2017年2月28日, 星期二
| Local | 多用于测试 |
| Standalone | Spark自带的资源调度器(默认情况下就跑在这里面) |
| MeSOS | 资源调度器,同Hadoop中的YARN |
| YARN | 最具前景,公司里大部分都是 Spark on YRAN |
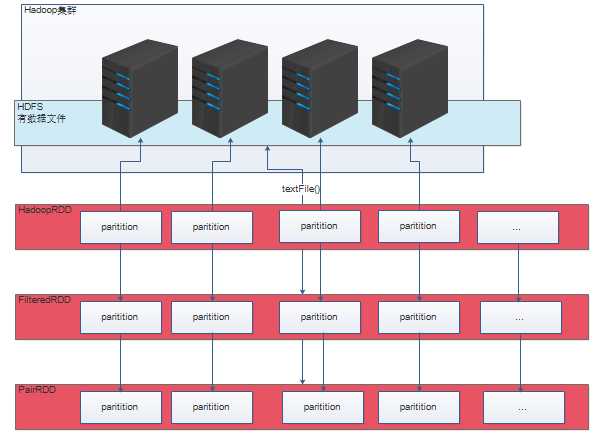
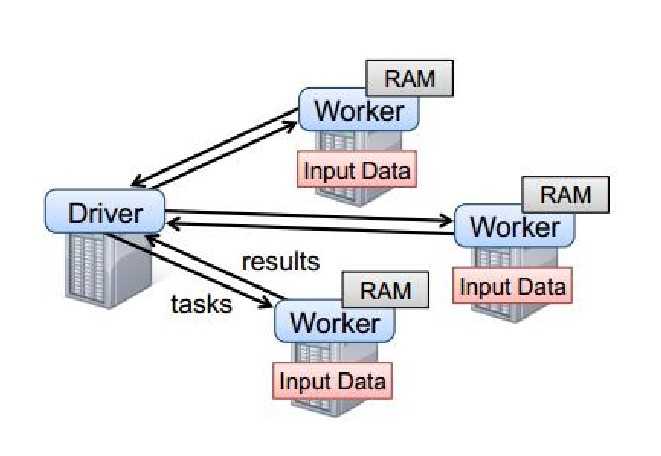
|
Transformations || Actions 这两类算子的区别
|
||
|
Transformations
|
Transformations类的算子会返回一个新的RDD,懒执行 | |
|
Actions
|
Actions类的算子会返回基本类型或者一个集合,能够触发一个job的 执行,代码里面有多少个action类算子,那么就有多少个job | |
| Transformation类算子 | map | 输入一条,输出一条 将原来 RDD 的每个数据项通过 map 中的用户自定义函数映射转变为一个新的 元素。输入一条输出一条; |
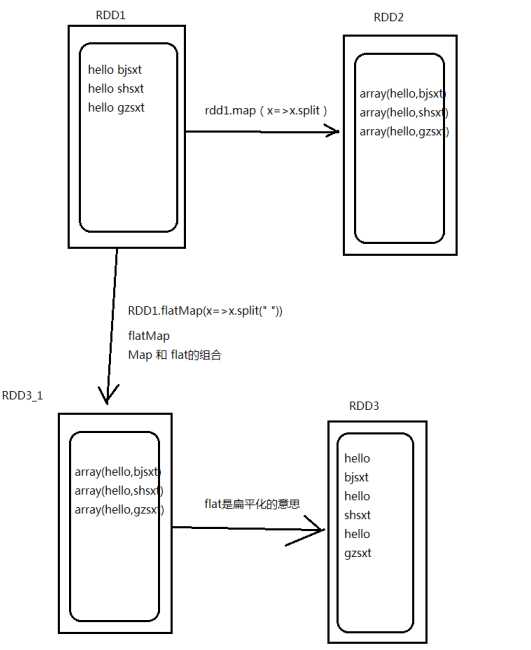
| flatMap | 输入一条输出多条 先进行map后进行flat |
|
| mapPartitions | 与 map 函数类似,只不过映射函数的参数由 RDD 中的每一个元素变成了 RDD 中每一个分区的迭代器。将 RDD 中的所有数据通过 JDBC 连接写入数据库,如果使 用 map 函数,可能要为每一个元素都创建一个 connection,这样开销很大,如果使用 mapPartitions,那么只需要针对每一个分区建立一个 connection。 | |
| mapPartitionsWithIndex | ||
| filter | 依据条件过滤的算子 | |
| join | 聚合类的函数,会产生shuffle,必须作用在KV格式的数据上 join 是将两个 RDD 按照 Key 相同做一次聚合;而 leftouterjoin 是依 据左边的 RDD 的 Key 进行聚 |
|
| union | 不会进行数据的传输,只不过将这两个的RDD标识一下 (代表属于一个RDD) |
|
| reduceByKey | 先分组groupByKey,后聚合根据传入的匿名函数聚合,适合在 map 端进行 combiner | |
| sortByKey | 依据 Key 进行排序,默认升序,参数设为 false 为降序 | |
| mapToPair | 进行一次 map 操作,然后返回一个键值对的 RDD。(所有的带 Pair 的算子返回值均为键值对) | |
| sortBy | 根据后面设置的参数排序 | |
| distinct | 对这个 RDD 的元素或对象进行去重操作 | |
| Actions类算子 | foreach | foreach 对 RDD 中的每个元素都应用函数操作,传入一条处理一条数据,返回值为空 |
| collect | 返回一个集合(RDD[T] => Seq[T]) collect 相当于 toArray, collect 将分布式的 RDD 返回为一个单机的 Array 数组。 |
