语义分析,我是一个初学者,有很多东西,需要理论和实践结合后,才能理解的相对清楚。
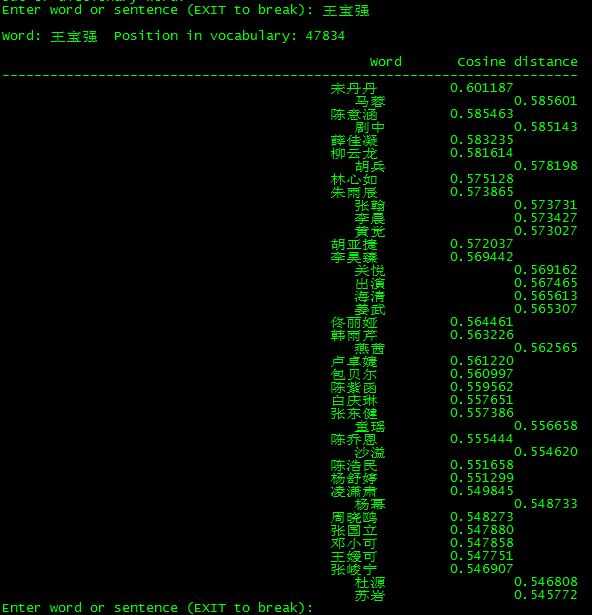
今天,我就在语义理解中基于背景语料的情况,实现语义上下文的预测,比如,我说“王宝强”,你会想到什么?别告诉没有“马蓉”,别告诉我没有“泰囧”, 再比如,我说“白百何”, 不要说你没有想到“出轨”两个字。。。这就是语义预测,也就是相关信息的映射。这个,就是word2vec的功劳了。
word2vec是谷歌开源的一个语义预测框架。主要是将词映射到一个维度空间上,每个词都有n个不同维度的信息,用vector表示,词与词之间的关系,就用vec之间的cosine值来表示,consine值越大,说明这两个词之间的关系越近。详细的word2vec的介绍,自行查阅相关资料。
不过,这里,有必要说一下的就是word2vec有两个重要的模型:
这两个模型,对应不同的使用场景。
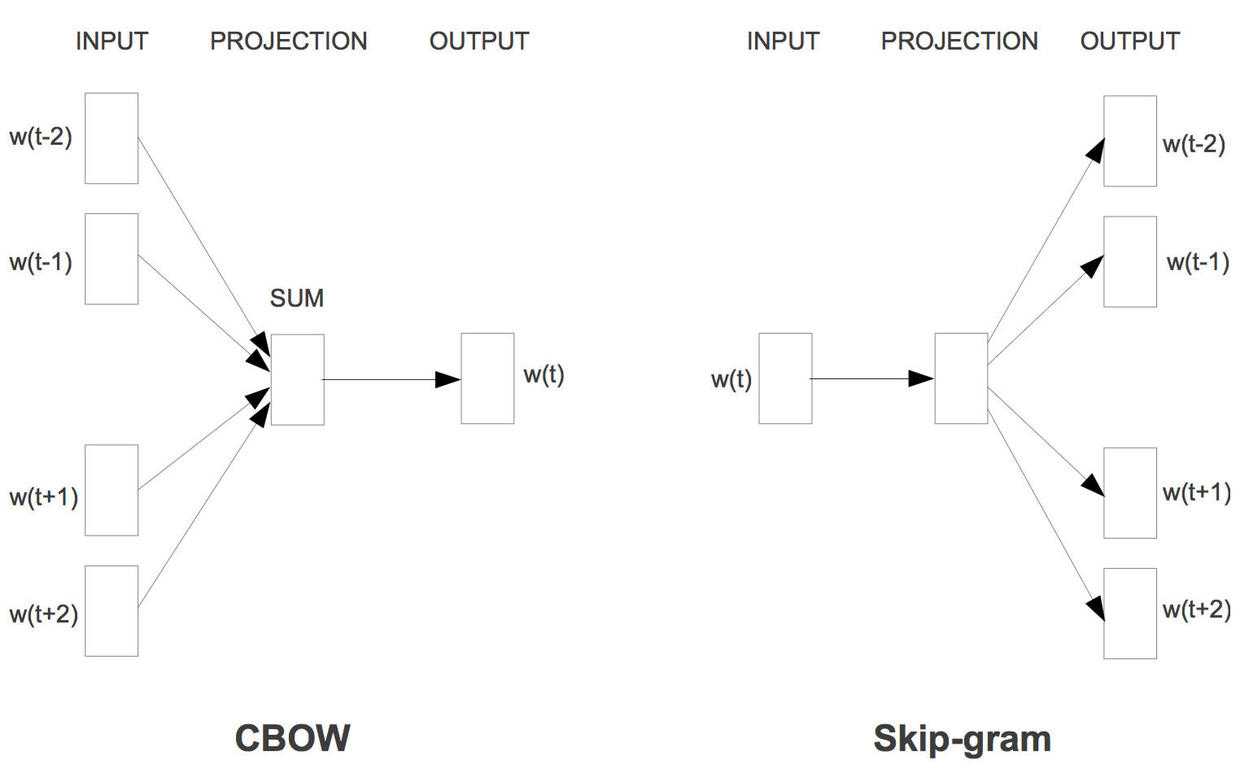
word2vec的一个重要数据逻辑,就是贝叶斯定律,通俗的说,这个定理就是指:在某件事情发生的前提下,再发生另外一件事情的概率。具体的理论,自行学习去吧!
