以设计垃圾邮件分类器为例,当我们设计机器学习算法时,先在24小时内设计出一个简单的算法,跑一遍训练数据,再根据数据的反馈结果(高偏差,高方差,或对某一类数据误判比例过高等等)调整我们的算法,反复迭代优化
一,提取特征
从大量垃圾邮件训练数据中找出出现频率最高的10,000到50,000个单词,以该单词是否出现为特征,出现为1,未出现为0

二,提高分类器的准确性
每一个算法性能的提高必须具体问题具体分析,没有行之四海皆准的方法提高机器学习的准确性,
三,误差分析(提高算法准确性的分析方法)
解决机器学习问题一种推荐方法:
如,我们有500封信件然而我们的算法把其中100封分错了类,观察这100封邮件,我们发现大多数邮件尝试偷取密码,我们就可以加入是否偷取密码这个特征
必须以算法准确率为优化的指标,每次优化必须看准确率为标准

四,偏斜类(Skewed Classed)
当训练数据中类型的分布比例差距较大时,如01分类中0为0的比例是99%,1的比例是1%,准确性这个量化指标就不够用了,
因为不用机器学习算法直接预测y=0,准确性就高达99%,这个时候就需要另外另个量化指标了查准率(Precsision)和召回率(Recall),计算查准率和召回率时分类为1的类为比例极少的类
| Actual 1 | Actual 0 | |
| Predict 1 |
True Positive |
False Positive |
| Predict 0 | False Negative | True Negative |
\(Precision = \frac{True Positive}{Predicted} = \frac{True Positive}{True Positive + False Positive}\)
\(Recall = \frac{True Positive}{Predicted} = \frac{True Positive}{True Positive + False Negative}\)
查准率和召回率时一个问题的两面,我们一般我们很难做到同时做到高查准率和高召回率,一般取其平衡
一般情况下我们可以通过修改\(h_\theta(X)\)的分类阈值调整查准率和召回率,
\(h_\theta(X) \geqslant 0.5 \Rightarrow h_\theta(X) \geqslant 0.7\),查准率提高,召回率降低(千真万确)
\(h_\theta(X) \geqslant 0.5 \Rightarrow h_\theta(X) \geqslant 0.3\),召回率提高,查准率降低(宁杀错,勿放过)
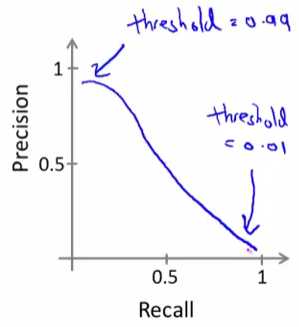
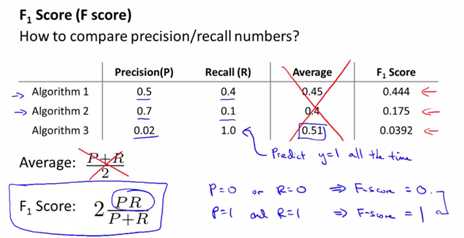
那如何自动取舍查准率和召回率来评估算法性能?\(2\frac{PR}{P+R}\)
原文:http://www.cnblogs.com/xchaos/p/6697039.html