超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准
HTTP是一个基于TCP/IP通信协议来传输数据(HTML文件、图片文件、查询结果)
HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。(请求的数据往往比较小,而返回的数据往往比较大。因为返回的数据中包含了Body)
HTTP是无状态的 FTP是有状态的
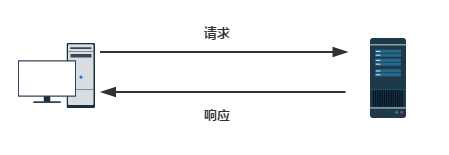
为什么要学习http协议
主要是为了方便后面openstack的搭建,因为openstack中各个组件间相互通信就是基于restful api的,restful api 可以理解为一个url地址 也就是http协议进行通信的
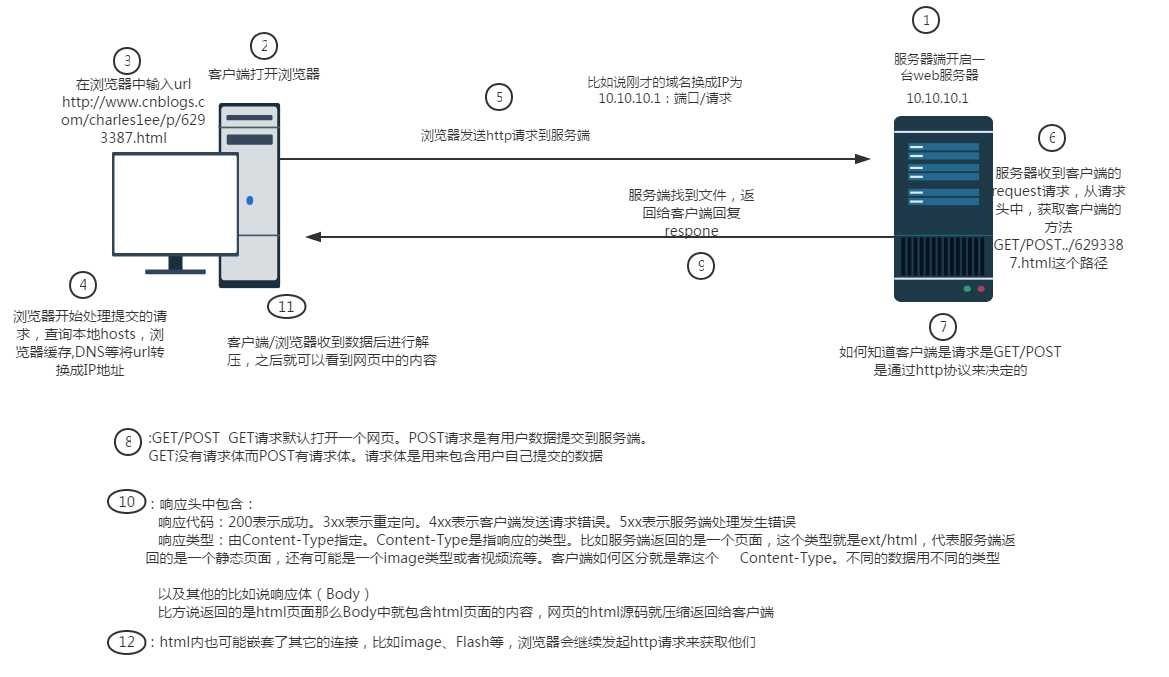
用户是如何访问到浏览器中的文件呢?
看下图
HTTP1.1 与1.0的区别
1.HTTP/1.0协议使用非持久连接,即在非持久连接下,一个tcp连接只传输一个Web对象,;
2.HTTP/1.1默认使用持久连接(然而,HTTP/1.1协议的客户机和服务器可以配置成使用非持久连接)。
在持久连接下,不必为每个Web对象的传送建立一个新的连接,一个连接中可以传输多个对象!
