本課主題
- Spark 天堂之门
- Spark 天堂之门源码分享
Spark天堂之门:SparkContext
- Spark 程序在運行的時候分為 Driver 和 Executor 兩部分
- Spark 程序編寫是基於 SparkContext 的,具體來說包含兩方面
- Spark 編程的核心 基礎-RDD 是由 SparkContext 來最初創建的(第一個RDD一定是由 SparkContext 來創建的)
- Spark 程序的調度優化也要基於 SparkContext,首先進行調度優化。
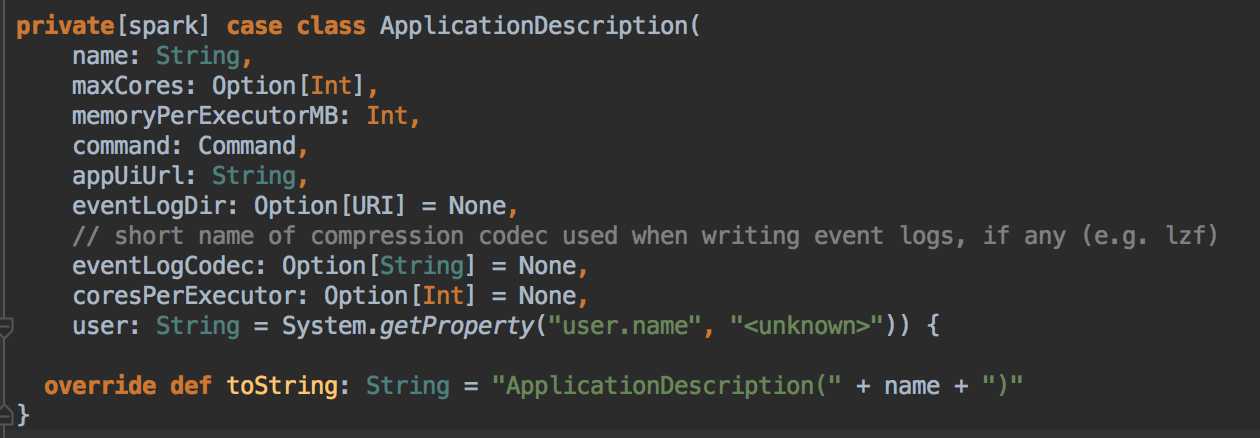
