前言
数据库是java开发过程必不可少的数据存储工具,通常我们分为关系型数据库和非关系型数据库,上一篇中已经简单的介绍了redis,这里说一说关系型数据库mysql。
1、mysql引擎
这里只说我们常见的两种引擎,MyISAM和Innodb,其他相关的引擎有兴趣的可以自行了解。首先我们简单的说说这两种引擎的区别。
1)MyISAM,不支持事务,支持全文索引、表锁,在磁盘上有三个与表名相同的文件,.frm文件存储表结构,.MYD文件存储表数据,.MYI文件存储表索引,MyISAM不缓存数据,只缓存索引。
2)InnoDB,支持事务、外键、行锁和非锁定读,即默认情况下读不产生锁。InnoDB由一系列后台线程和一大块内存组成。默认情况下,后台线程有7个,4个IO线程,1个master thread,1个lock监控线程,1个error监控线程。
在实际开发中,由于事务和行级锁等机制的原因,Innodb可能接触的更多一些。MyISAM更多用于查询,尤其是select * from tableName,可以直接获取到数值,不需要全表扫描。
2、mysql结构
mysql的结构如下图所示,个人十分喜欢这张图,通过这张图还可以大致了解一条SQL语句的执行过程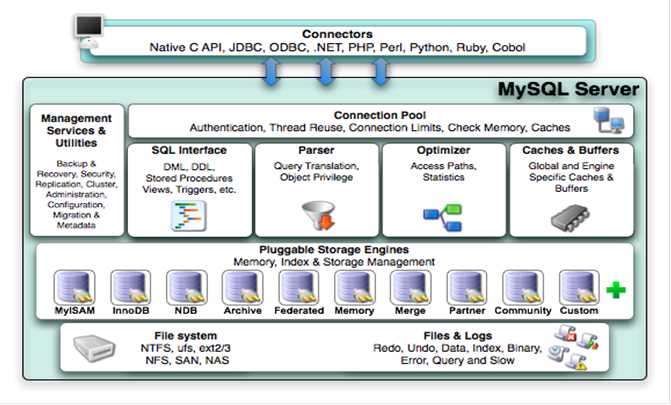
select * from tableName where name like ‘_zhang‘ select * from tableName where name like ‘%zhang‘
上述两个sql无法使用name列上的索引
select * from tableName where name like ‘zhang_‘ select * from tableName where name like ‘zhang%‘
上述两个sql可以使用name列上的索引
还有一点需要注意的是,对于变化较少的字段不建议添加索引,如性别的列,通常的值是0和1或者true和false,此列添加索引不会有太大的速度提升。一个表的索引个数也不建议过多,增删改数据的同时还要维护索引,过多的索引会降低数据库的效率。
4、mysql优化
mysql的优化从三个方面入手,包括创建表时的优化,索引的创建以及sql的优化
1)创建表时的优化
a)为表添加主键ID,最好使用无符号的int类型,设置成自增(注意分表时id重复的情况)
b)针对字典表可以考虑使用ENUM类型代替字符串,如果插入的值不在ENUM规定值内,则自动使用‘‘空字符串代替
c)尽量使用NOT NULL,使用NULL需要额外的空间,而且NULL无法使用索引
d)使用PROCEDURE ANALYSE()函数取得建议,根据表中数据进行分析,所以需要数据库中有一定的数据做基础,如:
SELECT * FROM sys_user PROCEDURE ANALYSE();
越小的列越快,在考虑日后数据扩展的前提下,尽量使用较小存储单元的类型,如字典表中数据较少时,主键可以放弃使用INT,用MEDIUMINT、SMALLINT来代替,甚至使用更小的TINYINT,如果不需要记录时间,可以使用DATE代替DATETIME
e)使用固定长度的表,如果表中所有的列都是固定长度的,表会被认为是“static”的,会加快查询速度,如果列中包含varchar、text或blog之一,则表不是固定长度的。固定长度的表由于定长,可以根据偏移量计算下一条数据的位置,而变长的表只能通过寻找下一条数据的主键。固定长度的表的缺点就是会造成空间浪费,因为无论存储数据大小,都会分配定长的空间。注:mysql字段占用空间与类型有关,如int(11)和int(3)都占用四个字节的长度,区别是根据存储数据的长度自动补全零位的个数,存储1111时,由于长度是4,int(3)不需要补零,int(11)会自动补全7个0
f)表分割,表分割可以分为水平分割和垂直分割。水平分割就是建立结构相同但是表名不同的表,将数据按照hash运算之后存储在对应的表中,如sys_user_1,sys_user_2等;垂直分割是将表中一些不常用的或者会经常更新导致查询缓存失效的列分割出来,如家庭住址,最后登录时间等字段。注:被分割的字段不能经常被JOIN,否则会极大降低性能
g)数据库读写分离
2)索引的创建
索引的创建就是在适合的列上添加索引,从而达到加快查询速度的效果,上面已经提及,这里不再累述。
3)SQL的优化
a)使用explain关键字解析sql语句,如:
EXPLAIN SELECT * FROM (SELECT user_sex,COUNT(*) AS counts FROM sys_user u GROUP BY u.user_sex) count_t WHERE count_t.counts > 1
结果如下所示:

通常我们关注的是type这一列,这里不要求记住所有,只需要记住几个典型的,并且了解哪个更优即可,如const、eq_ref、ref、all等。这里有一篇文章,大家可以参考了解一下:
http://blog.csdn.net/seelye/article/details/46453651
b)在查询结果明确只有一条的情况下,且该列上没有索引,使用LIMIT 1可以在查询到数据之后直接返回,避免全表扫描;判断一条数据是否存在时,使用SELECT 1可以提高查询速度,SELECT 1 > SELECT any column > SELECT *
c)避免SELECT *,用什么数据取什么列,减少网络数据传输
d)尽量少用having、in、not in、is null等关键字或判断,对于having,可以使用子查询来代替;in和not in可以使用exists和not exists代替,如果数据连续,也可以使用between and代替。
5、Innodb文件结构
InnoDB表由共享表空间或独立表空间、日志文件组和表结构文件组成。可以使用show variables like ‘innodb_file_per_table‘查看是否开启了独立表空间,结果为ON时表示开启独立表空间;OFF时表示使用共享共享表空间。
select * from tableName where id =1 lock in share mode
select * from tableName where id =1 for update
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
原文链接:http://www.cnblogs.com/1ning/p/6705129.html
原文:http://www.cnblogs.com/1ning/p/6705129.html