激励
冠军:1支队伍,USD 10,000
亚军:1支队伍,USD 6,000
季军:1支队伍,USD 4,000
特别奖:2支队伍,USD 4,000 /队 (该奖项面向top20 内的队伍开放,作为参会差旅赞助提供,我们将基于提交的资料进行选拔:代码+解题思路+英文presentation资料)
最具潜力奖:价值2000美元的奖学金;
大赛教育合作方优达学城,将为被评为“最具潜力”的队伍提供价值超过2000美元的奖学金,可用于学习由 Google、Facebook、亚马逊等硅谷行业领导者推出的人工智能、机器学习、数据科学学习认证项目。
阳光普照奖:所有选手获得价值500元的新人学习红包
大赛教育合作方优达学城将为所有报名成功的用户,提供价值约500元的新人学习红包,可用于抵扣首次加入 Google、Facebook、亚马逊等硅谷行业领导者推出的人工智能、机器学习、数据科学等学习认证项目时的学费。(仅可用于优达学城中国区网站 cn.udacity.com。)
Top 3 队伍将获得3,000美元/队的差旅赞助,前往于8月份在墨尔本举办的IJCAI-17主会.
积分发放: 在比赛中产出过成绩的队伍,根据排行榜最终排名,按天池积分公式获得相应积分
粮票发放: 在比赛中产出过成绩的队伍,根据排行榜最终排名获得相应粮票:
第1-10名队伍:11000粮票
第11-50名队伍:2500粮票
第51-100名队伍:1200粮票
随着移动定位服务的流行,阿里巴巴和蚂蚁金服逐渐积累了来自用户和商家的海量线上线下交易数据。蚂蚁金服的O2O平台“口碑”用这些数据为商家提供了包括交易统计,销售分析和销售建议等定制的后端商业智能服务。举例来说,口碑致力于为每个商家提供销售预测。基于预测结果,商家可以优化运营,降低成本,并改善用户体验。
这次比赛中,我们将以恰当定义的销售预测问题为题。 我们鼓励创新的解法,帮助口碑成为更加智能的商业平台,更好地服务社会。同时,希望每位参赛选手都能享受到这次比赛带来的乐趣。
预测客户流量对商家的经营管理至关重要。在口碑平台上,我们将客户流量定义为“单位时间内在商家使用支付宝消费的用户人次”。在这个问题中,我们将提供用户的浏览和支付历史,以及商家相关信息,并希望参赛选手可以以此预测所有商家在接下来14天内,每天的客户流量。
我们鼓励参赛选手使用类似天气等额外的数据,并希望参赛选手能够将数据源共享在论坛中。
在这次比赛中,每只队伍需要预测测试集中所有商家在未来14天(2016.11.01-2016.11.14)内各自每天(00:00:00-23:59:59)的客户流量。预测结果为非负整数。
我们提供从2015.07.01到2016.10.31(除去2015.12.12)的商家数据,用户支付行为数据以及用户浏览行为数据。提供数据的类型统一为string类型,提交预测的类型为整形。文件统一为utf-8编码,没有标题行,并以“,”分隔的csv格式。
1. shop_info:商家特征数据
|
Field |
Sample |
Description |
|
shop_id |
000001 |
商家id |
|
city_name |
北京 |
市名 |
|
location_id |
001 |
所在位置编号,位置接近的商家具有相同的编号 |
|
per_pay |
3 |
人均消费(数值越大消费越高) |
|
score |
1 |
评分(数值越大评分越高) |
|
comment_cnt |
2 |
评论数(数值越大评论数越多) |
|
shop_level |
1 |
门店等级(数值越大门店等级越高) |
|
cate_1_name |
美食 |
一级品类名称 |
|
cate_2_name |
小吃 |
二级分类名称 |
|
cate_3_name |
其他小吃 |
三级分类名称 |
2. user_pay:用户支付行为
|
Field |
Sample |
Description |
|
user_id |
0000000001 |
用户id |
|
shop_id |
000001 |
商家id,与shop_info对应 |
|
time_stamp |
2015-10-10 11:00:00 |
支付时间 |
3. user_view:用户浏览行为
|
Field |
Sample |
Description |
|
user_id |
0000000001 |
用户id |
|
shop_id |
000001 |
商家id,与shop_info对应 |
|
time_stamp |
2015-10-10 10:00:00 |
浏览时间 |
4. prediction:测试集与提交格式
|
Field |
Sample |
Description |
|
shop_id |
000001 |
商家id |
|
day_1 |
25.1 |
第1天的预测值( 需要选手提供) |
|
day_2 |
3.55555 |
第2天的预测值(需要选手提供) |
|
…… |
|
|
|
day_14 |
1024.0 |
第14天的预测值( 需要选手提供)
|
1.Q:time_stamp的编码格式?
