今天心态正常。。。继续努力。。
--WH
一、上传原理和代码分析。
上传:我们把需要上传的资源,发送给服务器,在服务器上保存下来。
下载:下载某一个资源时,将服务器上的该资源发送给浏览器。
难点:服务器端获取资源时比较麻烦,
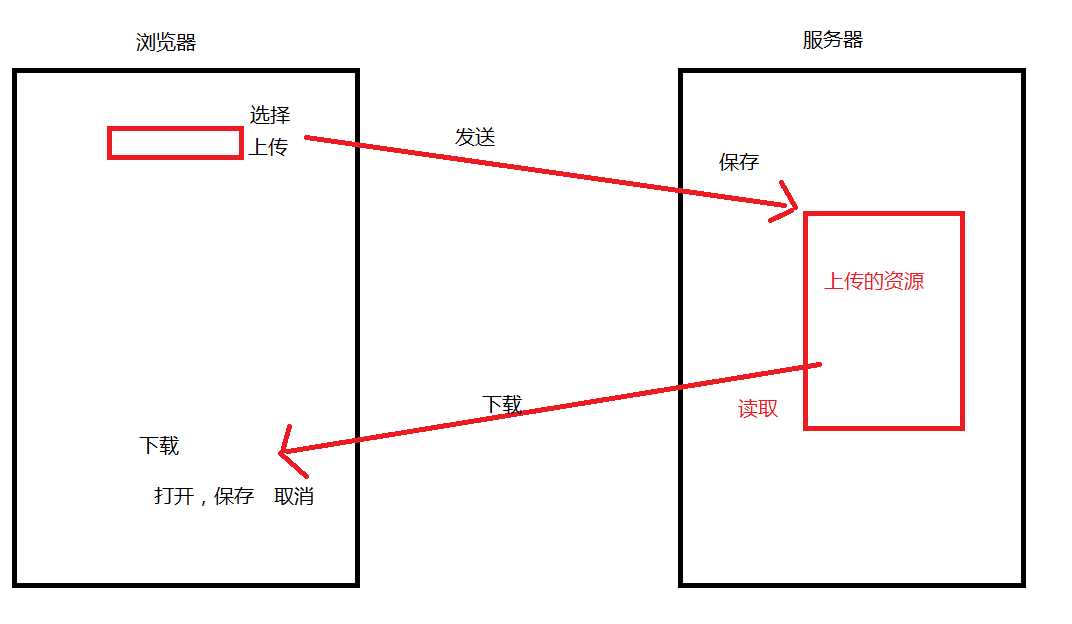
浏览器端

注意:enctype=multipart/form-data:该属性表明发送的请求体的内容是多表单元素的,通俗点讲,就是有各种各样的数据,可能有二进制数据,也可能有表单数据,等等,所以使用该属性也进行其区分,发送的格式如下(使用火狐中的Firebug插件进行捕捉的信息。)
![]()
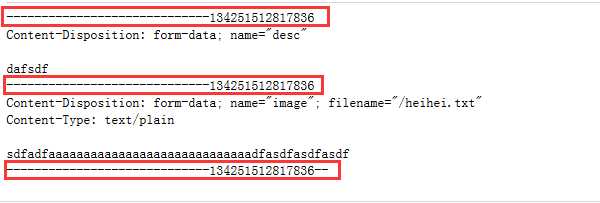
使用multipart/form-data会有一个boundary属性,来用将提交的表单数据进行分隔,以用来让服务器知道哪个是我们上传的资源,哪个是普通的表单数据。
服务器端,
如果不使用commons-fileupload插件来帮我们处理上传后的数据而让我们自己手动处理的话,也是可以的,但是十分麻烦,因为我们需要将所有的请求体获取到,然后通过字符串的分割,通过boundary这个属性进行分割,然后一步步获取到我们想要的数据。
使用commons-fileupload进行处理上传内容。


代码

1 try { 2 3 //1 工厂 4 FileItemFactory fileItemFactory = new DiskFileItemFactory(); 5 6 //2 核心类 7 ServletFileUpload servletFileUpload = new ServletFileUpload(fileItemFactory); 8 9 //3 解析request ,List存放 FileItem (表单元素的封装对象,一个<input>对应一个对象) 10 List<FileItem> list = servletFileUpload.parseRequest(request); 11 12 //4 遍历集合获得数据 13 for (FileItem fileItem : list) { 14 if(fileItem.isFormField()){ 15 // 5 是否为表单字段(普通表单元素) 16 //5.1.表单字段名称 17 String fieldName = fileItem.getFieldName(); 18 System.out.println(fieldName); 19 //5.2.表单字段值 20 String fieldValue = fileItem.getString(); //中文会出现乱码 21 System.out.println(fieldValue); 22 } else { 23 //6 上传字段(上传表单元素) 24 //6.1.表单字段名称 fileItem.getFieldName(); 25 //6.2.