最关键的是构造决策树的时候的属性划分,怎样分属性分枝最合适。用到了信息熵,信息增益的概念。
经典的方法有ID.3等。
从信息论知识中我们直到,期望信息越小,信息增益越大,从而纯度越高。所以ID3算法的核心思想就是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。
另有ID3的优化算法 C4.5,这两种算法的解释参考:
http://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html
首先 ID3(注:上面是基本描述,重点看下面代入的例子,就能懂了)
设D为用类别对训练元组进行的划分,则D的熵(entropy)表示为:
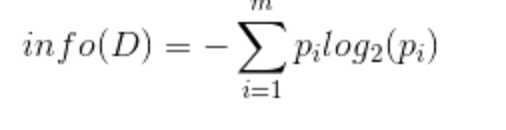
其中pi表示第i个类别在整个训练元组中出现的概率,可以用属于此类别元素的数量除以训练元组元素总数量作为估计。熵的实际意义表示是D中元组的类标号所需要的平均信息量。
现在我们假设将训练元组D按属性A进行划分,则A对D划分的期望信息为:
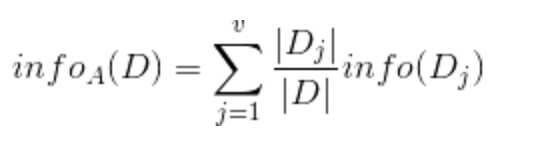
而信息增益即为两者的差值:
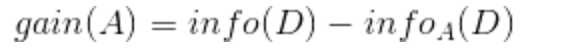
例子:
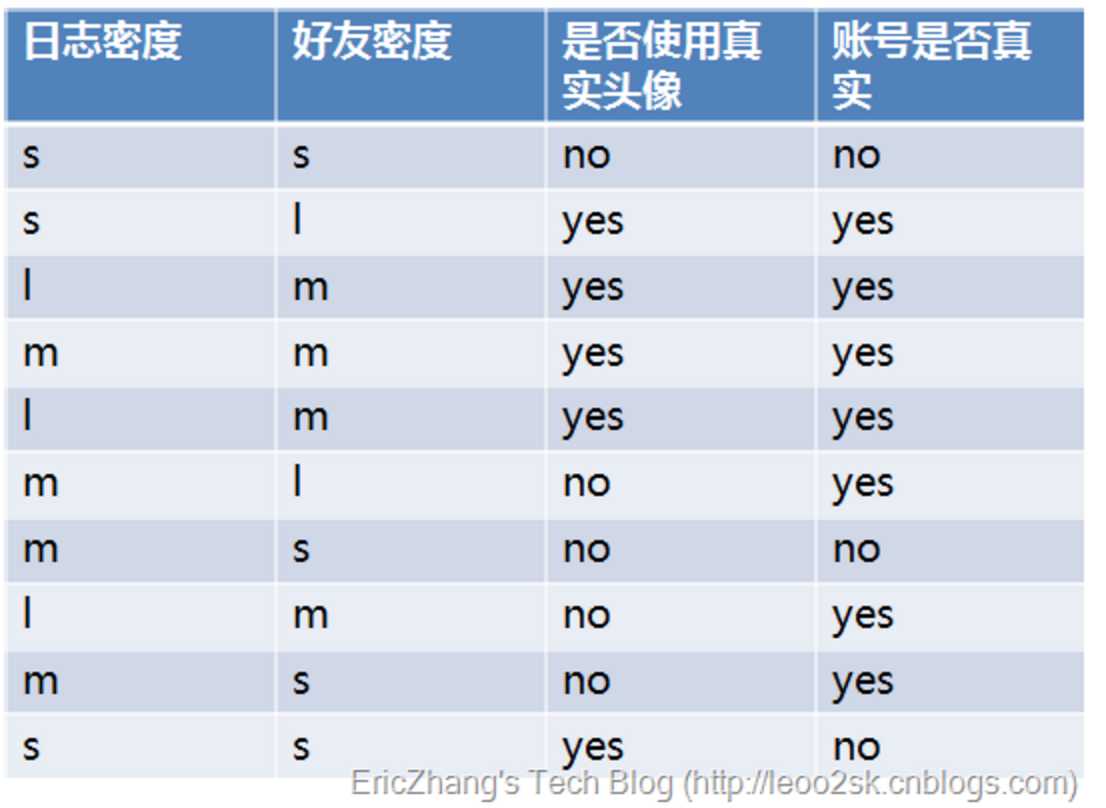
其中s、m和l分别表示小、中和大。
设L、F、H和R表示日志密度、好友密度、是否使用真实头像和账号是否真实,下面计算各属性的信息增益。
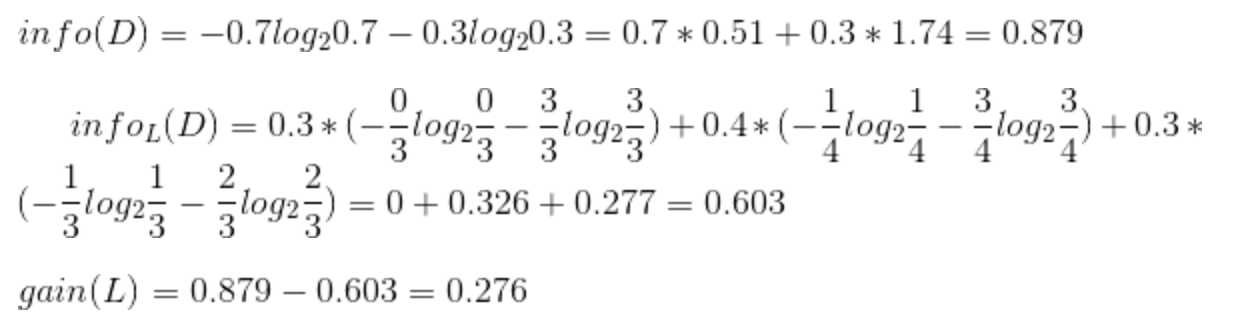
因此日志密度的信息增益是0.276。
用同样方法得到F和H的信息增益分别为0.553和0.033。