- Spark 程序的注冊時通過 SparkContext 實例化時候生產的對象來完成的(其實是 SchedulerBackend 來注冊程序)
- Spark 程序在運行的時候要通過 Cluster Manager 獲取具體的計算資源,計算資源獲取也是通過 SparkContext 產生的對象來申請的(其實是 SchedulerBackend 來獲取計算資源的)
- SparkContext 崩潰或者結束的是偶整個 Spark 程序也結束啦!
SparkContext 使用案例
Spark 天堂內幕
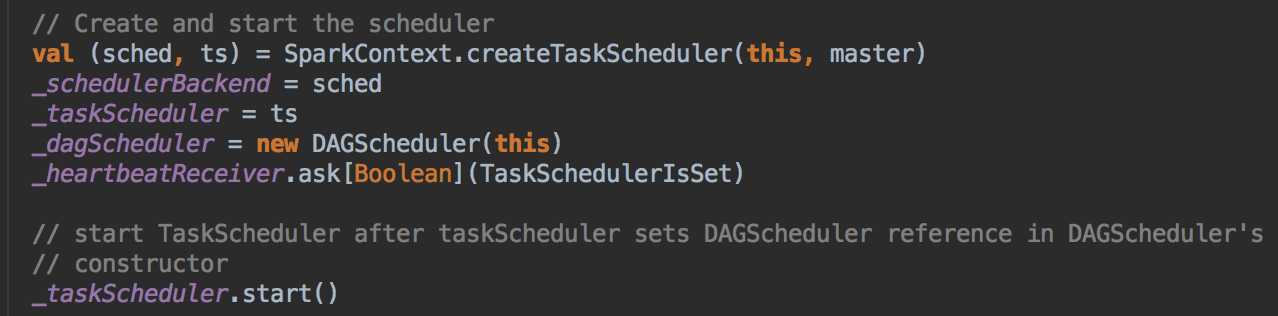
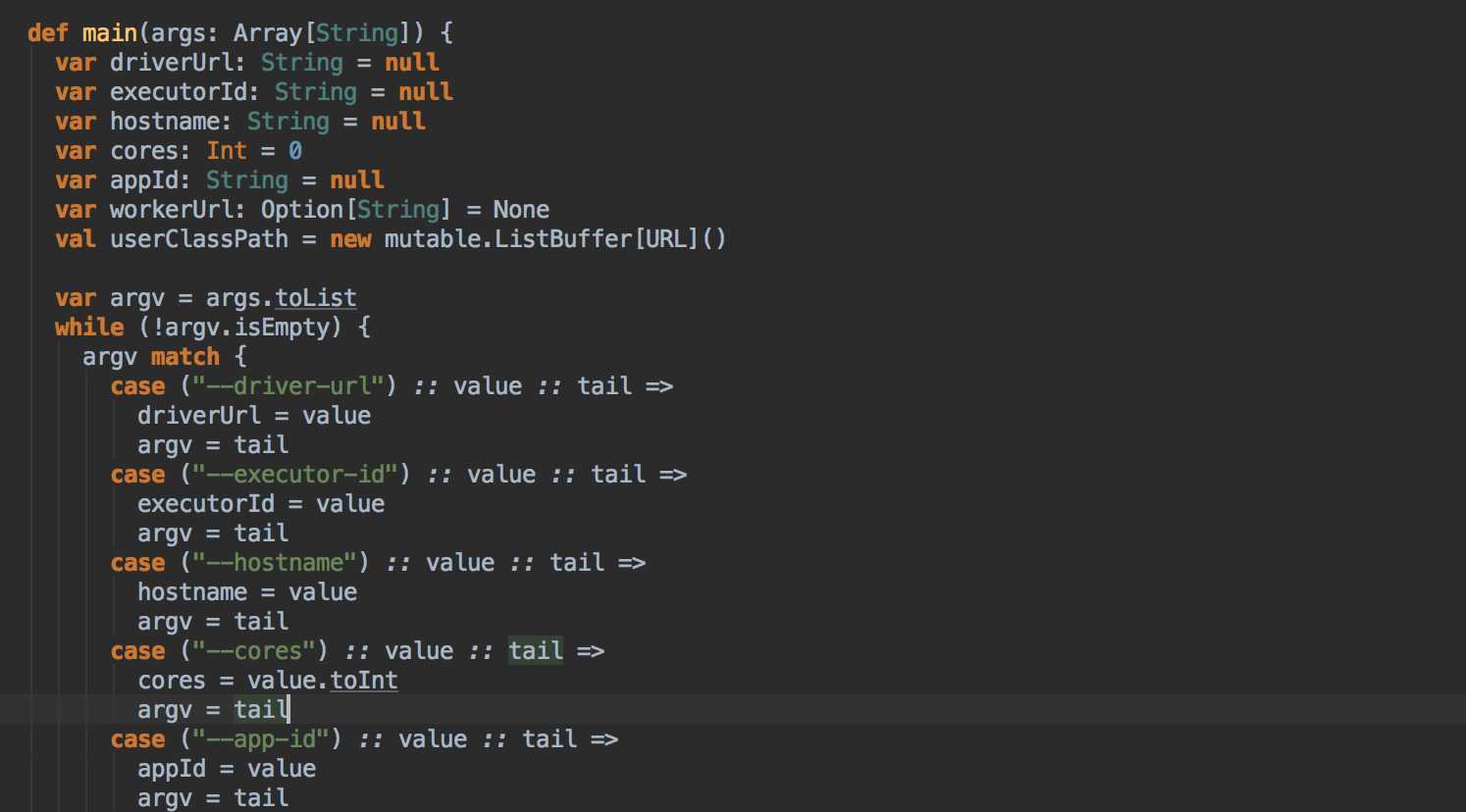
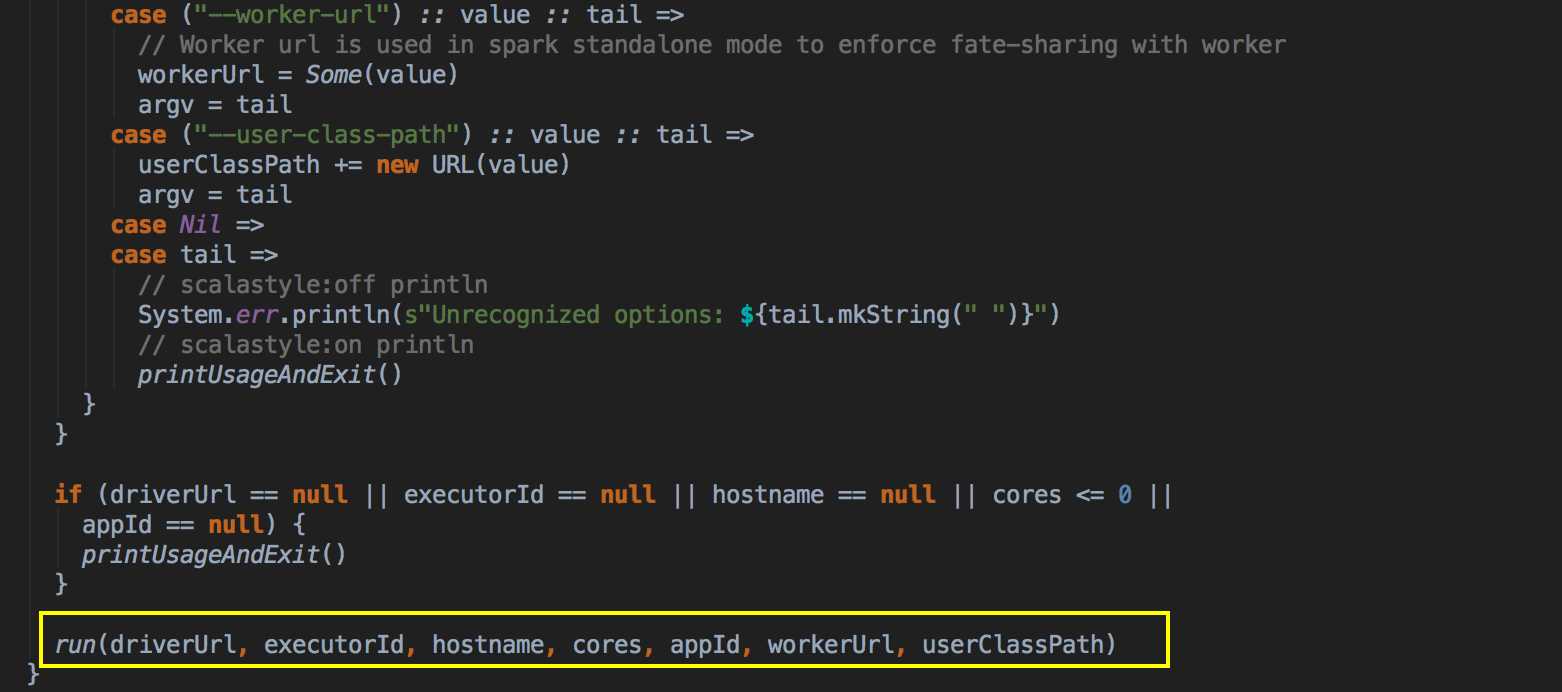
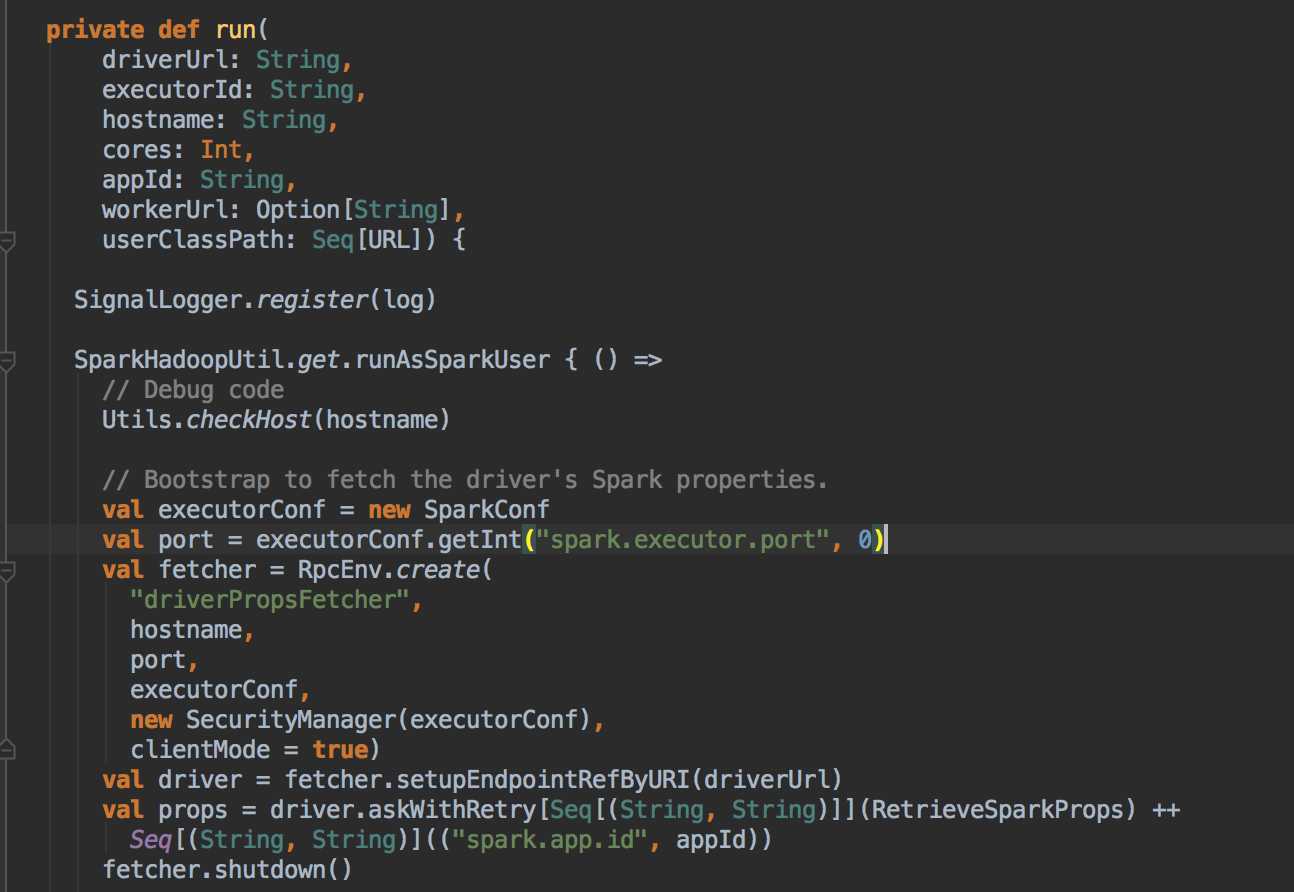
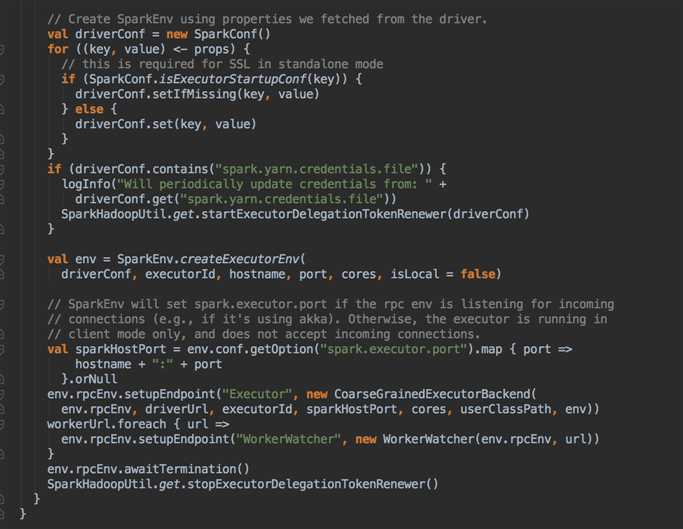
这次主要是看当提交Spark程序后,在 SparkContext 实例化的过程中,里面会创建多少个核心实例来为应用程序完成注冊,SparkContext 最主要的是实例化 TaskSchedulerImpl。
