1、什么是系统调用?
Linux内核中设置了一组用于实现各种系统功能的子程序,称为系统调用。
Linux的系统调用作为c库的一部分提供,用户可以通过系统调用命令在自己的应用程序中调用它们。
#include <linux/unistd.h> /* all system calls need this header */。
2、系统调用与一般库函数的区别
一般库函数始终运行在用户态,而系统调用要通过int 0x80语句陷入内核态,该系统调用实现的功能实际上是由对应的内核的函数来完成。
3、系统调用的过程
下图展示了一个系统调用的流程
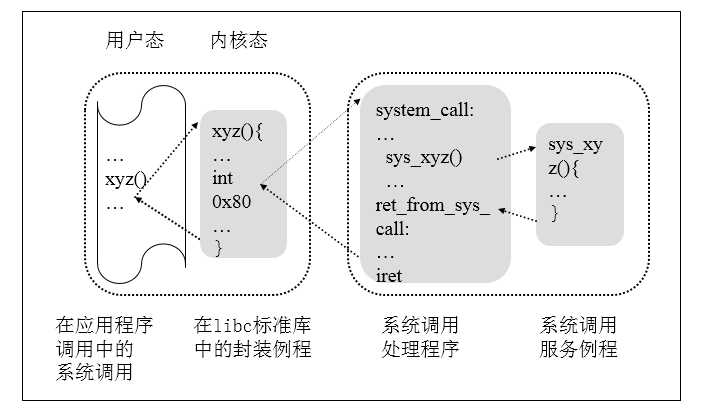
1、在我们自己的程序中调用了一个库函数xyz();
2、库函数的实现中,首先做一些准备工作(包括将系统调用号,参数等存入对应的寄存器),准备好之后调用int 0x80,陷入内核
3、内核首先调用system_call()函数,进行参数检查,根据系统调用号获得对应的系统调用服务例程(对应的内核函数)
4、执行该内核函数
5、内核函数执行完毕后转入ret_from_sys_call()例程,返回用户空间
6、库函数实现中根据返回值,再确定库函数的返回值
7、库函数返回,整个系统调用完成。
4、buffered IO 和 unbuffered IO
unbuffered IO :不要被名字欺骗了,实际上在内核中实际上也有缓冲区。以write为例,如果内核缓冲区是100,而每次write 10,那么write 10次内核函数才将数据写入磁盘。这样做的原因是:磁盘IO是一件非常费时的事,通过缓冲来提高系统性能。同样如果调用read,内核会一次读入多块内存数据至内核缓冲区,下次再调用read时,先检查内核缓冲区有没有需要的数据,如果没有再进行磁盘IO。
buffered IO:在用户空间还有一个缓冲区,以fwrite为例,如果内核缓冲区是100,用户空间缓冲区是50,每次fwrite10,那么fwrite 5次之后再进行系统调用write,一共进行两write系统调用内核函数就进行磁盘IO。也就是说,通过用户空间的缓冲区,可以减少系统调用的次数,提高IO性能。
下面是内核缓冲区的介绍
内核模式和用户模式之间的切换需要消耗时间,但相比之下,磁盘的I/O操作消耗的时间更多,为了提高效率,内核也使用缓冲区技术来提高对磁盘的访问速度。磁盘是数据块的集合,内核会对磁盘上的数据块做缓冲。内核将磁盘上的数据块复制到内核缓冲区中,当一个用户空间中的进程要从磁盘上读数据时,内核一般不直接读磁盘,而是将内核缓冲区中的数据复制到进程的缓冲区中。当进程所要求的数据块不在内核缓冲区时,内核会把相应的数据块加入到请求队列,然后把该进程挂起,接着为其他进程服务。一段时间之后(其实很短的时间),内核把相应的数据块从磁盘读到内核缓冲区,然后再把数据复制到进程的缓冲区中,最后唤醒被挂起的进程。
linux系统调用、buffered IO、unbuffered IO,布布扣,bubuko.com
linux系统调用、buffered IO、unbuffered IO
原文:http://www.cnblogs.com/tidsp/p/3756772.html