上传文件名 26 String fileName = fileItem.getName(); 27 // * 兼容浏览器, IE : C:\Users\xxx\Desktop\abc.txt ; 其他浏览器 : abc.txt 28 fileName = fileName.substring(fileName.lastIndexOf("\\") + 1); 29 System.out.println(fileName); //上传的文件名会中文乱码, 30 //6.3.上传内容 31 InputStream is = fileItem.getInputStream(); //获得输入流, 32 String parentDir = this.getServletContext().getRealPath("/WEB-INF/upload"); 33 File file = new File(parentDir,fileName); 34 if(! file.getParentFile().exists()){ //父目录不存在 35 file.getParentFile().mkdirs(); //mkdirs():创建文件夹,如果上级目录没有的话,也一并创建出来。 36 } 37 FileOutputStream out = new FileOutputStream(file); 38 byte[] buf = new byte[1024]; 39 int len = -1; 40 while( (len = is.read(buf)) != -1){ 41 out.write(buf, 0, len); 42 } 43 44 //关闭 45 out.close(); 46 is.close(); 47 } 48 } 49 50 } catch (Exception e) { 51 e.printStackTrace(); 52 53 throw new RuntimeException(e); 54 55 } 56 }
其中需要注意的是流的操作,和File类的操作,mkdirs()和mkdir()的区别是什么?它们都是用来创建文件夹的,区别在mkdirs能创建多级目录,而mkdir()只能创建当前的文件夹,如果发现上一层目录并还没有创建时,它也会无动于衷,什么也不干,也就不能创建当前文件夹,必须先要创建了上一级文件夹才可以。
上面还有很多的问题需要解决,比如上传文件名的乱码问题,比如单表内容的乱码问题,比如上传文件同名问题,如果上传的文件很大,该如何进行处理,比如,放在同一级目录下的文件过多如何处理。每次都自己手动写输出流,将内容存到指定位置,太过麻烦,等等问题,现在写一个加强版,在解决上面所有的问题。
上传文件名乱码问题:使用servletFileUpload.setHeaderEncoding("UTF-8");或者request.setCharacterEncoding("UTF-8")都可以
表单内容乱码问题:使用getString("utf-8")即可,也就是在获取内容时,就可以设置码表。
