最近在做基于本体概念的语义相似度的计算理论研究及实现,现在做一个相关的总结,以便今后查找或者供他人借鉴和学习。
做这个研究的目的是为了进行Agent能力模型中目标和能力的匹配,从而进行目标对能力的一个择优过程。在我们的能力模型中,capability表示为C(InConstaints,OutContaints),目标goal表示为G(TriggerConditions, FinalStates)。而InConstaints,OutContaints,TriggerConditions, FinalStates都是由上下文状态(ContextState)集合组成。ContextState是由一个三元组CS=<argument1,predicate,argument2>表示,在模型中都表示为argument1_predicate_argument2例如:
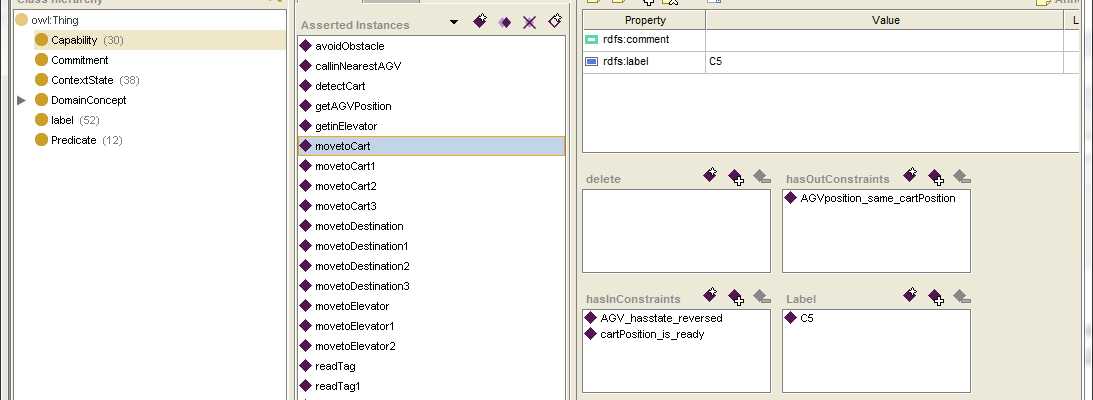
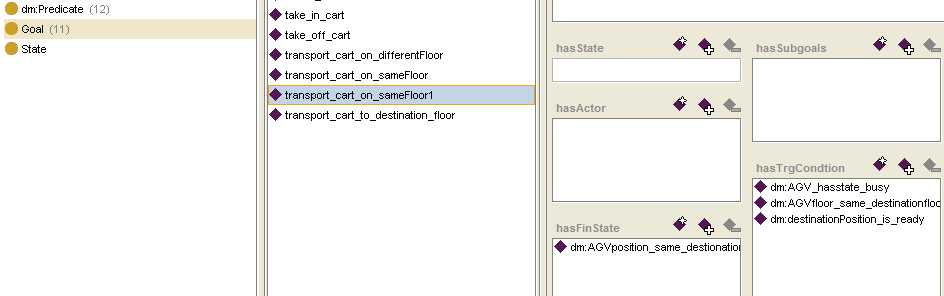
由此可见,在计算目标和能力的相似度之前需要计算两个ContextState之间的相似度。在此,给定两个ContextStates:CS1:arg11_p1_arg12和CS2:arg21_p2_arg22,它们之间三种匹配关系:
1.精确(完全)匹配(AccurateMatch),当arg11和arg21、arg12和arg22、p1和p2都分别等价;
2.不相交匹配(DisjointMatch):当p1和p2不等价(或者不相同);
3.包含匹配(ContainedMatch):当p1和p2等价,arg11和arg21、arg12和arg22存在一对有包含关系,即一个概念所在的类包含另一个概念所在的类。
