master: Ubuntu 14.04 salve1: Ubuntu 14.04
hadoop: hadoop 2.2.0
修改本机(master)和子节点(slaveN)机器名:打开/etc/hostname文件
sudo gedit /etc/hostname
(修改后需重启才能生效)
修改host文件(映射各个节点IP):
sudo gedit /etc/hosts
在后面添加内容为:
172.22.144.115 master
172.22.144.114 slave1
172.22.144.116 slave2(注意修改为本机IP)
(master、slave1、slave2分别是主节点和子节点的机器名,即hostname里的内容)
为主节点(master)和子节点(slave)分别创建hadoop用户和用户组:
先创建hadoop用户组:
sudo addgroup hadoop
然后创建hadoop用户:
sudo adduser -ingroup hadoop hadoop
(第一个hadoop是hadoop用户组,第二个hadoop指用户名)
给hadoop用户赋予root用户同样的权限,打开/etc/sudoers文件(目的:给hadoop用户sudo权限)
sudo gedit /etc/sudoers
在root ALL=(ALL:ALL) ALL这一行下添加
hadoop ALL=(ALL:ALL) ALL
本机(master)和子节点(slave)安装ssh服务:
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install ssh openssh-server
建立ssh无密码登录环境:
进入新建立的hadoop用户,建议注销当前用户,然后选择hadoop用户
ssh生成密钥有rsa和dsa两种生成方式,默认情况下采用rsa方式
创建ssh-key,这里我们采用rsa方式,在终端/home/hadoop目录下输入:
ssh-keygen -t rsa -P ""
(有确认信息直接回车)
进入~/.ssh/目录下:
cd /home/hadoop/.ssh
将此目录下的id_rsa.pub追加到authorized_keys授权文件中:
cat id_rsa.pub >> authorized_keys
将master节点上的rsa.pub通过ssh传到子节点上(目的:公用公钥密钥)X代表第n个结点
scp ~/.ssh/id_rsa.pub hadoop@slaveX:~/.ssh/
进入~/.ssh/目录下,将id_rsa.pub追加到authorized_keys授权文件中
cd /home/hadoop/.ssh
cat id_rsa.pub >> authorized_keys
测试ssh互信是否建立
ssh hadoop@slave1
(如果不需要输入密码就可以登录成功则表示ssh互信已经建立)
假设将jdk1.8.0下载到了/home/hadoop/Downloads文件夹中,在终端进入该文件夹
cd /home/hadoop/Downloads
tar -xvf jdk-8-linux-x64.tar.gz
然后运行如下的命令,在 /usr/lib 目录中创建一个为保存Java jdk8 文件的目录。
sudo mkdir -p /usr/lib/jvm/jdk1.8.0/
接下来运行如下命令把解压的 JDK 文件内容都移动到创建的目录中。
sudo mv jdk1.8.0/* /usr/lib/jvm/jdk1.8.0/
下一步,运行如下命令来配置 Java
sudo update-alternatives --install "/usr/bin/java" "java" "/usr/lib/jvm/jdk1.8.0/bin/java" 1
接下来,拷贝和粘贴下面这一行到终端执行,以启用 Javac 模块。
sudo update-alternatives --install "/usr/bin/javac" "javac" "/usr/lib/jvm/jdk1.8.0/bin/javac" 1
最后,拷贝和粘贴下面一行到终端以完成最终的安装。
sudo update-alternatives --install "/usr/bin/javaws" "javaws" "/usr/lib/jvm/jdk1.8.0/bin/javaws" 1
要验证下 Java 是否已经完全安装的话,可以运行下面的命令来测试。
java –version
(如果出现jdk的版本信息,则java环境变量配置成功)
1.假设hadoop-2.2.0.tar.gz在/home/hadoop/Downloads目录,先进入此目录
cd /home/hadoop/Downloads
2. 解压hadoop-2.2.0.tar.gz
sudo tar -zxf
hadoop-2.2.0.tar.gz
3. 将解压出的文件夹改名为hadoop;
sudo mv hadoop-2.2.0hadoop
4. 将该hadoop文件夹的属主用户设为hadoop
sudo chown -R hadoop:hadoop hadoop
5. 打开hadoop/etc/hadoop-env.sh文件;
sudo gedit hadoop/etc/hadoop/hadoop-env.sh
6. 配置etc/hadoop-env.sh(找到export JAVA_HOME=...,修改为本机jdk的路径);
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0
7. 打开etc/core-site.xml文件;
sudo gedit hadoop/etc/hadoop/core-site.xml
在<configuration>标签中添加如下内容:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
注意:master为主结点用户名字,即hosts里面的master结点名字
8. 打开etc /mapred-site.xml文件,如果没有此文件,则将mapred-site.xml.template重命名即可
sudo gedit hadoop/etc/hadoop/mapred-site.xml
在<configuration>标签中添加如下内容
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
</configuration>
注意:master为主结点用户名字,即hosts里面的master结点名字
9. 打开etc/hdfs-site.xml文件;
sudo gedit hadoop/etc/hadoop/hdfs-site.xml
在<configuration>标签中添加如下内容
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/datalog1,/usr/local/hadoop/datalog2</value>
</property>
<property>
<name>dfs.data.dir</name>
< value>/usr/local/hadoop/data1,/usr/local/hadoop/data2</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
10. 打开etc/slaves文件,添加作为slaveX的主机名,一行一个。
sudo gedit hadoop/etc/hadoop/slaves
这里填成下列的内容 :
slave1
slave2
11、将还在/home/hadoop/Downloads目录下的hadoop目录移动到/usr/local/下
sudo mv /home/hadoop/Downloads/hadoop /usr/local/
将配置信息复制到子节点上
hosts文件的复制,先将文件复制到/home/hadoop下面:
sudo scp /etc/hosts hadoop@slaveX:/home/hadoop
再在datanode机器上将其移到相同的路径下面/etc/hosts
sudo mv /home/hadoop/hosts /etc/hosts (这条命令在子节点上执行)
hadoop文件夹的复制,其中的配置也就一起复制过来了!
