通过pip安装Requests库后就可以进行爬虫了
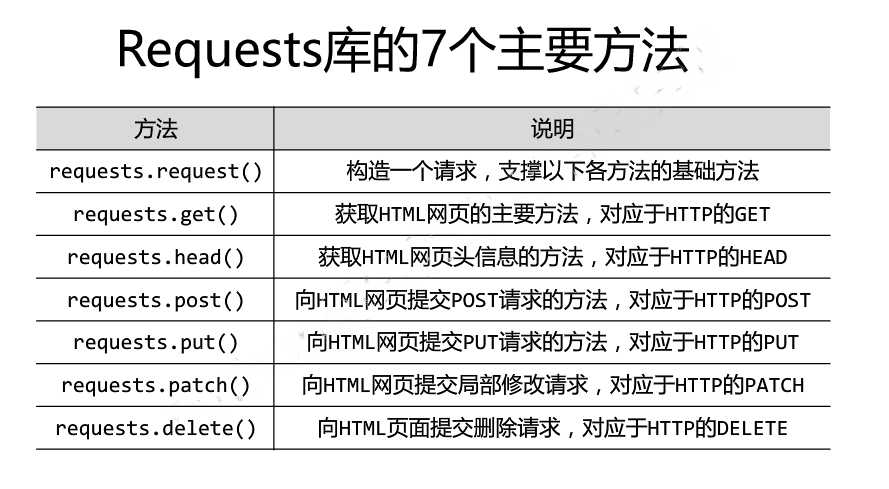
Requests库的7个主要方法如下:
Response对象的属性: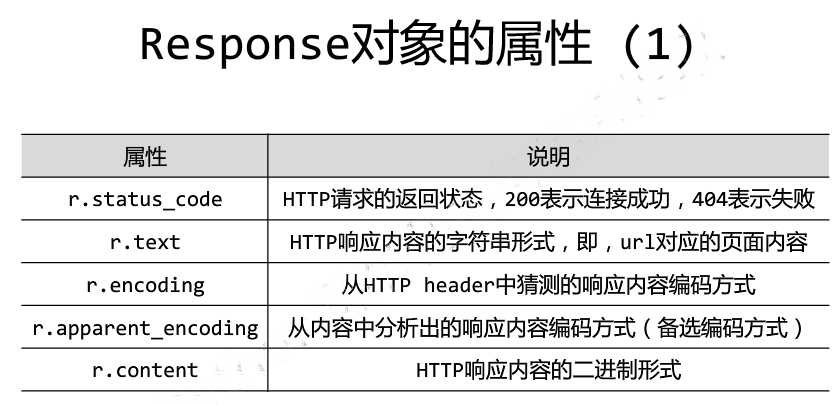
Requests库的异常:

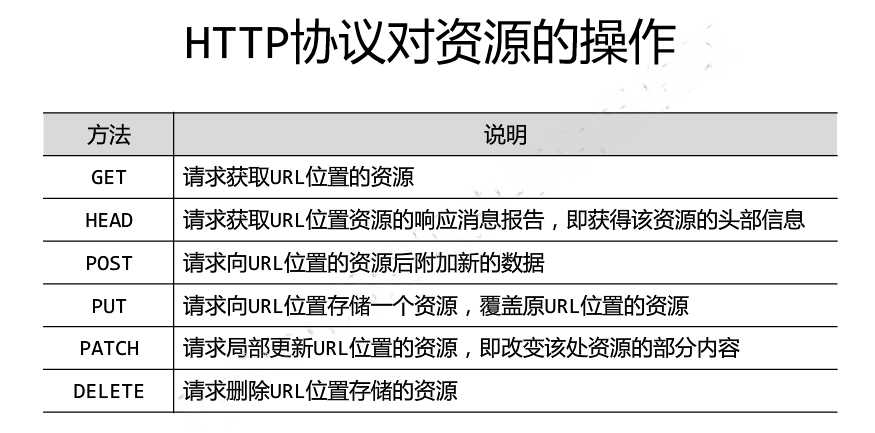
HTTP协议对资源的操作,分别对应Requests库的6个方法:
request中12个参数的的功能:
params:字典或字节序列,作为参数增加到url中
data :字典、字节序列或文件对象,作为Request的内容
json :JSON格式的数据,作为Request的内容
headers:字典,HTTP定制头
cookies :字典或CookieJar,Request中的cookie
auth :元祖,支持HTTP认证功能
files :字典类型,传输文件
timeout :设定超时时间,秒为单位
proxies :字典类型,设定访问代理服务器,可以增加登录认证
allow_redirects:True/False,默认为True,重定向开关
stream :True/False,默认为True,获取内容立即下载开关
verify :True/False,默认为True,认证SSL证书开关
cert :本地SSL证书路径
下面介绍一些常用参数的用法:
Requests库的head()方法使用:
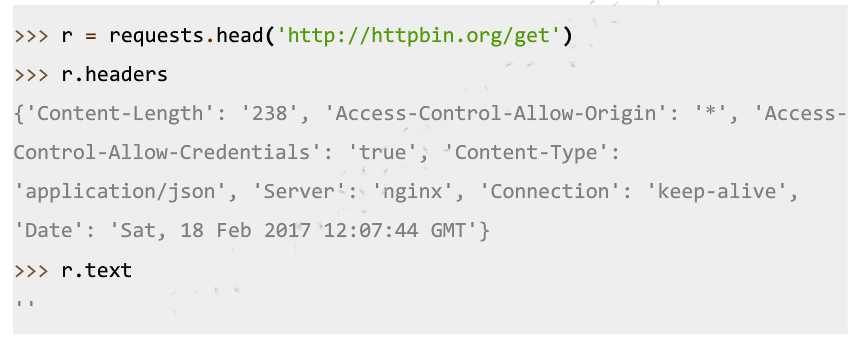
Requests库的host()方法使用:


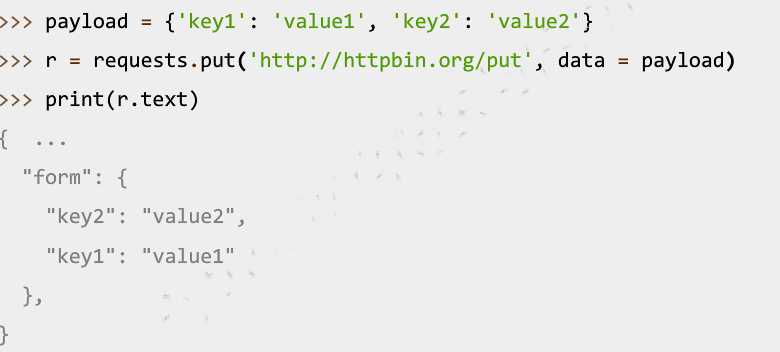
Requests库的put()方法使用:
params参数的使用:

data参数的使用:

json参数的使用:

headers参数的使用:

files参数的使用:

timeout参数的使用:
![]()
proxies参数的使用:

下面写一个通用爬虫代码:
1 import requests 2 3 def getHTMLText(url): 4 try: 5 r = requests.get(url, timeout=30) 6 r.raise_for_status() 7 r.encoding = r.apparent_encoding 8 return r.text 9 except: 10 return "产生异常" 11 12 if __name__ == "__main__": 13 url = "http://www.baidu.com" 14 print(getHTMLText(url))
原文:http://www.cnblogs.com/xingkongyihao/p/6556996.html