上传文件同名问题:使用UUID.randomUUID().toString().replace("-", "").获得一个独一无二的32位数字
使用FileUtils.copyInputStreamToFile(is, file);来将内容输出到指定路径文件中去,mkdirs() 自动创建目录
同一级目录下的文件过多问题:创建多级目录,通过文件名的hashcode的值,hashCode为int型,占4个字节,一个字节占8位,也就是占32位,将其分组,4位4位一组,就能分8组,每一次代表一层目录,也就能够分8层目录,每一层中,有可以创建16种不同的文件夹。这样算下来,就能有很多很多个文件夹了,每个文件夹下面都可以存很多文件,看我们的业务需求,来决定要创建几层目录,就从hashcode中拿几组数据出来。原理图如下
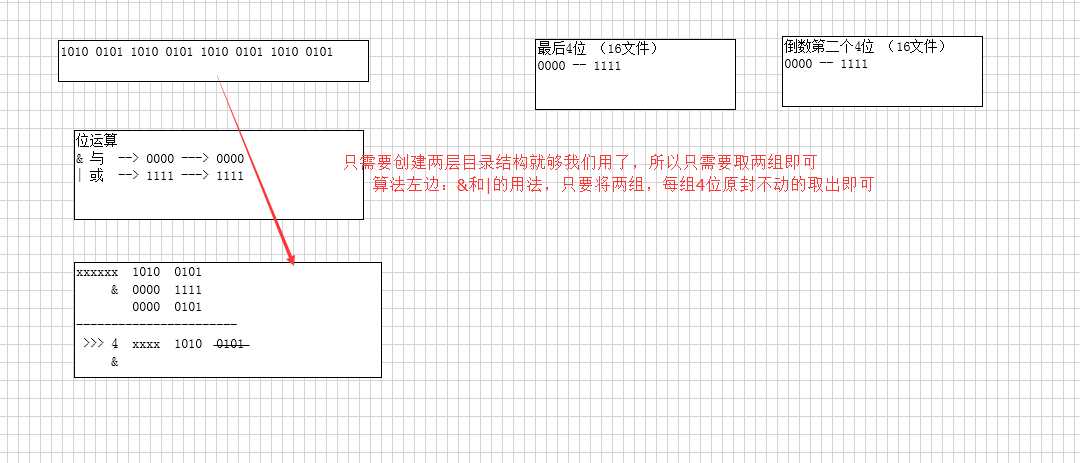
生成两级目录
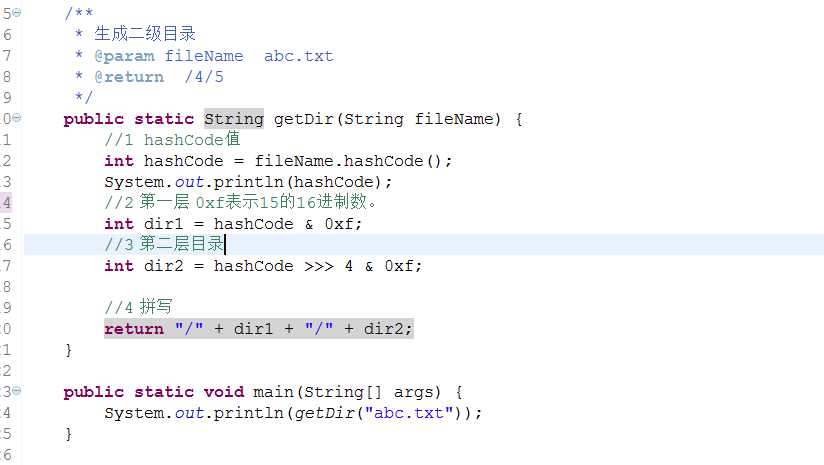
代码
1 public class StringUtils { 2 3 /** 4 * 生成二级目录 5 * @param fileName abc.txt 6 * @return /4/5 7 */ 8 public static String getDir(String fileName) { 9 //1 hashCode值 10 int hashCode = fileName.hashCode(); 11 System.out.println(hashCode); 12 //2 第一层 0xf表示15的16进制数。 13 int dir1 = hashCode & 0xf; 14 //3 第二层目录 15 int dir2 = hashCode >>> 4 & 0xf; 16 17 //4 拼写 18 return "/" + dir1 + "/" + dir2; 19 } 20 21 public static void main(String[] args) { 22 System.out.println(getDir("abc.txt")); 23 } 24 25 }
上传代码
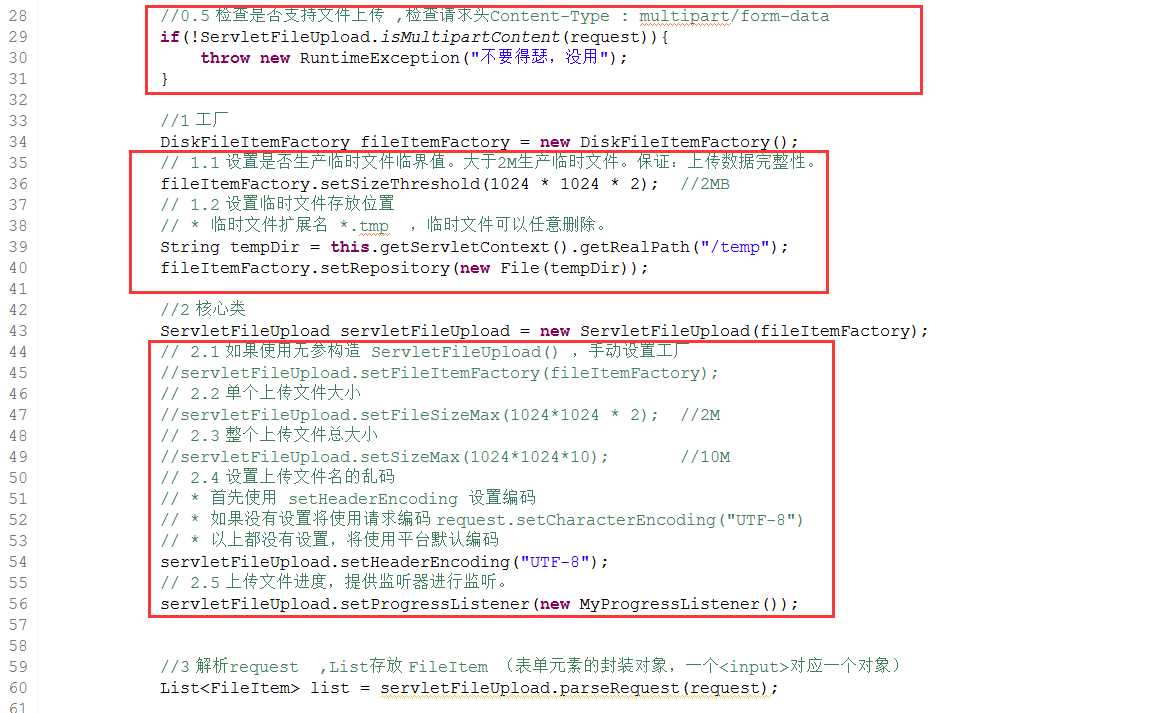
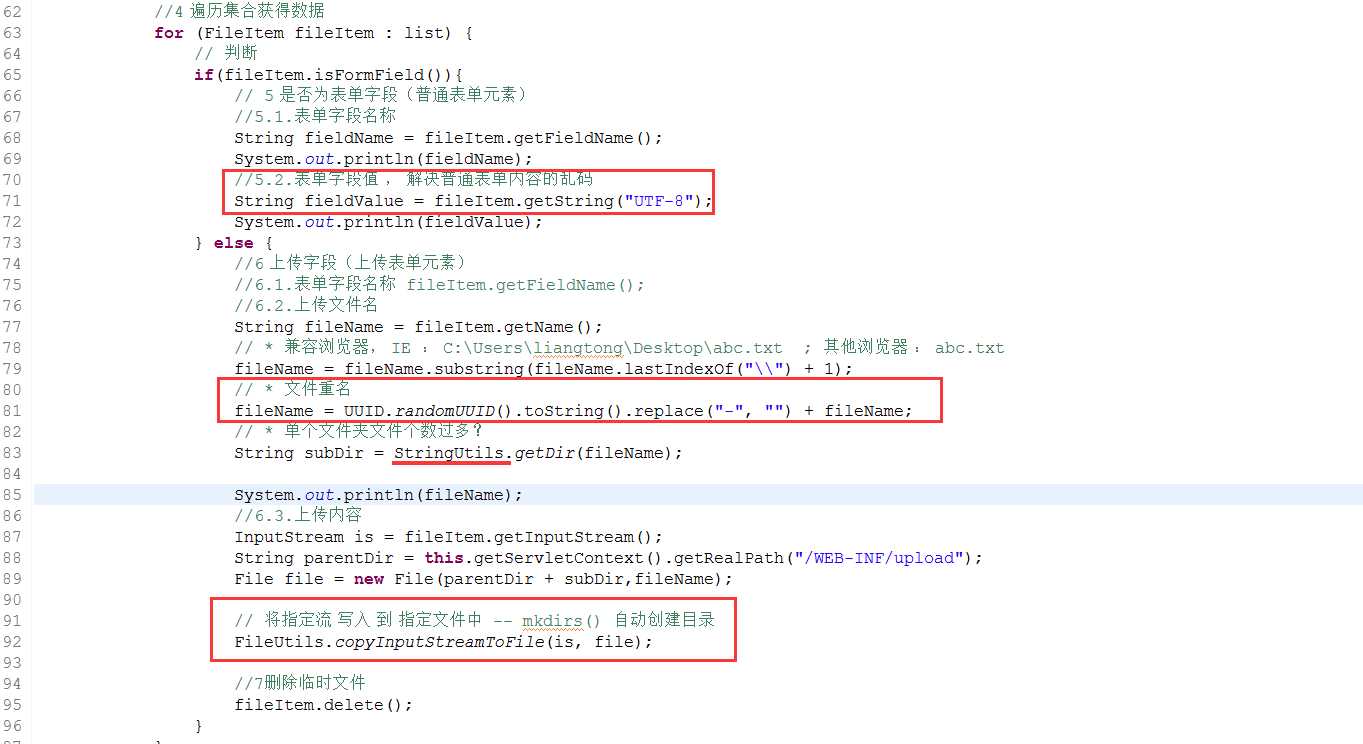
1 public void doGet(HttpServletRequest request, HttpServletResponse response) 2 throws ServletException, IOException { 3 try { 4 5 //0.5 检查是否支持文件上传 ,检查请求头Content-Type : multipart/form-data 6 if(!ServletFileUpload.isMultipartContent(request)){ 7 throw new RuntimeException("不要得瑟,没用"); 8 } 9 10 //1 工厂 11 DiskFileItemFactory fileItemFactory = new DiskFileItemFactory(); 12 // 1.1 设置是否生产临时文件临界值。