Sqoop提供的--fields-terminated-by选项可以支持指定自定义的分隔符,但是它只支持单字节的分隔符,对于我们特殊的需求:希望使用双字节的“|!”,默认的是不支持的。
Sqoop在进行每一次的导出任务时,都会调用codegen,生成一个java文件,并编译打包成一个jar,供MapReduce使用。这个java文件包装了一系列的对导出数据的访问接口,我们可以尝试通过对这个java文件进行分析,找到指定双字节分隔符的方法。
一般地,如果是使用的--query用查询语句获取数据,生成的文件为QueryResult.java,QueryResult.jar,如果使用的是--table,则用指定的表名对相应文件命名。java文件生成在sqoop脚本的同一目录下。
对于下面的Sqoop任务,生成test_table.java。

1 sqoop import --connect jdbc:XXX/testdb --username user --password password --table test_table --split-by id --fields-terminated-by ‘#‘
对于test_table.java做代码分析:
首先,看下分隔符的定义():
1 DelimiterSet(char field, char record, char enclose, char escape, boolean isEncloseRequired){……}//分隔符集定义 2 3 private final DelimiterSet __outputDelimiters = new DelimiterSet((char) 35, (char) 10, (char) 0, (char) 0, false);// 根据用户输入信息,定义当前分隔符
第一行,分隔符集定义,依次是 fields-terminated-by lines-terminated-by enclosed-by escaped-by,最后一个如果为true,enclosed-by会应用到所有字段,如果为false,只对fields that embed delimiters生效。
注意上面DelimiterSet定义语句,使用的是ASCII对照表。
所以,根据ASCII码表,第二行就很明白了,35是我们指定的‘#‘的ASCII码值。这里在研究的时候,用到一个trick,就是自己指定一个‘#’作为标记,然后从java代码里面找这个‘#’,它在哪里,就是我们关注的“有效”代码段。
如果,不指定分隔符为‘#’的话,上面的__outputDelimiters 是下面的样子。
1 private final DelimiterSet __outputDelimiters = new DelimiterSet((char) 44, (char) 10, (char) 0, (char) 0, false);// 默认分隔符
44即ASCII表示的‘,’。默认的分隔符,字段用逗号“,”,行用回车“\r\n”。
分隔符的定义搞明白了,接下来看下输出。Sqoop毕竟只是个中间处理环节,最后要数据到指定的目的地。经过几个toString跳转之后,看下面的代码段:
1 public String toString(DelimiterSet delimiters, boolean useRecordDelim) { 2 StringBuilder __sb = new StringBuilder(); 3 char fieldDelim = delimiters.getFieldsTerminatedBy(); 4 __sb.append(FieldFormatter.escapeAndEnclose(id==null?"null":"" + id, delimiters)); 5 __sb.append(fieldDelim); 6 __sb.append(FieldFormatter.escapeAndEnclose(app_no==null?"null":app_no, delimiters)); 7 __sb.append(fieldDelim); 8 9 ……………… 10 __sb.append(FieldFormatter.escapeAndEnclose(seq==null?"null":"" + seq, delimiters)); 11 if (useRecordDelim) { 12 __sb.append(delimiters.getLinesTerminatedBy()); 13 } 14 return __sb.toString(); 15 }
这里fieldDelim从之前定义的分隔符集中获取了字段分隔符,然后拼字符串的方式,在每个字段值后面,附加一个字段分隔符。
看到这里,我们就有思路了,只要把这里fieldDelim的赋值做一下修改,赋值为“|!",就可以达到我们的目的。
于是,修改此处代码如下(也是唯一的一处修改):
1 public String toString(DelimiterSet delimiters, boolean useRecordDelim) { 2 StringBuilder __sb = new StringBuilder(); 3 String fieldDelim = “|!”; 4 __sb.append(FieldFormatter.escapeAndEnclose(id==null?"null":"" + id, delimiters)); 5 __sb.append(fieldDelim); 6 __sb.append(FieldFormatter.escapeAndEnclose(app_no==null?"null":app_no, delimiters)); 7 __sb.append(fieldDelim); 8 ………… 9 }
接下来,对修改的test_table.java进行编译。
关于如何编译的问题,通过跟踪sqoop import执行的时候的输出日志:
1 14/05/23 10:55:07 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 2 14/05/23 10:55:07 WARN sqoop.ConnFactory: Parameter --driver is set to an explicit driver however appropriate connection manager is not being set (via --connection-manager). Sqoop is going to fall back to org.apache.sqoop.manager.GenericJdbcManager. Please specify explicitly which connection manager should be used next time. 3 14/05/23 10:55:07 INFO manager.SqlManager: Using default fetchSize of 1000 4 14/05/23 10:55:07 INFO tool.CodeGenTool: Beginning code generation 5 14/05/23 10:55:08 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM test_table AS t WHERE 1=0 6 14/05/23 10:55:08 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM test_table AS t WHERE 1=0 7 14/05/23 10:55:08 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/lib/hadoop 8 14/05/23 10:55:08 INFO orm.CompilationManager: Found hadoop core jar at: /usr/lib/hadoop/hadoop-core.jar 9 14/05/23 10:55:09 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/3c33c9978c6103e610bf0f4a26fd92fa/test_table.jar 10 14/05/23 10:55:09 INFO mapreduce.ImportJobBase: Beginning import of test_table
通过上面高亮区域提供的信息,得到修改后的java代码的编译及打包方法如下:
1 javac -cp ./:/usr/lib/hadoop/hadoop-core.jar:/usr/lib/sqoop/sqoop-1.4.3.jar test_table.java 2 jar -cf test_table.jar test_table.class
打包完毕后,需要在使用Sqoop进行数据导出的时候,进行jar包的指定,指定的方式如下:
1 sqoop import --connect jdbc:XXX/testdb --username user --password password --table test_table --split-by id --jar-file /path/test_table.jar --class-name test_table
使用的选项为--jar-file和--class-name,其中--jar-file指定了jar的全路径,--class-name指定了用到的包中的java类。
以下是使用修改后的java文件实现的双字节分隔符导出结果。
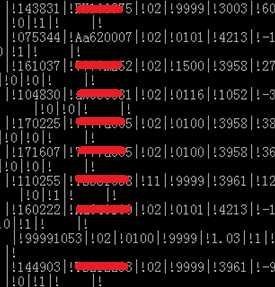
再谈一下效率。使用这种自定义分隔符,自己手动生成的jar包做数据导入,测试数据5000w:
第一次:17min21sec
第二次:15min42sec
如果不指定jar,默认地执行,按照之前侧过的数据,分别是12min58sec,14min19sec。
看来使用这样的方式,还是对效率有一定的影响。但是也有可能是晚上7点数据库服务器做批量有关,后续要再做实验判定下。
Sqoop自定义多字节列分隔符,布布扣,bubuko.com
原文:http://www.cnblogs.com/YFYkuner/p/3748495.html