爬取百度百科1000个页面的数据
1. 准备工作:
确定目标 => 分析目标(URL格式, 数据格式, 网页编码) => 编写代码 => 执行爬虫
1.1 链接分析:
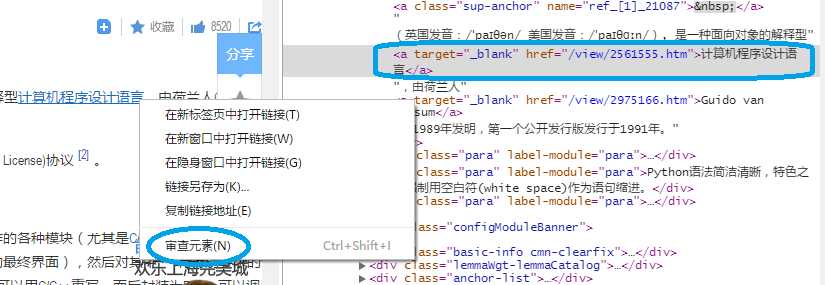
进入百度百科“Python”词条页面:http://baike.baidu.com/view/21087.htm => 在链接位置右键后,点击审查元素,
href="/view/2561555.htm" 是一个不完整的url, 在代码中需要拼接成完整的 baike.baidu.com/view/2561555.htm 才能进行后续的访问。
1.2 标题分析:
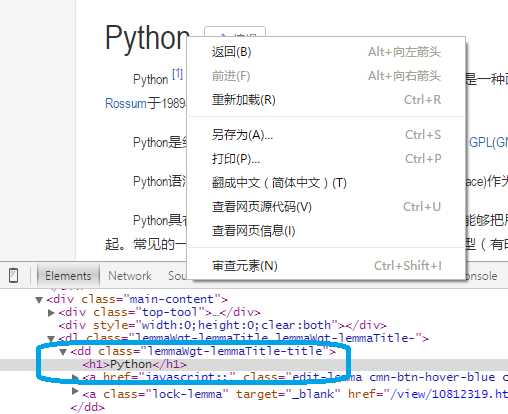
在标题位置右键后,点击审查元素。可看到标题内容在<dd class> 下的 <h1> 子标签中。
1.3 简介分析:
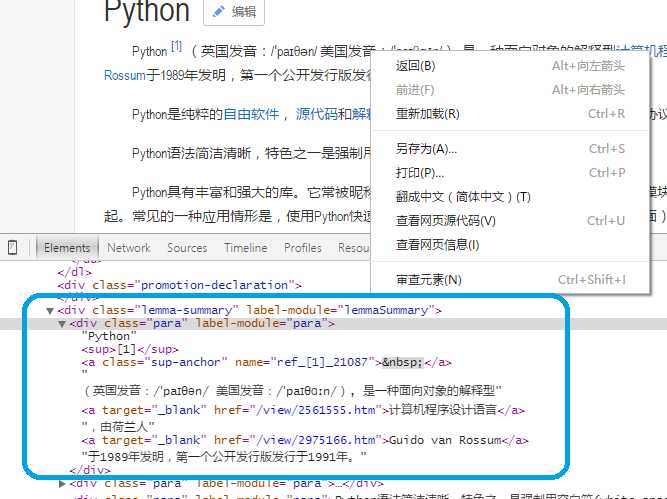
在简介位置右键后,点击审查元素。可看到简介内容在<class="lemma-summary"> 下。
1.4 查看编码方式:
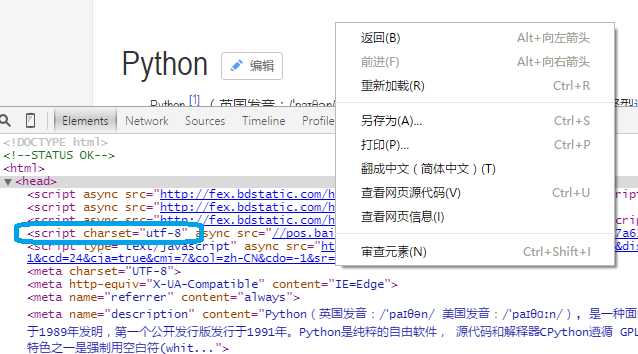
在空白位置右键后,点击审查元素。可看到编码方式在 script charset = “utf-8”
1.5 分析目标汇总:
a. 目标:百度百科Python词条相关词条网页 - 标题和简介
b. 入口页:http://baike.baidu.com/view/21087.htm
c. URL格式:词条页面URL:/view/125370.htm
d. 数据格式:
- 标题:<dd class="lemmaWgt-lemmaTitle-title"><h1>***</h1></dd>
- 简介:<div class= "lemma-summary">***<div>
e. 页面编码:UTF-8
2. 实例代码
2.1 调度程序:spyder_main.py
2.2 URL管理器:url_manager.py
2.3 HTML下载器:html_downloader.py
2.4 HTML解析器:html_parser.py
2.5 HTML输出器:html_outputer.py
原文:http://www.cnblogs.com/wnzhong/p/6397477.html