大于2M生产临时文件。保证:上传数据完整性。 13 fileItemFactory.setSizeThreshold(1024 * 1024 * 2); //2MB 14 // 1.2 设置临时文件存放位置 15 // * 临时文件扩展名 *.tmp ,临时文件可以任意删除。 16 String tempDir = this.getServletContext().getRealPath("/temp"); 17 fileItemFactory.setRepository(new File(tempDir)); 18 19 //2 核心类 20 ServletFileUpload servletFileUpload = new ServletFileUpload(fileItemFactory); 21 // 2.1 如果使用无参构造 ServletFileUpload() ,手动设置工厂 22 //servletFileUpload.setFileItemFactory(fileItemFactory); 23 // 2.2 单个上传文件大小 24 //servletFileUpload.setFileSizeMax(1024*1024 * 2); //2M 25 // 2.3 整个上传文件总大小 26 //servletFileUpload.setSizeMax(1024*1024*10); //10M 27 // 2.4 设置上传文件名的乱码 28 // * 首先使用 setHeaderEncoding 设置编码 29 // * 如果没有设置将使用请求编码 request.setCharacterEncoding("UTF-8") 30 // * 以上都没有设置,将使用平台默认编码 31 servletFileUpload.setHeaderEncoding("UTF-8"); 32 // 2.5 上传文件进度,提供监听器进行监听。 33 servletFileUpload.setProgressListener(new MyProgressListener()); 34 35 36 //3 解析request ,List存放 FileItem (表单元素的封装对象,一个<input>对应一个对象) 37 List<FileItem> list = servletFileUpload.parseRequest(request); 38 39 //4 遍历集合获得数据 40 for (FileItem fileItem : list) { 41 // 判断 42 if(fileItem.isFormField()){ 43 // 5 是否为表单字段(普通表单元素) 44 //5.1.