|
| count | 一个 action 算子,计数功能,返回一个 Long 类型的对象 | |
| take(n) | 取前N条数据 | |
| save | 将RDD的数据存入磁盘或者HDFS | |
| reduce | 返回T和原来的类型一致(RDD[T] => T) | |
| foreachPartition | foreachPartition 也是根据传入的 function 进行处理,但不 同处在于 function 的传入参数是一个 partition 对应数据的 iterator,而不是直接使用 iterator 的 foreach。 |
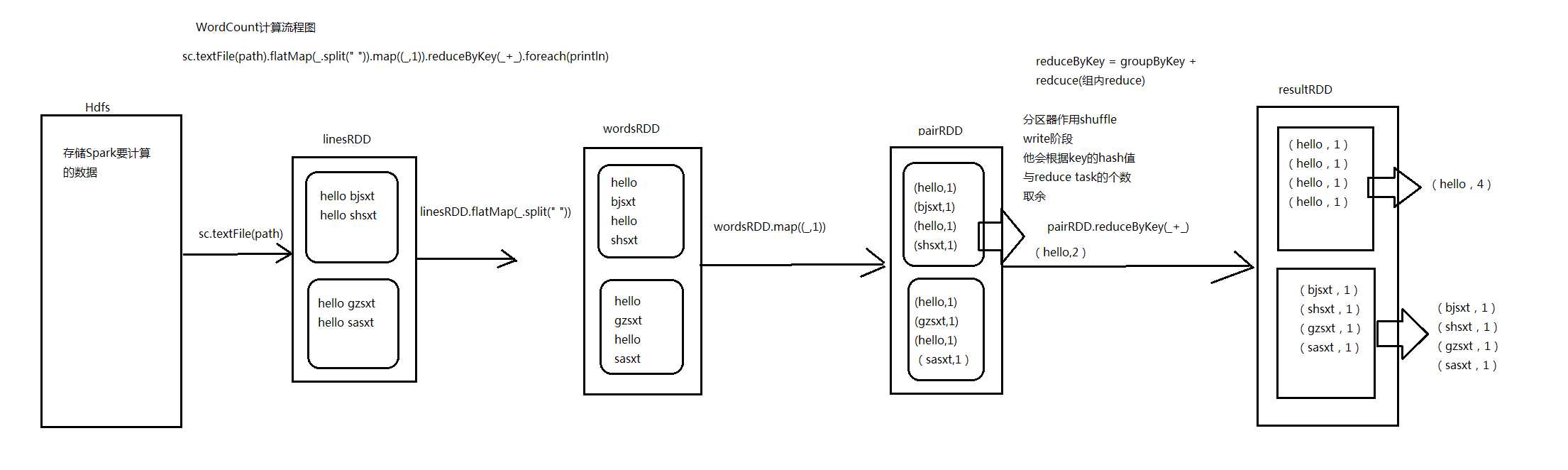
package com.hzf.spark.exerciseimport org.apache.spark.SparkConfimport org.apache.spark.SparkContext/** * 统计每一个单词出现的次数 */object WordCount{ def main(args:Array[String]):Unit={/** * 设置Spark运行时候环境参数 ,可以在SparkConf对象里面设置 * 我这个应用程序使用多少资源 appname 运行模式 */ val conf =newSparkConf().setAppName("WordCount").setMaster("local")/** * 创建Spark的上下文 SparkContext * * SparkContext是通往集群的唯一通道。 * Driver */ val sc =newSparkContext(conf)//将文本中数据加载到linesRDD中 val linesRDD = sc.textFile("userLog")//对linesRDD中每一行数据进行切割 val wordsRDD = linesRDD.flatMap(_.split(" ")) val pairRDD = wordsRDD.map{(_,1)}/** * reduceByKey是一个聚合类的算子,实际上是由两步组成 * * 1、groupByKey * 2、recuce */ val resultRDD = pairRDD.reduceByKey(_+_)/*(you,2)(Hello,2)(B,2)(a,1)(SQL,2)(A,3)(how,2)(core,2)(apple,1)(H,1)(C,1)(E,1)(what,2)(D,2)(world,2)*/ resultRDD.foreach(println)/*(Spark,5)(A,3)(are,2)(you,2)(Hello,2)*/ val sortRDD = resultRDD.map(x=>(x._2,x._1)) val topN = sortRDD.sortByKey(false).map(x=>(x._2,x._1)).take(5) topN.foreach(println)}}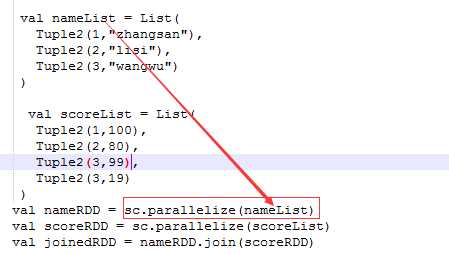

原文:http://www.cnblogs.com/haozhengfei/p/039dfec24294b39a2035b915dc96ef4c.html