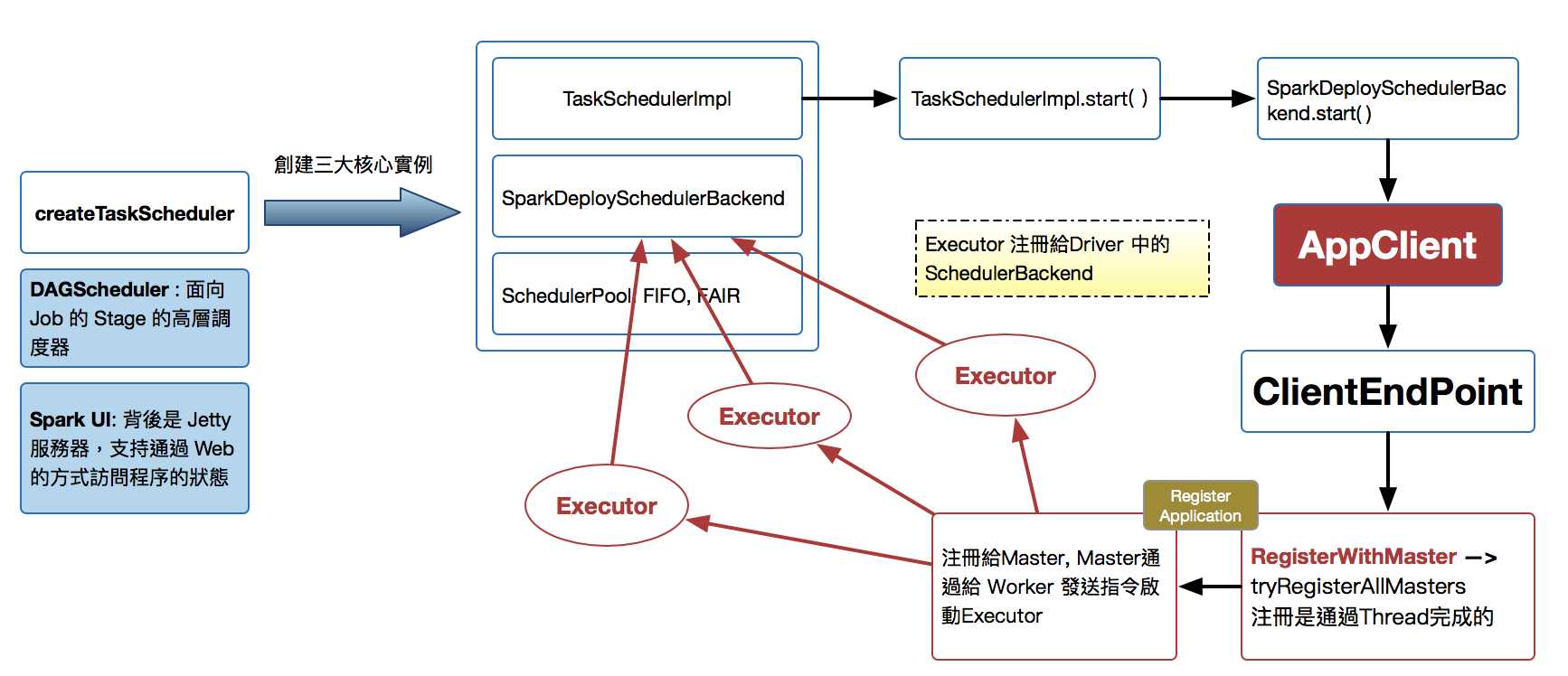
- SparkContext 構建的頂級三大核心:DAGScheduler, TaskScheduler, SchedulerBackend,其中:
- DAGScheduler 是面向 Job 的 Stage 的高層調度器;
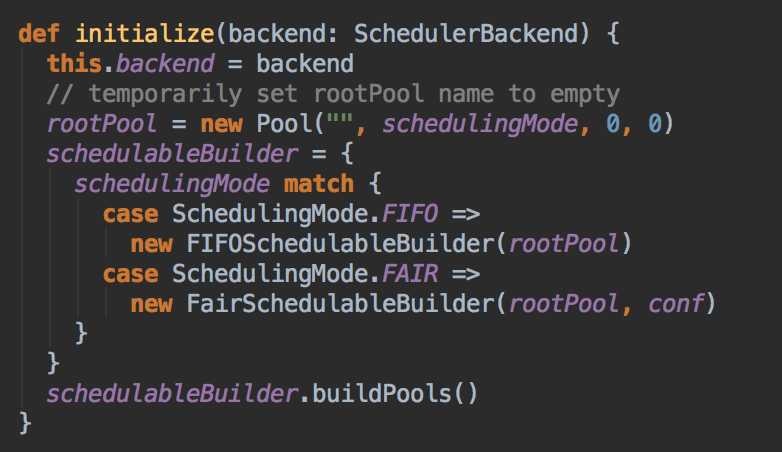
- TaskScheduler 是一個接口,是低層調度器,根據具體的 ClusterManager 的不同會有不同的實現,Standalone 模式下具體的實現 TaskSchedulerImpl;
