1.在代码中观察
val data = Array(1, 2, 3, 4, 5)
val distData = sc.parallelize(data)
val resultRDD = distData.flatMap(v => (1 to v)).map(v => (v%2,1)).reduceByKey(_+_)
resultRDD.toDebugString ## 查看RDD的依赖情况
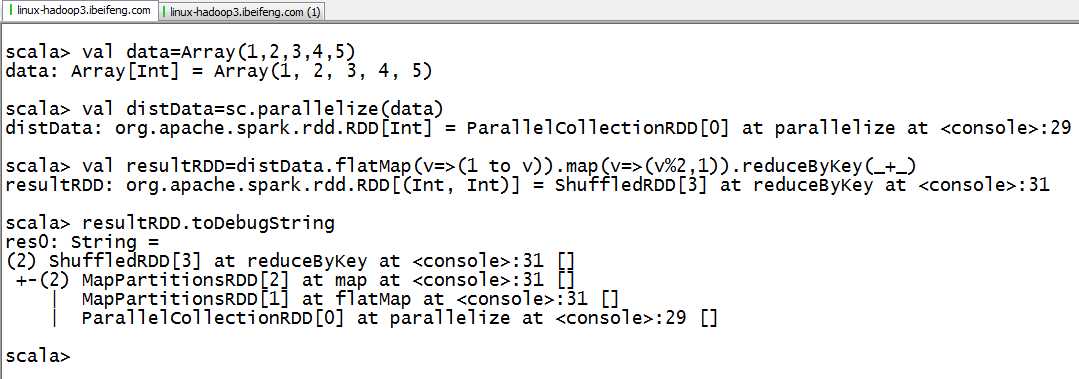
2.解释
+—处表示,这是两个不同的stage
同时可以知道shuffledRDD依赖于MapPartitionRDD,MapPartitionRDD依赖于MapPartitionRDD,MapPartitionRDD依赖于ParalleCollectionRDD
[2]表示有两个分区

3.RDD依赖
lineage: 生命线
依赖于RDD之间的依赖,后续的RDD数据是从之前的RDD中获取
由于存在RDD的依赖,当一个后续的RDD执行失败的情况下(某个Task执行失败,eg:数据丢失),可以从父RDD中重新执行
RDD依赖父RDD,依赖的父RDD可以有多个;
特例:第一个RDD是没有父RDD的
RDD的内部是由多个Partiiton构成的,所以RDD的依赖实质上就是RDD中Partition的依赖关系
4.依赖的情况
当前RDD中的每个分区的数据到下一个RDD都对应一个分区
即:一个分区的数据输出到下一个RDD的时候还是在同一个分区,也就是一对一
当前RDD中的多个分区的数据到下一个RDD的时候输出到同一个分区,当前RDD的中一个分区的数据到下一个RDD的时候输出到多个分区,也就是多对多
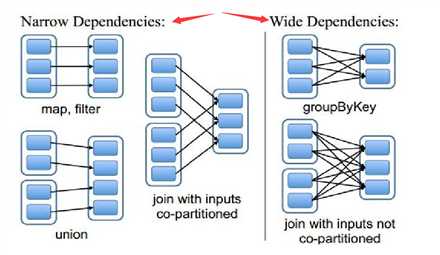
5.依赖分类
窄依赖:
子RDD中的每个分区的数据都来自于常数个父RDD的分区,而且父RDD每个分区的数据到子RDD的时候一定在一个分区中
不存在shuffle过程,所有操作在一起进行
宽依赖:
子RDD中的每个分区的数据都依赖所有父RDD的所有的分区数据,而且父RDD的每个分区的数据到子RDD的时候不一定在一个分区中
存在shuffle过程,需要等待上一个RDD的所有Task执行完成

原文:http://www.cnblogs.com/juncaoit/p/6399103.html