链接:http://www.p2p001.com/licai/index/id/147.html
所需获取数据链接类似于:http://www.p2p001.com/licai/shownews/id/454.html:
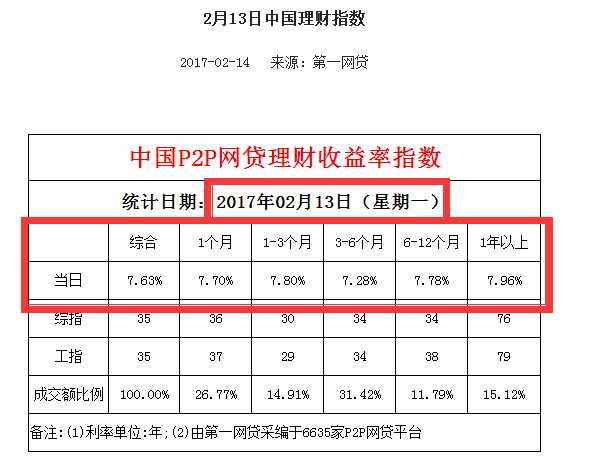
库:
#coding utf-8 import requests import re import pandas from bs4 import BeautifulSoup user_agent = ‘User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)‘ headers = {‘User-Agent‘:user_agent} #定义函数,得到每日报的链接,并以列表形式返回 def get_newsurl(): newsurl=[] url1=‘http://www.p2p001.com/licai/index/id/147/p/‘ num=1 url2=‘.html‘ while num<=22: url=url1+str(num)+url2 try: r1=requests.get(url,headers=headers) except: print (‘wrong %s‘ % url) else: s1=BeautifulSoup(r1.text,‘lxml‘) for x in s1.find_all(href=re.compile(‘licai/shownews‘)): newsurl.append(x[‘href‘]) num=num+1 return newsurl #定义函数,得到的数据,以字典形式返回 def get_info(): url=‘http://www.p2p001.com‘ date=[] zonghe=[] one=[] one_three=[] three_six=[] six_twelve=[] twelve_most=[] for y in get_newsurl(): try: main_url=url+y r2=requests.get(main_url,headers=headers) except: print (‘wrong %s‘ % main_url) else: s2=BeautifulSoup(r2.text,‘lxml‘) date.append(s2.find(text=re.compile(‘统计日期‘))[5:]) rate=s2.find_all(‘td‘) zonghe.append(rate[10].string) one.append(rate[11].string) one_three.append(rate[12].string) three_six.append(rate[13].string) six_twelve.append(rate[14].string) twelve_most.append(rate[15].string) p={‘Date‘:date, ‘综合‘:zonghe, ‘1个月‘:one, ‘1-3个月‘:one_three, ‘3-6个月‘:three_six, ‘6-12个月‘:six_twelve, ‘12个月及以上‘:twelve_most} return p #pandas存储数据 p=pd.DataFrame(get_info())
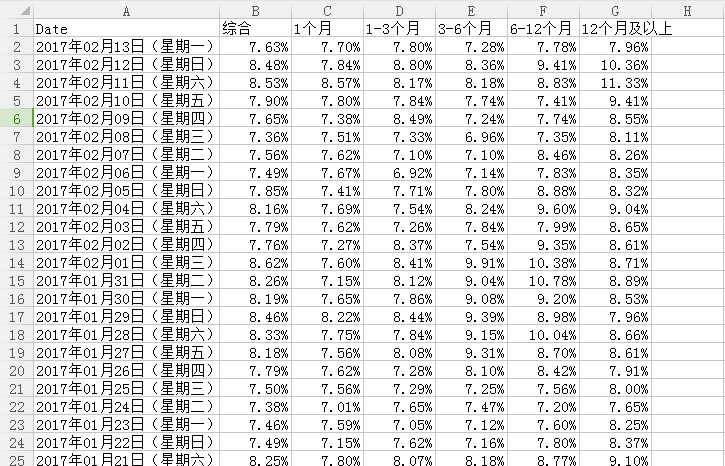
此次学习总结及反思:
1.为了方便处理,并没有使用数据库来存储数据,而是使用pandas将数据以csv格式保存在本地硬盘F
2.定义第一个函数对象get_newsurl,以列表形式返回理财指数日报链接,第二个函数遍历第一个函数的返回值,进行数据的采集
3.为什么不将pandas的一系列操作放在函数对象get_info中,从而直接完成一系列的操作呢?
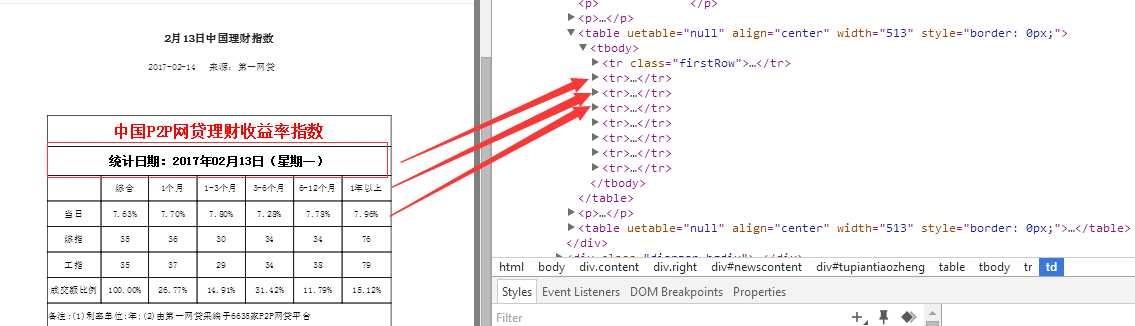
③处理并存储数据(pandas)
注明:数据来源于第一网贷http://www.p2p001.com/
原文:http://www.cnblogs.com/buddyquan/p/6399442.html