URL与URI
URL:(Unifrom/Universal Resource Locator)的缩写,即统一资源定位符
URI:(Uniform Resource Identifier)的缩写,即统一资源标识符 (代表一种标准)
URL:协议名://域名:端口 如http://www.cnblogs.com:80/
URI:协议名://域名:端口/路径 如http://www.cnblogs.com:80/index.html
请求协议
请求格式(即浏览器发给服务端的内容格式)

http://host[:port][abs_path][空行][请求体] http:表示要通过http协议来定位网络资源 host:表示合法的Internet主机域名或IP地址 port:用于指定一个端口号,拥有被请求资源的服务器主机监听该端口的TCP连接(如果port为空,则使用缺省的端口80)当服务器的端口不是80时,需要指定端口号 abs_path:指定请求资源的URI。 空行:用来与请求体分隔开 请求体:常用的就是GET或者POST(GET没有请求体,POST有请求体)
浏览器发送请求到服务器的内容就是这个格式,如果不是这个格式服务器无法解读。
GET请求:
HTTP默认请求就是GET
特点:
没有请求体(GET不夹杂用户提交的信息,例如用户名密码之类的这种隐私的信息)
请求数据必须在1K之内(socket协议规定)
GET请求的数据会暴露在浏览器的地址栏中
GET请求常用的操作
浏览器地址栏直接给出URL地址,就是GET请求
在页面上点击链接,也是一个GET请求