- SchedulerBackend 是一個接口,根據具體的 ClusterManager 的不同會有不同的實現,Standalone 模式下具體的實現是SparkDeploySchedulerBackend
- 從整個程序運行的角度來講,SparkContext 包含四大核心對象:DAGScheduler, TaskScheduler, SchedulerBackend, MapOutputTrackerMaster
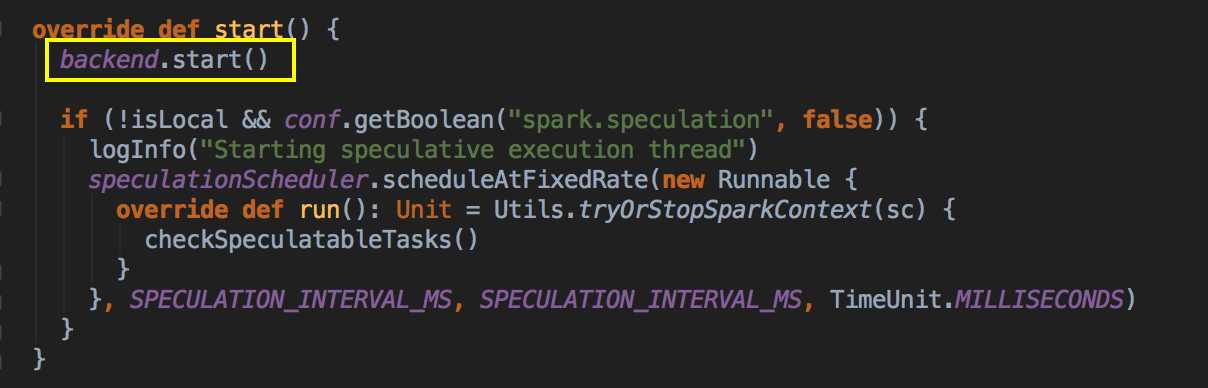