A:所有时间统一为“yyyy-mm-dd hh:mi:ss”格式。其中yyyy表示年,mm表示月,dd表示日,hh表示小时,mi表示分钟,ss表示秒。
2.Q:空值的表示方式?
A:数据文件中,两个逗号间没有内容即表示该属性为空。例如,“2,哈尔滨,64,19,,,1,超市便利店,超市,” 对应为:
|
Field |
Sample |
|
shop_id |
2 |
|
city_name |
哈尔滨 |
|
location_id |
64 |
|
per_pay |
19 |
|
score |
NULL |
|
comment_cnt |
NULL |
|
shop_level |
1 |
|
cate_1_name |
超市便利店 |
|
cate_2_name |
超市 |
|
cate_3_name |
NULL |
3.Q:空值的意义?
A:score,comment_cnt属性的空值代表没有人进行过评分或评论。cate_3_name属性的空值代表不存在第三级分类。
4.Q:文件的编码方式?
A:所有文件均采用UTF-8编码。
5.Q:提交结果后Loss显示为NaN?
A:NaN代表您的提交存在错误。请检查提交文件内容的完整性,以及格式的正确性。可以参考prediction_example.csv的格式。
首先请确认shop_id是否正确。shop_id应该为1至2000的整数值。缺少或异常的shop_id都会导致提交错误。
其次请确认预测结果格式是否正确。预测结果应为非负整数,而且不能为空。
6.Q:如果真实客户流量为0,提交预测结果也为0,则loss为?
A:Loss定义为0。
7.Q:数据时间段的问题?
A:user_pay表的具体数据时间范围是2015-06-26 06:00:00至2016-10-31 23:00:00。
user_view表的具体数据时间范围是2016-06-22 00:00:00至2016-10-31 23:00:00。
extra_user_view是额外提供的用户浏览数据,其数据结构同user_view表相同,其具体数据时间范围是2016-02-01 00:00:00至2016-06-21 23:00:00。
user_pay表中,存在某些商家在某一时间区间内没有用户支付行为的情况。这是由于该商家在该时间段因某些原因没有正常经营导致的。
我们保证在预测区间2016.11.01-2016.11.14内,所有商家都在正常经营。
8.Q:数据的详细描述?
A:user_pay表是用户线下(非外卖消费,是到店消费)前往口碑店铺使用支付宝进行消费的记录。
user_view表是用户线上在口碑平台浏览商家产生的记录。浏览行为指点击进入商家详情页浏览的行为。
shop_info中,处于同一个location_id的商家相互距离小于2km,而且location_id本身没有实际意义。
shop_level是口碑平台对商家规模的一个评价指标,例如个体餐饮商家的门店等级低于大型全国连锁的商家。
9.Q:如果一个用户在一天内在某商家里支付了2次,那么客户流量算2还是1?
A:2。每次支付算一次做客户流量。
10.Q:数据共享的问题?