scp -r /usr/local/hadoop hadoop@slaveX:/home/hadoop
然后在子节点上执行
sudo mv /home/local/hadoop /usr/local/
(如果提示是移动文件夹,则加上-r参数)
并且要将所有节点的hadoop的目录的权限进行如下的修改:
sudo chown -R hadoop:hadoop Hadoop
(在/usr/local/目录下执行此命令)
子节点datanode机器要把复制过来的hadoop里面的data1,data2和logs删除掉!
配置完成
首先终端进入/usr/local/hadoop/目录下
重启hadoop
bin/stop-all.sh
bin/hdfs namenode -format (格式化集群)
bin/start-all.sh
连接时可以在namenode上查看连接情况:
bin/hdfs dfsadmin –report
(注意这里是在/usr/local/hadoop下)
结果如图:
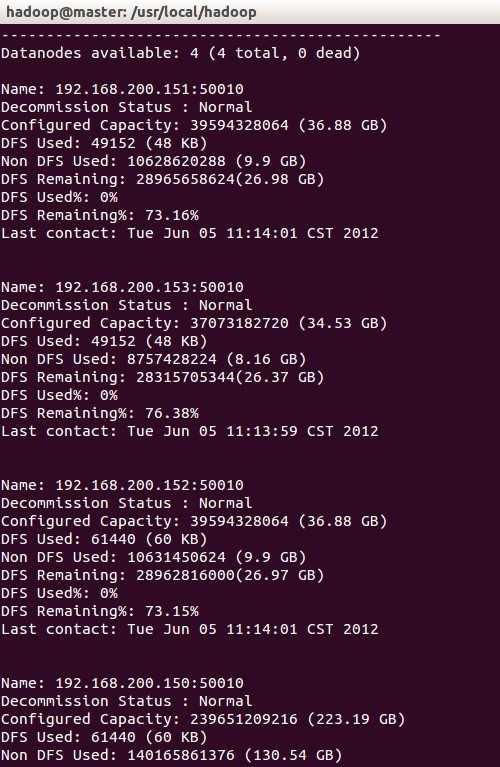
也可以直接进入网址:
结果如图:
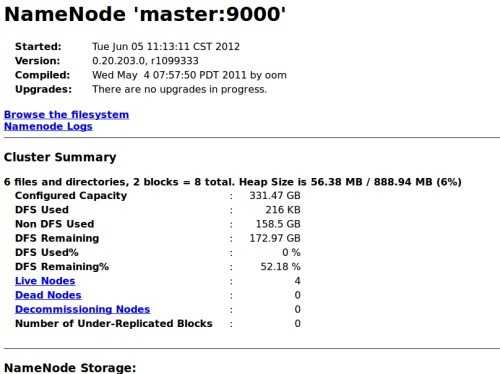
创建测试txt文件
查看目录
bin/hdfs dfs -ls /
(这里的路径为/usr/local/hadoop注意不要忘了)
创建目录:
bin/hdfs dfs -mkdir /input
用示例文本文件做为输入:
在本地新建两个测试文件file01和file02,并填入一些内容
假设file01和file02在/home/hadoop目录下
将两个文件上传至hdfs文件系统
bin/hdfs dfs –put /home/Hadoop/file01 /input/
bin/hdfs dfs –put /home/Hadoop/file02 /input/
子节点离开安全模式,否则可能会导致无法读取input的文件:
bin/hdfs dfsadmin –safemode leave
运行wordcount程序:
bin/hadoop jar /xxx/xxx.jar wordcount /input/ /output
(这里的/XXX/代表/usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar)
查看结果:
bin/hdfs dfs -cat /output/part-r-00000
重复运行需要删除output,否则会抛出文件夹已经存在的异常
bin/hdfs dfs -rmr /output
Ubuntu14.04下Hadoop2.2.0集群搭建,布布扣,bubuko.com
原文:http://www.cnblogs.com/wjdwjd/p/3774082.html