ansj_seg,是中科院开源的一个中文分词工具。这是一个ictclas的java实现.基本上重写了所有的数据结构和算法.词典是用的开源版的ictclas所提供的.并且进行了部分的人工优化。
今天这篇博文的主要内容,就是通过ansj_seg对搜狗实验室的语料进行分词,然后用word2vec的skip-gram模型进行预测上下文。正如前面说的,说到王宝强,白百何之类的人物名称,你会得到什么信息。。。
下载sogou实验室的语料,地址:http://www.sogou.com/labs/resource/ca.php
关于这个语料的内容,直接去搜狗实验室的网站上了解吧。这里不多说。我直接下载的zip包。
下载ansj_seg的jar包,这里我用的是最新版本5.1.1.下载地址:http://central.maven.org/maven2/org/ansj/ansj_seg/5.1.1/ansj_seg-5.1.1.jar
获取这个jar包,官方要求最好配合最新版本的nlp-lang一起用,我这里也是最新版本。这个的下载地址:http://central.maven.org/maven2/org/nlpcn/nlp-lang/1.7.2/nlp-lang-1.7.2.jar
下载word2vec的源码,这里下载的是github上的master版本。下载地址:https://github.com/svn2github/word2vec
下面进行具体的操作。
1》将语料进行预处理,取出其中的content。
cat news_tensite_xml.dat | iconv -f gbk -t utf-8 -c | grep "<content>" > corpus.txt
这里,iconv指令需要了解一点点基础知识,他是一个字符集转换工具,-f表示源字符集,-t表示转换后的编码字符集,上述指令中是将gbk字符集转换为utf-8的字符集,-c表示丢弃任何无效的字符(基于字符集)
2》通过java程序,处理content,基于ansj将其中的内容进行分词。
java代码如下:
/** * @author "shihuc" * @date 2017年4月12日 */ package ansjDemo; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.PrintWriter; import java.io.Reader; import java.util.HashSet; import java.util.Set; import org.ansj.domain.Result; import org.ansj.domain.Term; import org.ansj.splitWord.analysis.ToAnalysis; /** * @author chengsh05 * */ public class AnsjSegDemo { /** * @param args */ private static final String TAG_START_CONTENT = "<content>"; private static final String TAG_END_CONTENT = "</content>"; private static final String INPUT_FILE = "./src/ansjDemo/corpus.txt"; private static final String OUTPUT_FILE = "./src/ansjDemo/corpus_out.txt"; public static void main(String[] args) throws Exception { BufferedReader reader = null; PrintWriter pw = null; Reader fr = null; try { System.out.println("开始处理分词..."); File file = new File(INPUT_FILE); fr = new FileReader(file); reader = new BufferedReader(fr); pw = new PrintWriter(OUTPUT_FILE); long start = System.currentTimeMillis(); int totalCharactorLength = 0; int totalTermCount = 0; Set<String> set = new HashSet<String>(); String temp = null; while ((temp = reader.readLine()) != null) { temp = temp.trim(); if (temp.startsWith(TAG_START_CONTENT)) { //System.out.println("处理文本:" + temp); int end = temp.indexOf(TAG_END_CONTENT); String content = temp.substring(TAG_START_CONTENT.length(), end); totalCharactorLength += content.length(); Result result = ToAnalysis.parse(content); for (Term term : result) { String item = term.getName().trim(); totalTermCount++; pw.print(item + " "); set.add(item); } pw.println(); } } long end = System.currentTimeMillis(); System.out.println("共" + totalTermCount + "个Term,共" + set.size() + "个不同的Term,共 " + totalCharactorLength + "个字符,每秒处理字符数:" + (totalCharactorLength * 1000.0 / (end - start))); } finally { if(fr != null){ fr.close(); } if(reader != null){ reader.close(); } if(pw != null){ pw.close(); } } } }
编译的日志输出,可以反映出一些逻辑:
开始处理分词... log4j:WARN No such property [datePattern] in org.apache.log4j.RollingFileAppender. [2017-04-12 16:56:09] [ WARN] [main] [org.ansj.util.MyStaticValue.