A:首先,数据渠道必须公开,处理思路也要描述。其次,是否上传具体分析。
举例来说:
处理过的公开爬取的数据最后需上传提交,是否在论坛公开由参赛者自行决定。
如果使用付费数据,不必上传,也不必公开。只要说明来源和处理思路即可。
1、目的:预测 所有店铺 (2000家)在2016.11.01-2016.11.14(14天)内 各自每天(00:00:00-23:59:59)的客户流量。预测结果为非负整数。
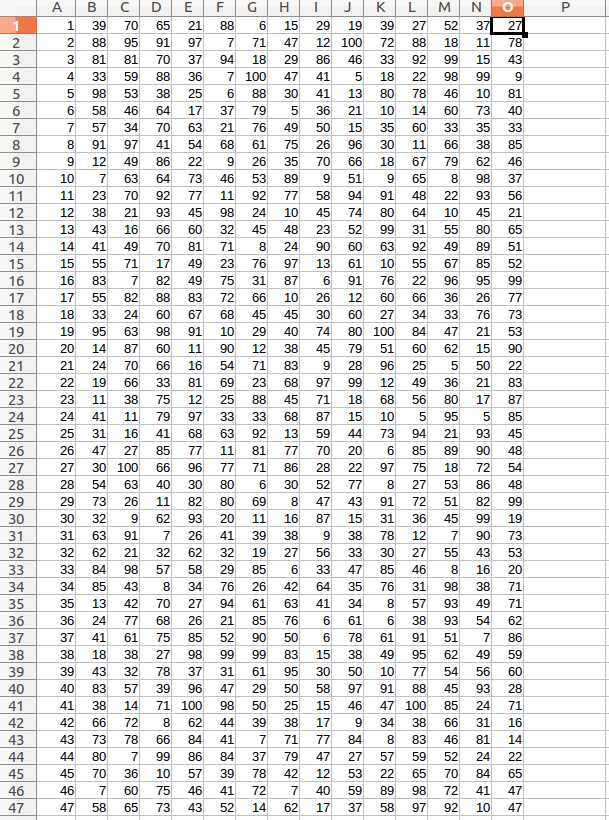
一共2000行,每行第一列A代表shop_id商家的id,第二列B到第十五列O代表未来14天,每天的客流量
2、知道要做什么了,然后开始着手做,第一步:观察先用的数据集
1. shop_info:商家特征数据
|
Field |
Sample |
Description |
|
shop_id |
000001 |
商家id |
|
city_name |
北京 |
市名 |
|
location_id |
001 |
所在位置编号,位置接近的商家具有相同的编号 |
|
per_pay |
3 |
人均消费(数值越大消费越高) |
|
score |
1 |
评分(数值越大评分越高) |
|
comment_cnt |
2 |
评论数(数值越大评论数越多) |
|
shop_level |
1 |
门店等级(数值越大门店等级越高) |
|
cate_1_name |
美食 |
一级品类名称 |
|
cate_2_name |
小吃 |
二级分类名称 |
|
cate_3_name |
其他小吃 |
三级分类名称 |
2. user_pay:用户支付行为
|
Field |
Sample |
Description |
|
user_id |
0000000001 |
用户id |
|
shop_id |
000001 |
商家id,与shop_info对应 |
|
time_stamp |
2015-10-10 11:00:00 |
支付时间 |
3. user_view:用户浏览行为
|
Field |
Sample |
Description |
|
user_id |
0000000001 |
用户id |
|
shop_id |
000001 |
商家id,与shop_info对应 |
|
time_stamp |
2015-10-10 10:00:00 |
浏览时间
|
现在有这三个表,一个是商户特征数据,一个是用户支付行为,还有一个是用户浏览行为
发现没有最主要的 label 客户流量
所以现在首先应该处理数据
我们现在想知道的是:
1、2000 家 商户 在 2015.07.01 - 2016.10.31 每天有多少个用户发生支付行为?
2、影响支付数量也就是客户流量的原因是什么?
3、预测 2000 家商户 在 2016.11.01 - 2016.11.14(14天)每天的客户流量
原文:http://www.cnblogs.com/custer/p/6370930.html