表单字段名称 45 String fieldName = fileItem.getFieldName(); 46 System.out.println(fieldName); 47 //5.2.表单字段值 , 解决普通表单内容的乱码 48 String fieldValue = fileItem.getString("UTF-8"); 49 System.out.println(fieldValue); 50 } else { 51 //6 上传字段(上传表单元素) 52 //6.1.表单字段名称 fileItem.getFieldName(); 53 //6.2.上传文件名 54 String fileName = fileItem.getName(); 55 // * 兼容浏览器, IE : C:\Users\liangtong\Desktop\abc.txt ; 其他浏览器 : abc.txt 56 fileName = fileName.substring(fileName.lastIndexOf("\\") + 1); 57 // * 文件重名 58 fileName = UUID.randomUUID().toString().replace("-", "") + fileName; 59 // * 单个文件夹文件个数过多? 60 String subDir = StringUtils.getDir(fileName); 61 62 System.out.println(fileName); 63 //6.3.上传内容 64 InputStream is = fileItem.getInputStream(); 65 String parentDir = this.getServletContext().getRealPath("/WEB-INF/upload"); 66 File file = new File(parentDir + subDir,fileName); 67 68 // 将指定流 写入 到 指定文件中 -- mkdirs() 自动创建目录 69 FileUtils.copyInputStreamToFile(is, file); 70 71 //7删除临时文件 72 fileItem.delete(); 73 } 74 } 75 76 } catch (Exception e) { 77 e.printStackTrace(); 78 79 throw new RuntimeException(e); 80 81 } 82 }
其中如果需要做上传的进度条时,就可以使用监听器来进行监听上传数据的进度,实现ProgressListener即可。
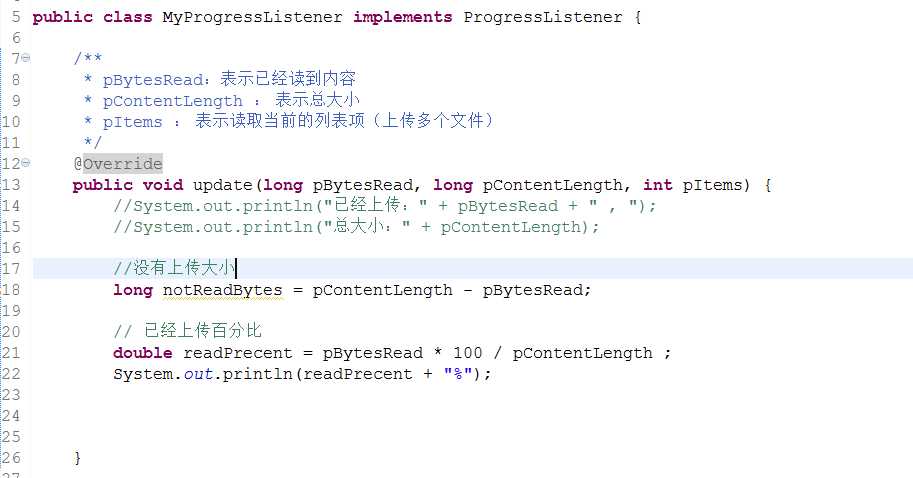
总结上传:
其实理解了也不是很难,就是上传文件后的处理比较麻烦,各种小问题,存储过程最为麻烦。
1、创建工厂类
2、使用核心类,
3、解析request请求,