根据两个ContextState所处的匹配关系来决定它们之间的相似度计算方法。有如下计算方法:1.CS1和CS2不相交匹配,sim(CS1,CS2)=0;2.CS1和CS2精确匹配,sim(CS1,CS2)=1;3.CS1和CS2包含匹配,若sim(arg11,arg21)=1,则sim(CS1,CS2)=sim(arg12,arg22),若sim(arg12,arg22)=1,则sim(CS1,CS2)=sim(arg11,arg21)。
写到这里呢,大家肯定不明白sim(arg11,arg21)是怎样计算的,我们采用了《CONCEPT VECTOR FOR SIMILARITY MEASUREMENT BASED ON HIERARCHICALDOMAIN STRUCTURE》这篇论文中写到的用概念向量来计算本体中两个类之间的相似度。 其计算方法入下几张图所示:


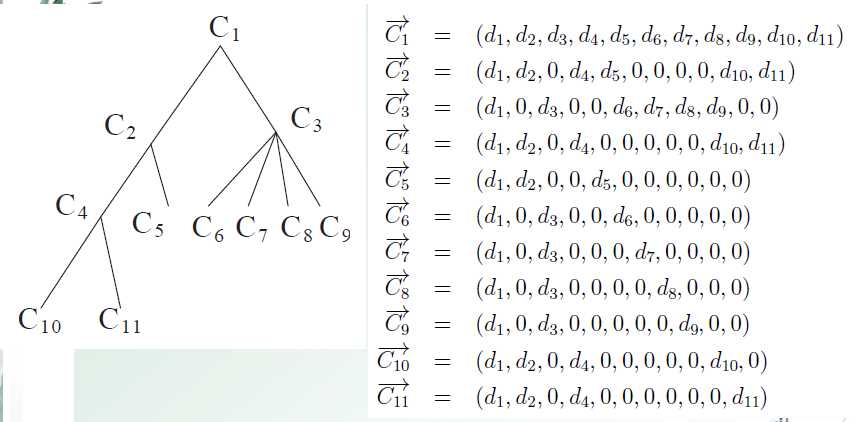
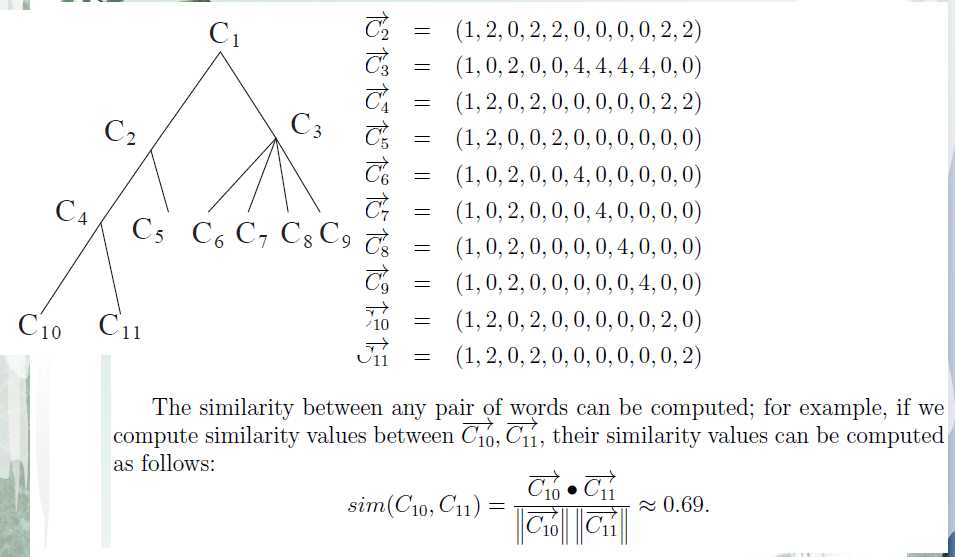
有了概念间的相似度计算方法,ContextStates间的计算方法后,我们就可以计算能力模型中目标和能力的相似度了。如下图:

由于晚上时间关系,一些内容直接以截图形式表示,目前已用代码实现了根据目标和能力的相似度大小来进行目标对能力的一个择优过程,以及将匹配关系保存到XML文档中。等代码完善差不多时,会考虑补充代码说明。
本文属作者原创,转载请注明出处:http://www.cnblogs.com/shuangmeier/p/6638266.html。有问题欢迎在评论区批评指正。
原文:http://www.cnblogs.com/shuangmeier/p/6638266.html