先来看看HashMap.put方法的源代码
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) //如果该位置为null,说明没有哈希冲突,直接插入 --------------------(1) tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }
如果有两个线程A和B,都进行插入数据,刚好这两条不同的数据经过哈希计算后得到的哈希码是一样的,且该位置还没有其他的数据。所以这两个线程都会进入我在上面标记为1的代码中。假设一种情况,线程A通过if判断,该位置没有哈希冲突,进入了if语句,还没有进行数据插入,这时候CPU就把资源让给了线程B,线程A停在了if语句里面,线程B判断该位置没有哈希冲突(线程A的数据还没插入),也进入了if语句,线程B执行完后,轮到线程A执行,现在线程A直接在该位置插入而不用再判断。这时候,你会发现线程A把线程B插入的数据给覆盖了。发生了线程不安全情况。本来在HashMap中,发生哈希冲突是可以用链表法或者红黑树来解决的,但是在多线程中,可能就直接给覆盖了。
上面所说的是一个图来解释可能更加直观。如下面所示,两个线程在同一个位置添加数据,后面添加的数据就覆盖住了前面添加的。

发生在链表处插入数据发生线程不安全的情况也相似。
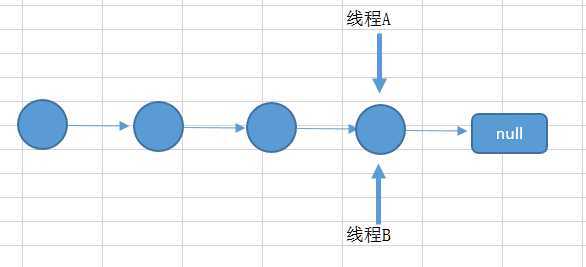
如两个线程都在遍历到最后一个节点,都要在最后添加一个数据,那么后面添加数据的线程就会把前面添加的数据给覆盖住。
我能想到的其他情况:在扩容的时候插入数据,有可能会把新插入的覆盖住;在扩容的时候删除数据,会删除不了。
下面是扩容方法resize()的部分代码
如果我在扩容时,在数据从旧数组复制到新数组过程中,这时候某个线程插入一条数据,这时候是插入到新数组中,但是在数据复制过程中,HashMap是没有检查新数组上的位置是否为空,所以新插入的数据会被后面从旧数组中复制过来的数据覆盖住。
如果在(2)刚执行后,某个线程就立刻想删除以前插入的某个元素,你会发现删除不了,因为table指向了新数组,而这时候新数组还没有数据。
1 Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//----------------------(1) 2 table = newTab;// ------------------------(2) 3 if (oldTab != null) { 4 for (int j = 0; j < oldCap; ++j) { 5 Node<K,V> e; 6 if ((e = oldTab[j]) != null) { 7 oldTab[j] = null; 8 if (e.next == null) 9 newTab[e.hash & (newCap - 1)] = e; //---------------在新数组上插入数组都不会检查该位置是否为null 10 else if (e instanceof TreeNode) 11 ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); 12 else { // preserve order 13 Node<K,V> loHead = null, loTail = null; 14 Node<K,V> hiHead = null, hiTail = null; 15 Node<K,V> next; 16 do { 17 next = e.next; 18 if ((e.hash & oldCap) == 0) { 19 if (loTail == null) 20 loHead = e; 21 else 22 loTail.next = e; 23 loTail = e; 24 } 25 else { 26 if (hiTail == null) 27 hiHead = e; 28 else 29 hiTail.next = e; 30 hiTail = e; 31 } 32 } while ((e = next) != null); 33 if (loTail != null) { 34 loTail.next = null; 35 newTab[j] = loHead; //-------------------在新数组上插入数组都不会检查该位置是否为null 36 } 37 if (hiTail != null) { 38 hiTail.next = null; 39 newTab[j + oldCap] = hiHead; //------------在新数组上插入数组都不会检查该位置是否为null 40 } 41 } 42 } 43 } 44 }
原文:http://www.cnblogs.com/FirstClass/p/6501290.html