提交表单(例如登录在前端中from就是表单的意思)的时候默认时候是GET,但也可以设置为POST。在提交数据的时候基本上都是POST
实例
www.zhihu.com
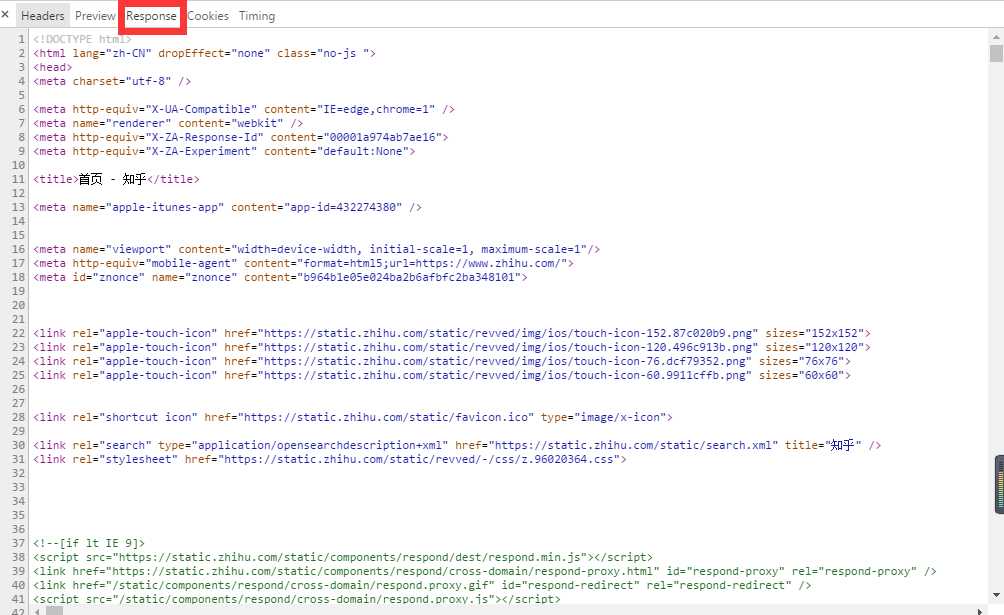
Response:返回体(用户获取的页面)
查看请求头信息
点击view source查看源码 如下图
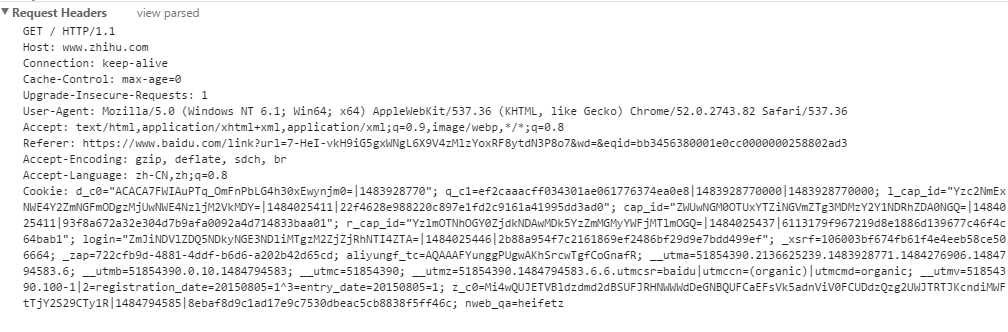
1:GET请求。 “/” 代表要访问的页面。 http协议1.1
2:Host访问的主机
3:链接类型:长连接
4:Upgrade-Insecure-Requests
5:user-agent:user客户端一些简单信息
6:accept:可以接收那些页面类型。(text/html、xml、image、等)
7:accept-encoding:字符编码(让计算机识字符)这里代表的是压缩格式
8:Accept-Language:支持的语言格式
9:Cookie:一个cookie对应一个session
10:If-Modified-Since:当客户端再次向服务器发起请求时并发送这个时间,服务器会根据自己的Last-Modified的时间对比,如果两者时间一样,那么浏览器会从本地提取缓存页面,大大缓解了服务器的性能
以上就是请求过程,客户端请求结束后,服务端会返回两个东西(一个是Response页面,另一个是响应头Response Headers)
查看响应头信息
点击view source查看源码 如下图