4、遍历请求体的内容,将上传内容和普通表单内容都获取出来
5、获取到上传内容时,对其存储位置进行设置
其中很多细节问题都在上面已经说清楚了,代码中也有很多注释。
二、下载原理和代码实现
实现下载有两种方式,
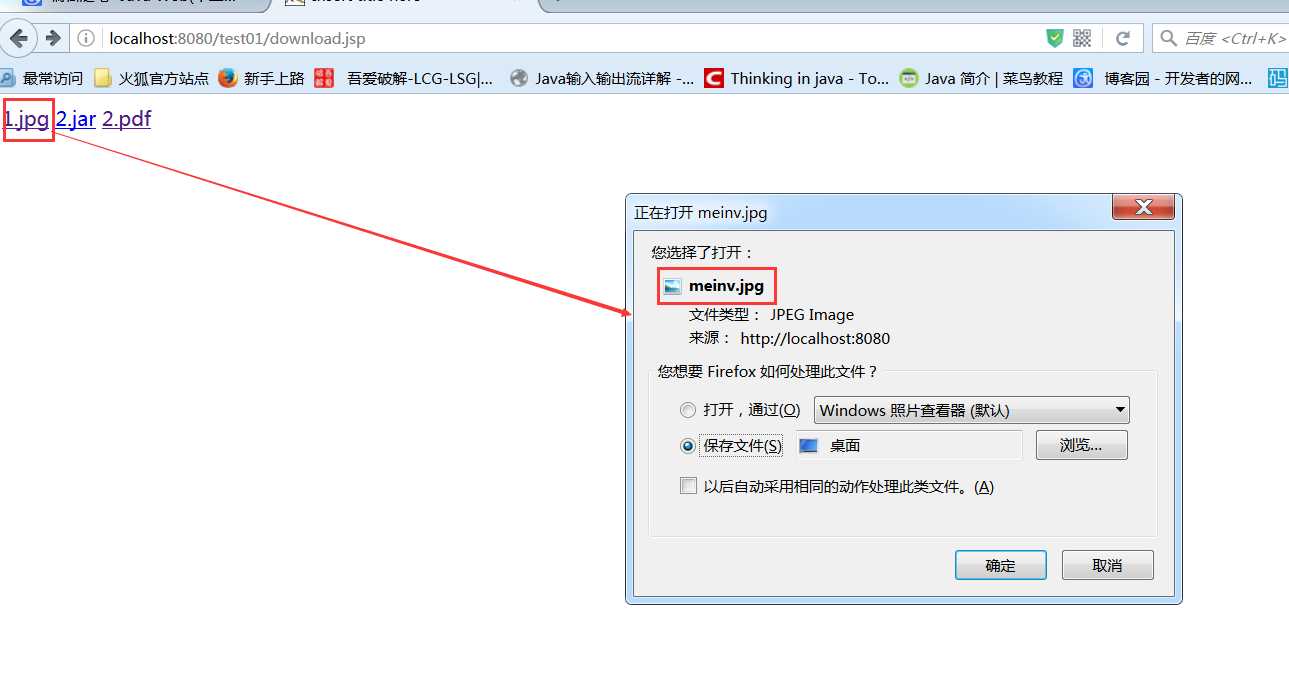
第一种,使用a标签,也就是使用超链接,如果浏览器能够解析,则直接显示出来,如果不能解析,则进行下载,这种方式不太好,

我使用的是火狐,第一个和第三个都能直接解析出来,而第二个则不能解析,显示的是下载页面
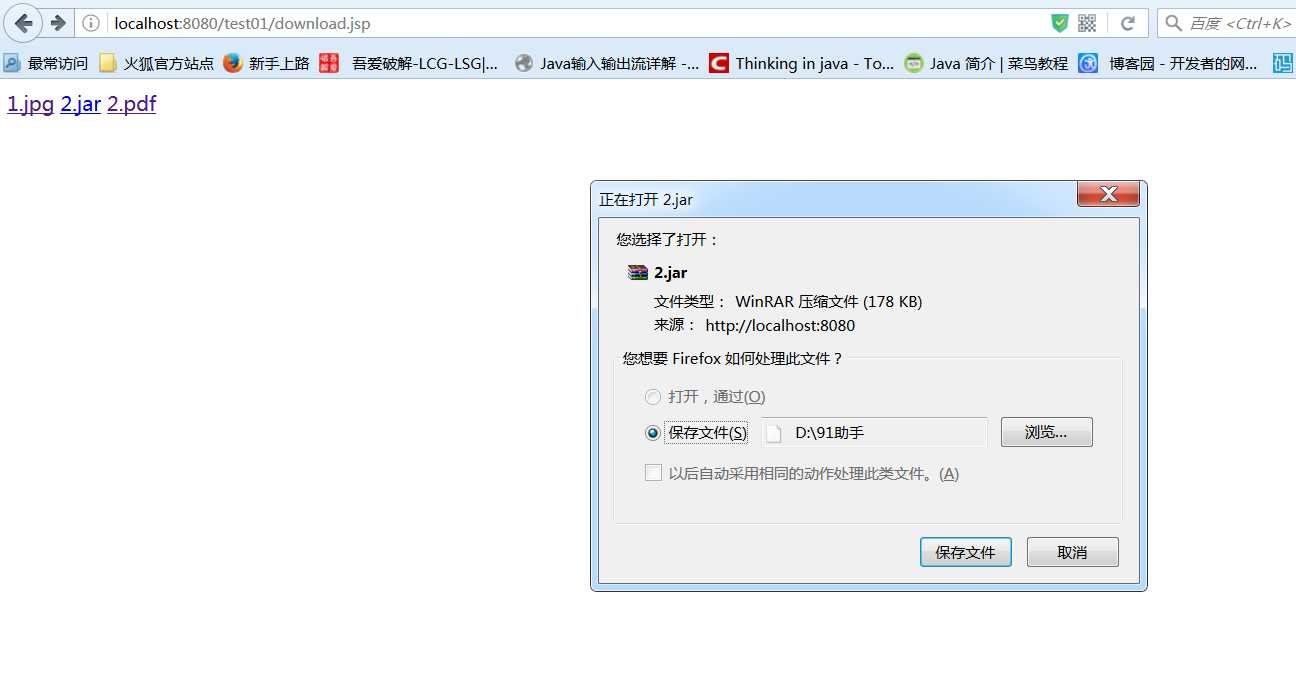
第二种方式:
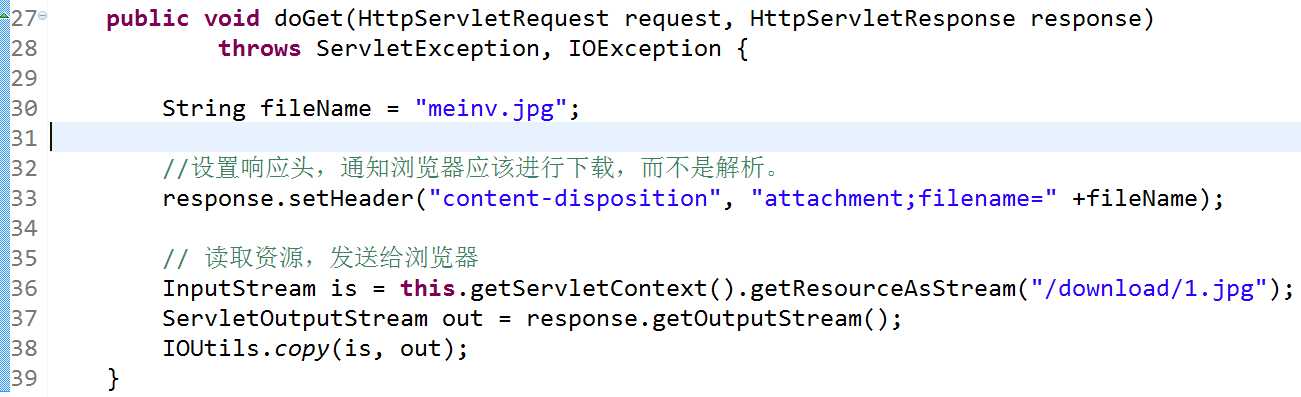
1、设置响应头,让浏览器知道应该下载,而不是解析
response.setHeader("content-disposition", "attachment;filename=" +fileName); //设置content-disposition响应头
2、获取输入流,指向需要下载的文件
InputStream is = this.getServletContext().getResourceAsStream("/download/1.jpg");
3、获取输出流,将其文件传到浏览器端
ServletOutputStream out = response.getOutputStream();
4、使用IOUtils.copy(is,out);直接将输入流和输出流传进去,就会帮我们把输出流读到的内容通过输出流输出到浏览器。内部实现原理应该就如下所示
int b = -1;
byte[] bf = new byte[1024];
while((b=is.read(bf)) != -1){
out.write(bf,0,b);
}

注意:这里下载时写的下载文件名不包含中文,所以能够正常显示,如果写中文的话,则会乱码,甚至是中文都不会显示出来。有两种方式处理这个中文乱码问题
1、简单处理
fileName = new String(fileName.getBytes("gbk"),"ISO8859-1");
fileName = new String(fileName.getBytes("utf-8"),"ISO8859-1");
fileName = new String(fileName.getBytes(),"ISO8859-1"); //这种跟第一种是一样的,默认使用的编码就是gbk。
原理
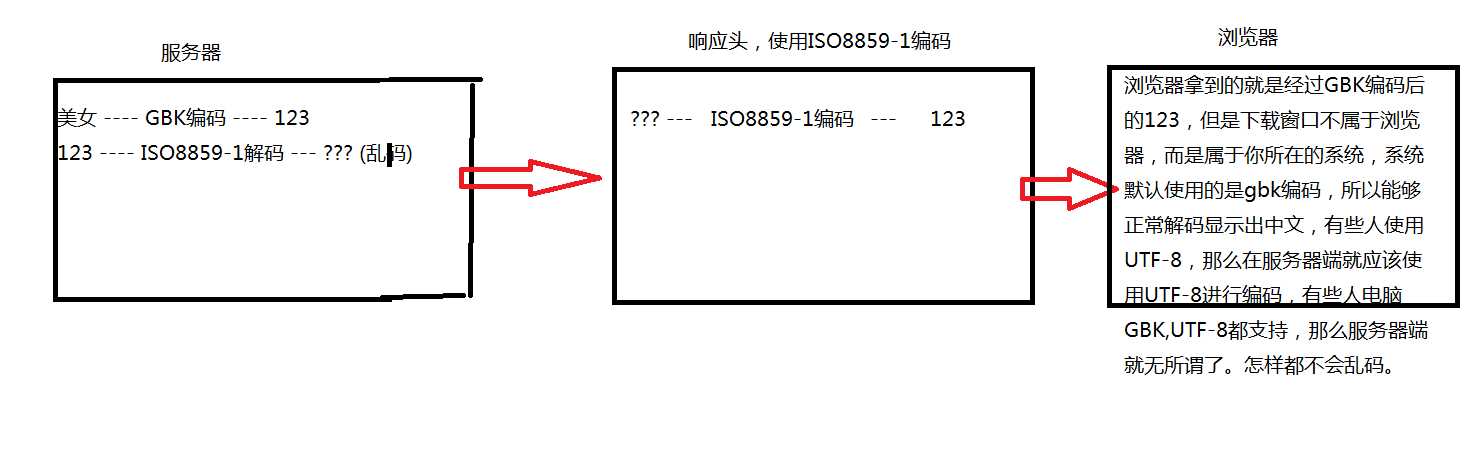
上面代码意思是,先将fileName使用gbk或者utf-8进行编码,然后在使用ISO8859-1进行解码,此时的fileName是一个乱码文字。具体原理图可以看下面两张图