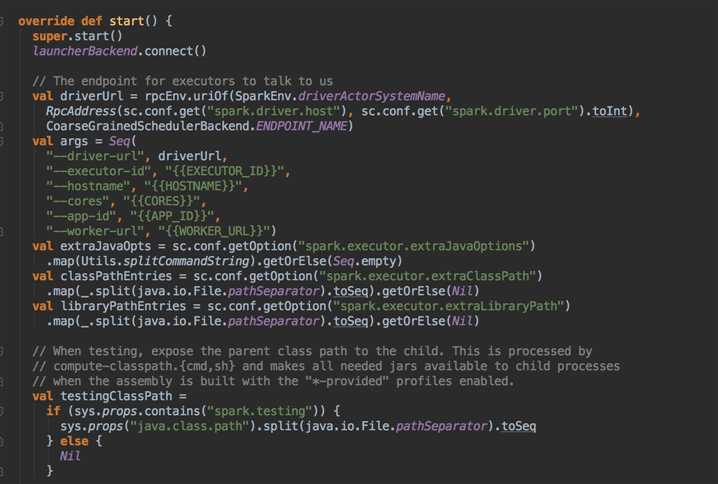
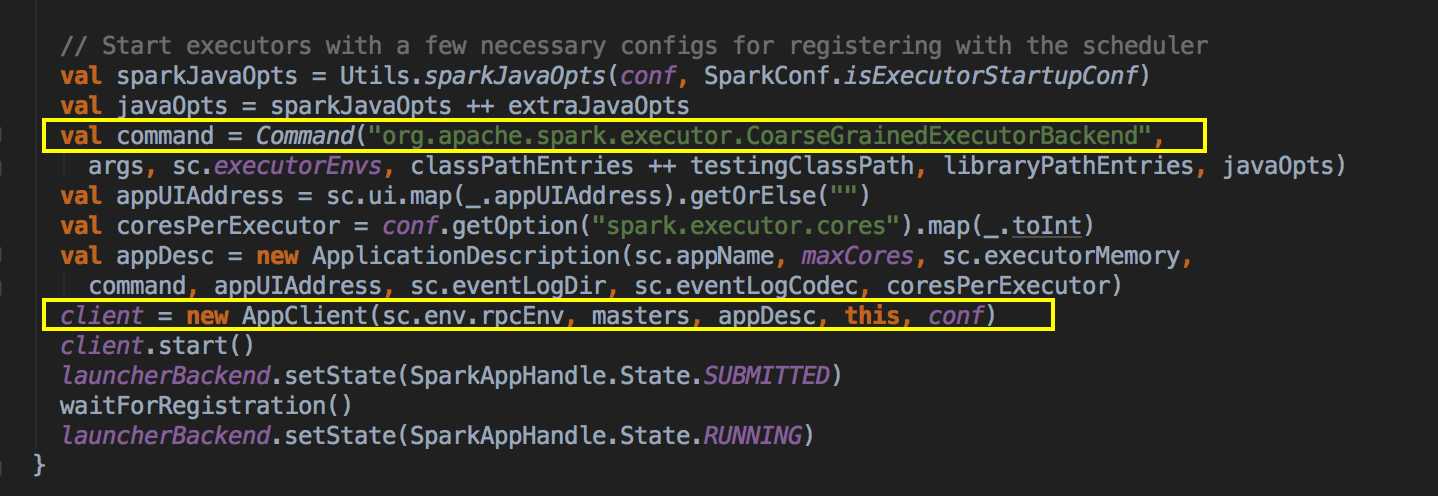
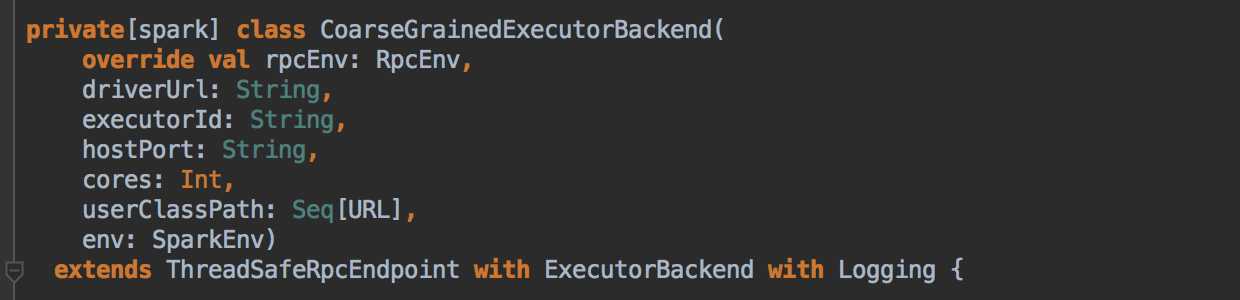
- SparkDeploySchedulerBackend 有三大核心功能:
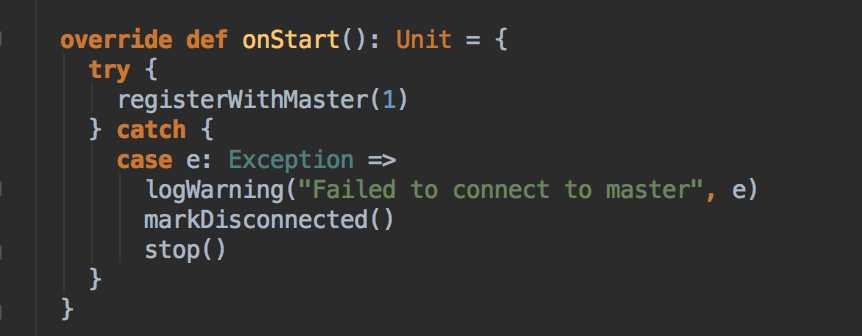
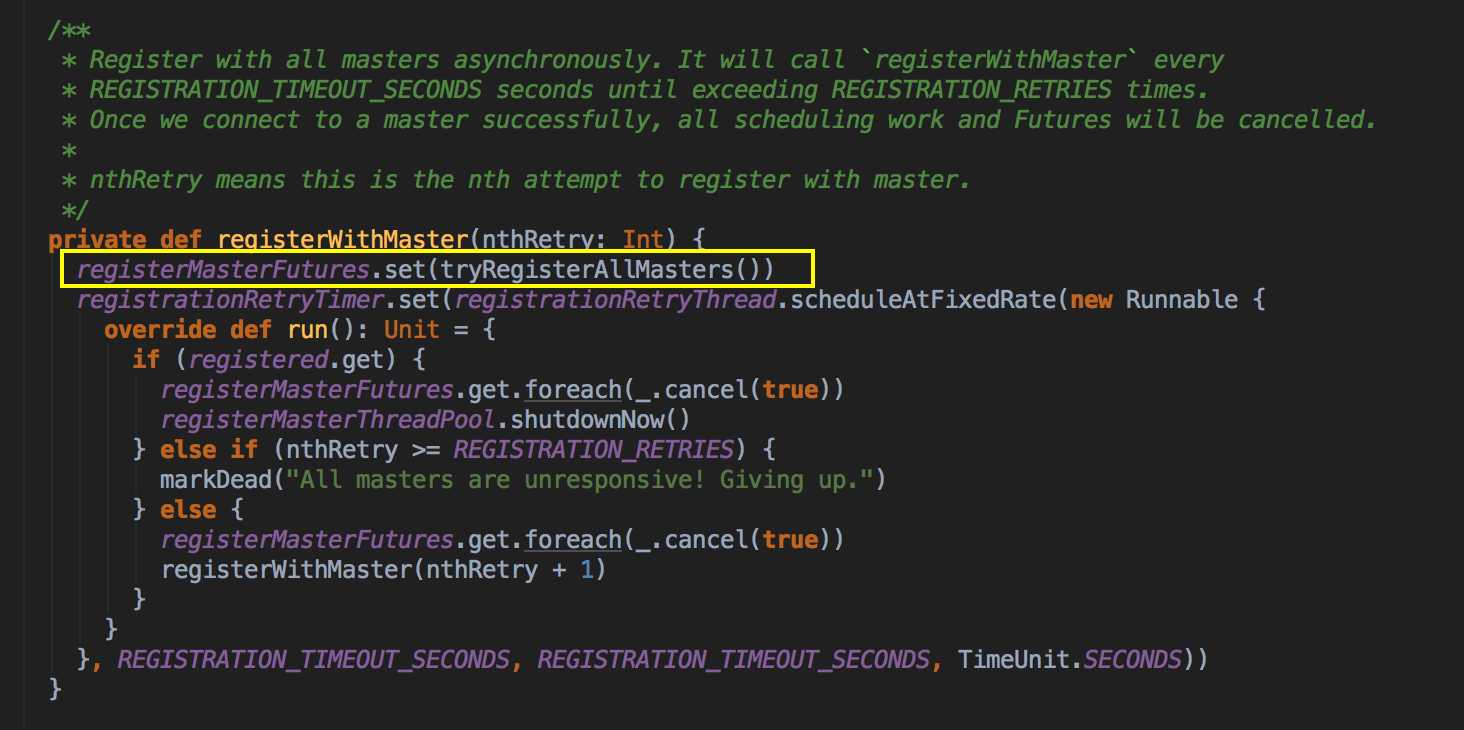
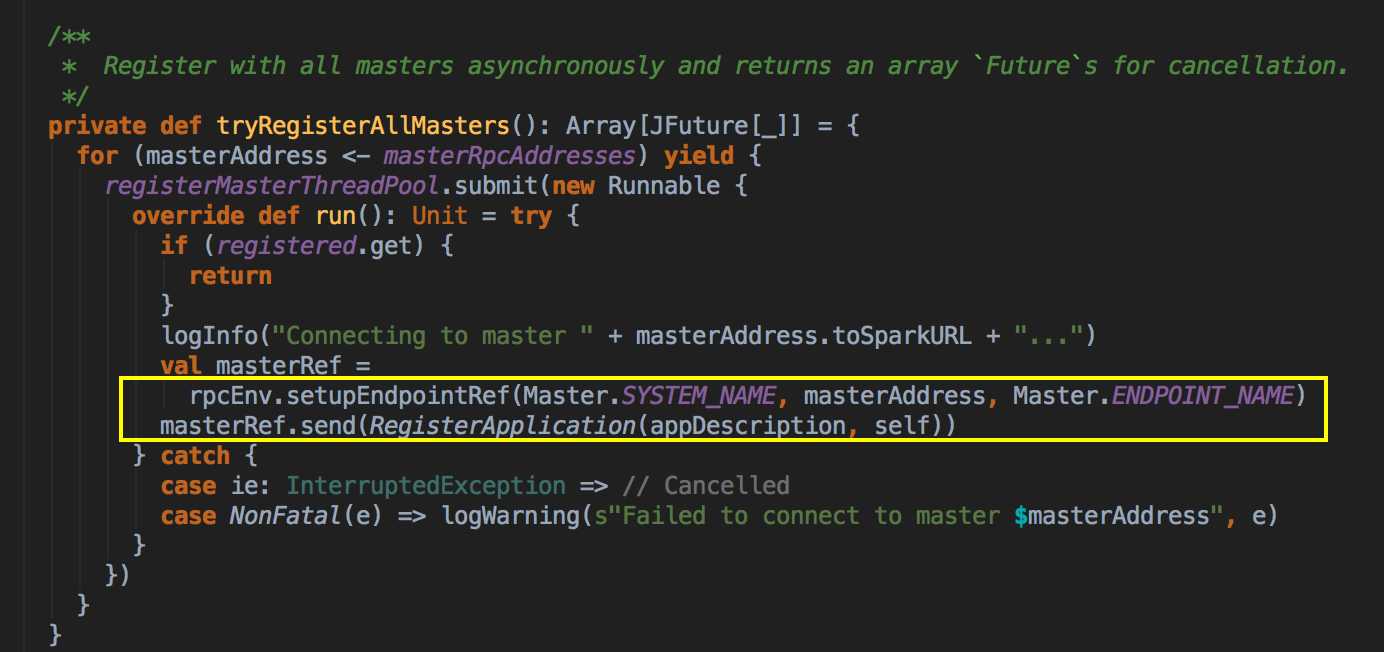