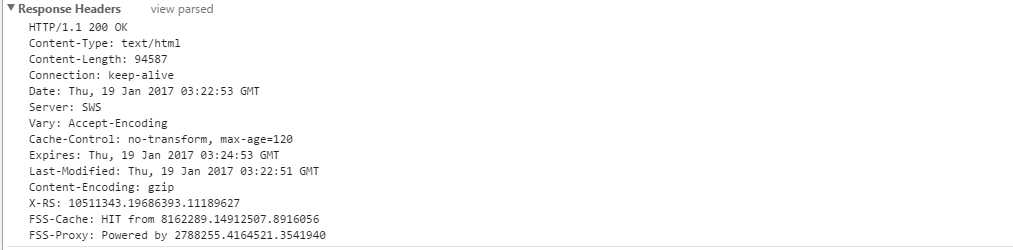
1:HTTP/1.1 200 ok 客户端收到http协议,返回状态码(请求成功)
2:Content-Type:返回到客户端的数据类型(返回什么类型,用什么方式解析这个类型)
3:Date:显示日期
4:SWS:网站主页所使用的web服务
5:Expires:缓存的过期时间
6:Last-modified:上次页面修改的时间
7:Content-Encoding:使用什么类型压缩Response内容
8:Content-Length:页面大小(不包含图片视频等,只包含连接)
以上就是响应头的简单介绍
一般信息
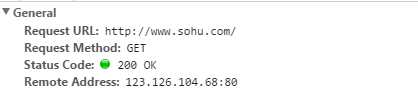
1:客户端请求的url地址
2:请求类型
3:状态码
4:远程地址
POST请求
特点:
1:数据不会出现在地址栏中
2:数据大小没上线
3:有请求体
4:请求体中如果有中文,会使用URL编码
实例
1 <!DOCTYPE html> 2 <html> 3 <body> 4 5 <form method="post"> 6 user:<br> 7 <input type="text" name="username"> 8 <br> 9 password:<br> 10 <input type="text" name="password"> 11 <input type="submit" value="login"> 12 </form> 13 14 </body> 15 </html> 16 17 #表单测试