<clinit>(MyStaticValue.java:91)] - not find library.properties in classpath use it by default ! [2017-04-12 16:56:09] [ INFO] [main] [org.ansj.dic.impl.File2Stream.toStream(File2Stream.java:29)] - path to stream library/ambiguity.dic [2017-04-12 16:56:09] [ERROR] [main] [org.ansj.library.AmbiguityLibrary.init(AmbiguityLibrary.java:112)] - Init ambiguity library error :org.ansj.exception.LibraryException: path :library/ambiguity.dic file:E:\2016\workwps\RProject\library\ambiguity.dic not found or can not to read, path: library/ambiguity.dic [2017-04-12 16:56:09] [DEBUG] [main] [org.ansj.library.DicLibrary.init(DicLibrary.java:167)] - begin init dic ! [2017-04-12 16:56:09] [ INFO] [main] [org.ansj.dic.impl.File2Stream.toStream(File2Stream.java:29)] - path to stream library/default.dic [2017-04-12 16:56:09] [ERROR] [main] [org.ansj.library.DicLibrary.init(DicLibrary.java:195)] - Init ambiguity library error :org.ansj.exception.LibraryException: path :library/default.dic file:E:\2016\workwps\RProject\library\default.dic not found or can not to read, path: library/default.dic [2017-04-12 16:56:10] [ INFO] [main] [org.ansj.library.DATDictionary.loadDAT(DATDictionary.java:54)] - init core library ok use time : 468 [2017-04-12 16:56:10] [ INFO] [main] [org.ansj.library.NgramLibrary.<clinit>(NgramLibrary.java:17)] - init ngram ok use time :358 共388487481个Term,共941062个不同的Term,共 622383693个字符,每秒处理字符数:1461210.679044084
3》编译word2vec
编译之前,看看我的机器配置吧,个人觉得还是不错的机器。
[root@localhost word2vec-master]# cat /proc/cpuinfo| grep "processor"| wc -l 24 [root@localhost word2vec-master]# free -h total used free shared buff/cache available Mem: 31G 2.9G 17G 33M 10G 27G Swap: 15G 0B 15G
现在,开始对源码进行编译。
[root@localhost word2vec-master]# make gcc word2vec.c -o word2vec -lm -pthread -O3 -march=native -Wall -funroll-loops -Wno-unused-result gcc word2phrase.c -o word2phrase -lm -pthread -O3 -march=native -Wall -funroll-loops -Wno-unused-result gcc distance.c -o distance -lm -pthread -O3 -march=native -Wall -funroll-loops -Wno-unused-result distance.c: In function ‘main’: distance.c:31:8: warning: unused variable ‘ch’ [-Wunused-variable] char ch; ^ gcc word-analogy.c -o word-analogy -lm -pthread -O3 -march=native -Wall -funroll-loops -Wno-unused-result word-analogy.c: In function ‘main’: word-analogy.c:31:8: warning: unused variable ‘ch’ [-Wunused-variable] char ch; ^ gcc compute-accuracy.c -o compute-accuracy -lm -pthread -O3 -march=native -Wall -funroll-loops -Wno-unused-result compute-accuracy.c: In function ‘main’: compute-accuracy.c:29:109: warning: unused variable ‘ch’ [-Wunused-variable] char st1[max_size], st2[max_size], st3[max_size], st4[max_size], bestw[N][max_size], file_name[max_size], ch; ^ chmod +x *.sh
4》对java分词后的文件,基于word2vec进行训练预测,主要基于skip-gram。
[root@localhost resouce]# bash word2vec_train.sh Starting training using file corpus_out.txt Vocab size: 330438 Words in train file: 388694484 Alpha: 0.000002 Progress: 100.00% Words/thread/sec: 11.20k begin: 1491990795 end: 1491998336 gap: 7541
下面,看看我的word2vec_train.sh的内容是啥吧:
#!/bin/bash BEGIN_TIME=`date +"%Y-%m-%d %H:%M:%S"` word2vec -train corpus_out.txt -output vectors.bin -cbow 0 -size 200 -window 5 -negative 0 -hs 1 -sample 1e-3 -threads 50 -binary 1 END_TIME=`date +"%Y-%m-%d %H:%M:%S"` time1=`date -d "$BEGIN_TIME" +%s` time2=`date -d "$END_TIME" +%s` gap=$[$time2-$time1] echo "begin: $time1" echo "end: $time2" echo "gap: $gap"
说明下上面红色部分的含义:
-train 训练数据 -output 结果输入文件,即每个词的向量 -cbow 是否使用cbow模型,0表示使用skip-gram模型,1表示使用cbow模型,默认情况下是skip-gram模型,cbow模型快一些,skip-gram模型效果好一些 -size 表示输出的词向量维数 -window 为训练的窗口大小,5表示每个词考虑前5个词与后5个词(实际代码中还有一个随机选窗口的过程,窗口大小<=5) -negative 表示是否使用负例采样方法0表示不使用,其它的值目前还不是很清楚 -hs 是否使用Hierarchical Softmax方法,0表示不使用,1表示使用 -sample 表示采样的阈值,如果一个词在训练样本中出现的频率越大,那么就越会被采样 -binary 表示输出的结果文件是否采用二进制存储,0表示不使用(即普通的文本存储,可以打开查看),1表示使用,即vectors.bin的存储类型
从我的shell脚本,可以看出,这个将近2G的文本,在24核,几十G内存,我起50个线程。将CPU全都跑满的情况下,也跑了7500多秒。
5》验证效果
原文:http://www.cnblogs.com/shihuc/p/6710461.html