因为F具有最大的信息增益,所以第一次分裂选择F为分裂属性,分裂后的结果如下图表示:
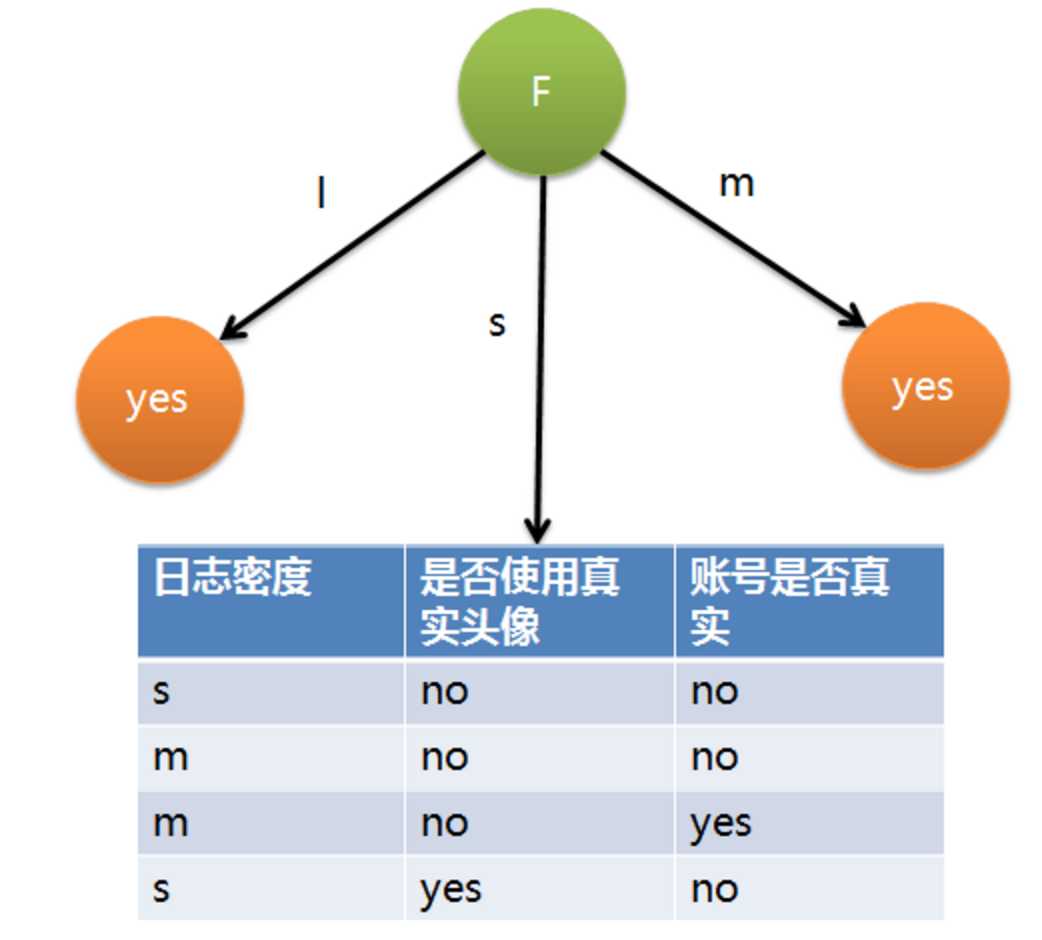
上面为了简便,将特征属性离散化了,其实日志密度和好友密度都是连续的属性。对于特征属性为连续值,可以如此使用ID3算法:
先将D中元素按照特征属性排序,则每两个相邻元素的中间点可以看做潜在分裂点,从第一个潜在分裂点开始,分裂D并计算两个集合的期望信息,具有最小期望信息的点称为这个属性的最佳分裂点,其信息期望作为此属性的信息期望。(没太懂)
ID3算法存在一个问题,就是偏向于多值属性,例如,如果存在唯一标识属性ID,则ID3会选择它作为分裂属性,这样虽然使得划分充分纯净,但这种划分对分类几乎毫无用处。ID3的后继算法C4.5使用增益率(gain ratio)的信息增益扩充,试图克服这个偏倚。
C4.5算法首先定义了“分裂信息”,其定义可以表示成:

C4.5选择具有最大增益率的属性作为分裂属性,其具体应用与ID3类似,不再赘述。
在决策树构造过程中可能会出现这种情况:所有属性都作为分裂属性用光了,但有的子集还不是纯净集,即集合内的元素不属于同一类别。在这种情况下,由于没有更多信息可以使用了,一般对这些子集进行“多数表决”,即使用此子集中出现次数最多的类别作为此节点类别,然后将此节点作为叶子节点。
在实际构造决策树时,通常要进行剪枝,这时为了处理由于数据中的噪声和离群点导致的过分拟合问题。剪枝有两种:
先剪枝——在构造过程中,当某个节点满足剪枝条件,则直接停止此分支的构造。
后剪枝——先构造完成完整的决策树,再通过某些条件遍历树进行剪枝。
关于剪枝的具体算法这里不再详述,有兴趣的可以参考相关文献。
原文:http://www.cnblogs.com/charlesblc/p/6506162.html