这张图解释了上面这段代码所做的事情,而整个编码过程,我来简单口述一下,在服务器端,写上面这段代码,美女是中文字,将其使用GBK码表进行编码后,就会获得一个计算机认识的符号,比如是123,然后我们在将这个计算机认识的符号,123使用ISO8859-1码表进行解码,变成我们所认识的汉字,但是因为编码和解码所用码表不一样,所以不能正常显示,也就是此时的fileName本身就是一个乱码的文字,然后在响应头中,因为是使用ISO8859-1的码表进行编码,所以fileName本身乱码的文字,就会变为机器认识的123,当到了浏览器端,因为123是由gbk进行编码的,所以如果使用gbk进行的解码的话,就会使其正确的显示,过程就是这样
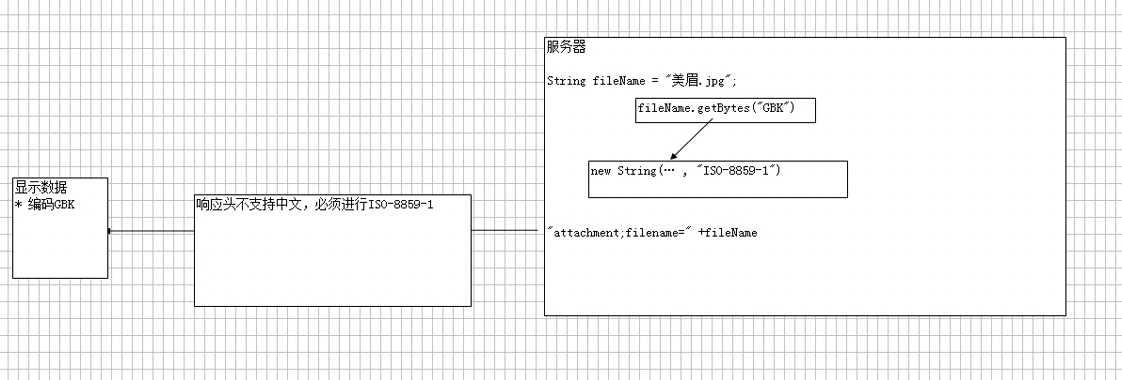
如果还不知道什么是编码,什么是解码,那么就去看一下request和response乱码问题的解决那篇博文,应该能解决你的疑问。
代码:
1 2 String fileName = "美女.jpg"; 3 fileName = new String(fileName.getBytes("gbk"),"ISO8859-1"); 4 //设置响应头,通知浏览器应该进行下载,而不是解析。 5 response.setHeader("content-disposition", "attachment;filename=" +fileName); 6 7 // 读取资源,发送给浏览器 8 InputStream is = this.getServletContext().getResourceAsStream("/download/1.jpg"); 9 ServletOutputStream out = response.getOutputStream(); 10 IOUtils.copy(is, out);
2、复杂处理
根据每个浏览器的不同,而进行不同的操作。根据浏览器不同进行设置。IE和谷歌 URL编码,火狐采用BASE64编码
IE和谷歌
// * IE 谷歌 采用 URL编码,就用URL对fileName进行编码即可。其内部跟我们上面讲解编码解码时的思路类似,可以将fileName输出看看是个什么结果,还是一个xxx.jpg,说明就是将fileName进行编码,解码的过程。
if(userAgent.contains("MSIE") || userAgent.contains("Chrome")){ //判断是不是google或者IE浏览器
fileName = URLEncoder.encode(fileName, "UTF-8");
}
火狐 采用 Base64编码

这里会出现两个问题,
一个是BASE64Encoder这个类找不到包,这个问题的解决参考
http://blog.csdn.net/jbxiaozi/article/details/7351768
http://www.cnblogs.com/silentjesse/archive/2013/03/07/2948146.html
另一个是格式问题。这个非常麻烦,我是记不住,具体查看图中的注释,格式已经写出来了。
下载原理总代码,包含上面所讲解到的。