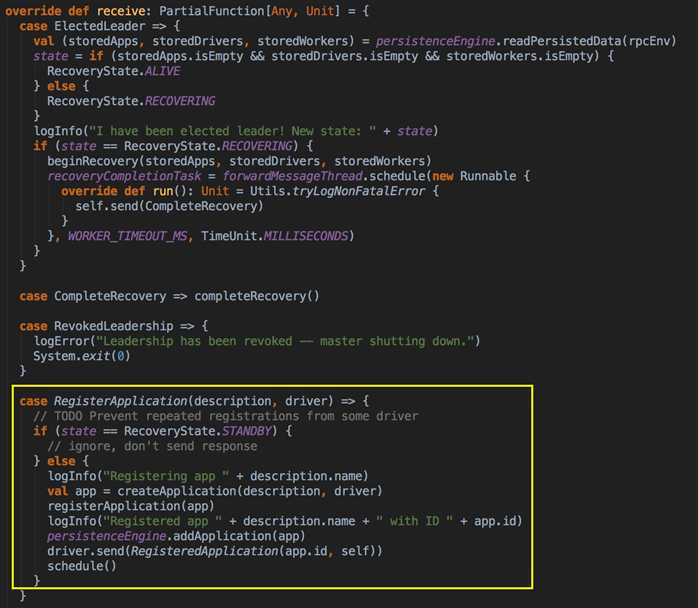
- 負責與 Master 連接注冊當前程序 RegisterWithMaster
- 接收集群中為當前應用程序而分配的計算資源 Executor 的注冊並管理 Executors;
- 負責發送 Task 到具體的 Executor 執行
補充說明的是 SparkDeploySchedulerBackend 是被 TaskSchedulerImpl 來管理的!
创建 SparkContext 的核心对象
總結
SparkContext 開啟了天堂之門:Spark 程序是通過 SparkContext 發佈到 Spark集群的
SparkContext 導演了天堂世界:Spark 程序運行都是在 SparkContext 為核心的調度器的指揮下進行的:
SparkContext 關閉了天堂之門:SparkContext 崩潰或者結束的是偶整個 Spark 程序也結束啦!
參考資料
资料来源来至 DT大数据梦工厂 第28课:Spark天堂之门解密视频
第28课:Spark天堂之门解密
原文:http://www.cnblogs.com/jcchoiling/p/6427406.html