在pycharm中测试
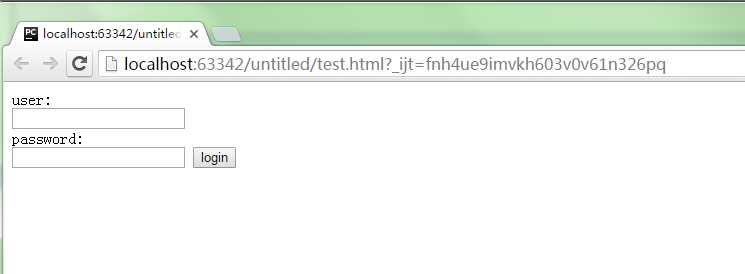
1 在地址栏中看到test.html是这个html文件
2 页面后面的"?"代表着get请求
如果默认请求是get方法的话在输入用户名与密码就会出现如下结果
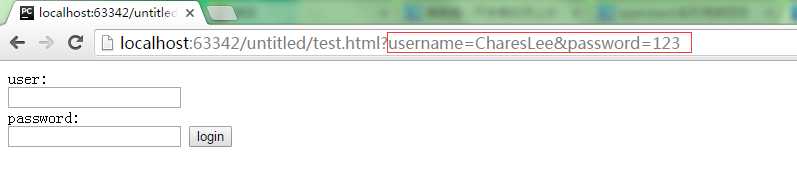
刚刚输入的用户名与密码打印到地址栏中了。这就是比较危险的了。但是如果设置为post请求就不会出现这种结果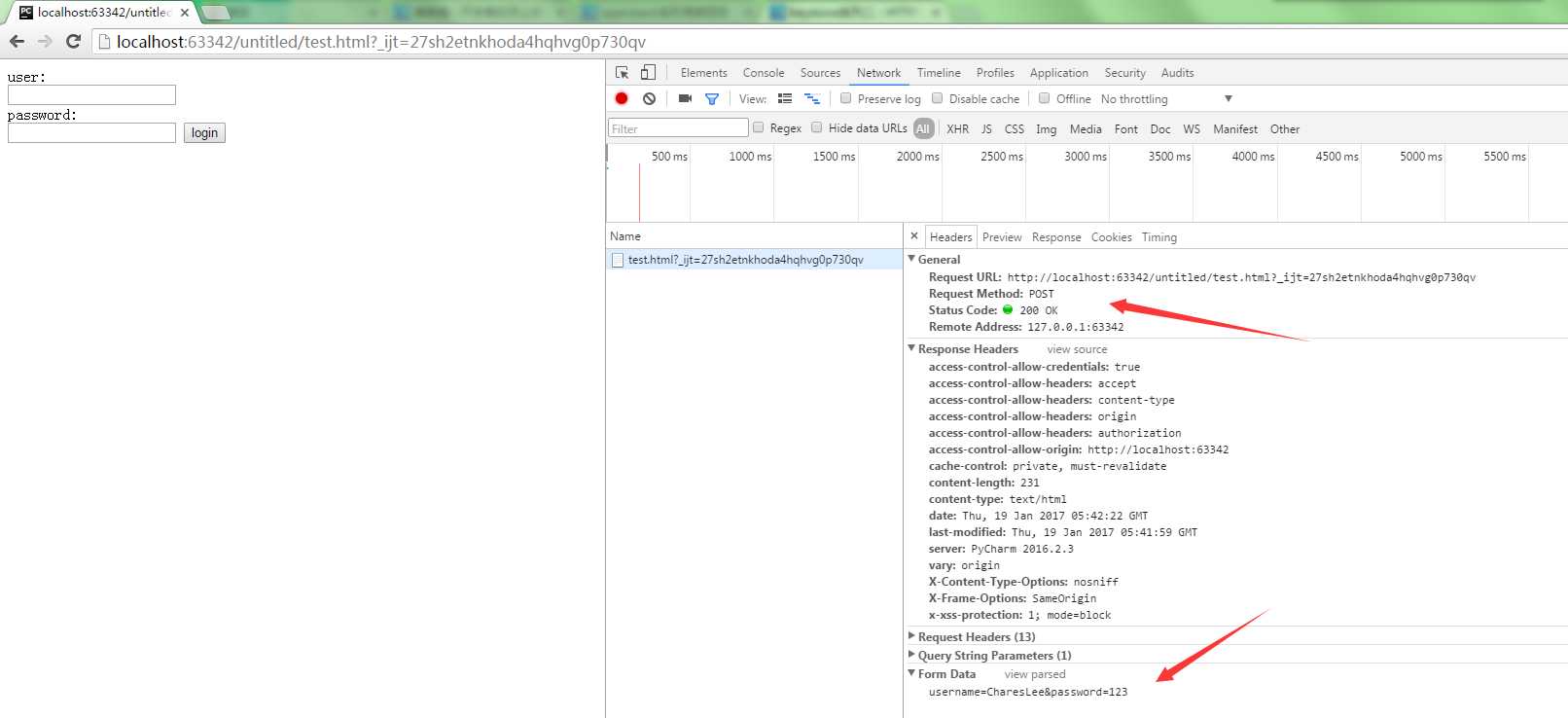
因此 post请求就不会将用户名与密码打印到地址栏中。而是浏览器帮你隐藏起来。在网页源码中的头信息中可以看到下面多了一个Form Data 这就是你提交上去的信息
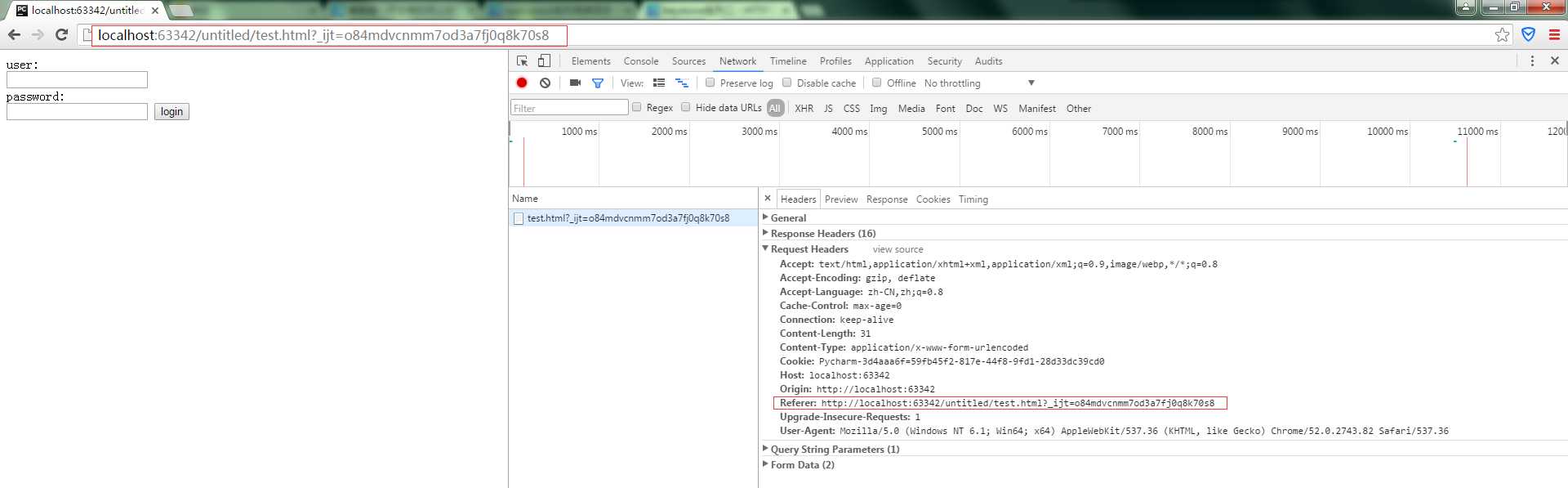
Referer:请求来自哪个页面那么如果在百度点击链接到这里,那么就是Referer://http:www.baidu.com;如果在浏览器中直接输入地址,则没有这个referer值(用于防盗链功能)
状态码
状态码的含义对于浏览器说很重要,返回不同的状态码有不同的含义。例如200表示响应成功,302,表示重定向等等
200:请求成功
3xx:重定向
4xx:客户端错误(401访问被拒绝。403禁止访问。404未找到页面等)
5xx:服务端错误(500内部服务器错误。503服务不可以。504网关超时等)
原文:http://www.cnblogs.com/Vae1242/p/6390182.html