1 //下载 中文文件名 乱码 2 String fileName = "美眉.jpg"; 3 //方案1:简单方案 4 //fileName = new String(fileName.getBytes("GBK"),"ISO8859-1"); 5 //方案2:不同的浏览器对文件名解析采用不同方案。 6 String userAgent = request.getHeader("User-Agent"); 7 // * IE 谷歌 采用 URL编码 8 if(userAgent.contains("MSIE") || userAgent.contains("Chrome")){ 9 fileName = URLEncoder.encode(fileName, "UTF-8"); 10 } 11 // * 火狐 采用 Base64编码 12 if(userAgent.contains("Firefox")){ 13 BASE64Encoder base64Encoder = new BASE64Encoder(); 14 String encStr = base64Encoder.encode(fileName.getBytes("UTF-8")); 15 // 格式 : =?字符集?编码方式?....?= 16 // * 编码方式:B base64 ,Q q编码 17 fileName = "=?UTF-8?B?"+encStr+"?="; 18 } 19 20 //设置响应头,通知浏览器应该进行下载,而不是解析。 21 response.setHeader("content-disposition", "attachment;filename=" +fileName); 22 23 // 读取资源,发送给浏览器 24 InputStream is = this.getServletContext().getResourceAsStream("/download/1.jpg"); 25 ServletOutputStream out = response.getOutputStream(); 26 IOUtils.copy(is, out);
总结:下载其实非常简单,就是在编写下载文件名出现的中文乱码问题比较麻烦,其他的套路很容易,
1、设置响应头,让浏览器知道该文件是需要下载的
2、就是找准要下载的文件的路径从而拿到输入流,在通过response拿到输出流,
3、通过OUtils.copy(is, out);就解决了,不用在乎其中内部的实现。
三、总结
到这里,上传和下载的原理和代码都已经讲解完了,你学会了吗?其中只能总结一点,基础知识很重要,我在编写这博文时,发现连最基础的对File类的操作都模糊不清,对流的操作也不是很感冒,但是通过翻阅资料,也差不多知道了自己曾不知道的东西。
Java Web(十二) commons-fileupload上传下载
原文:http://www.cnblogs.com/whgk/p/6479405.html
