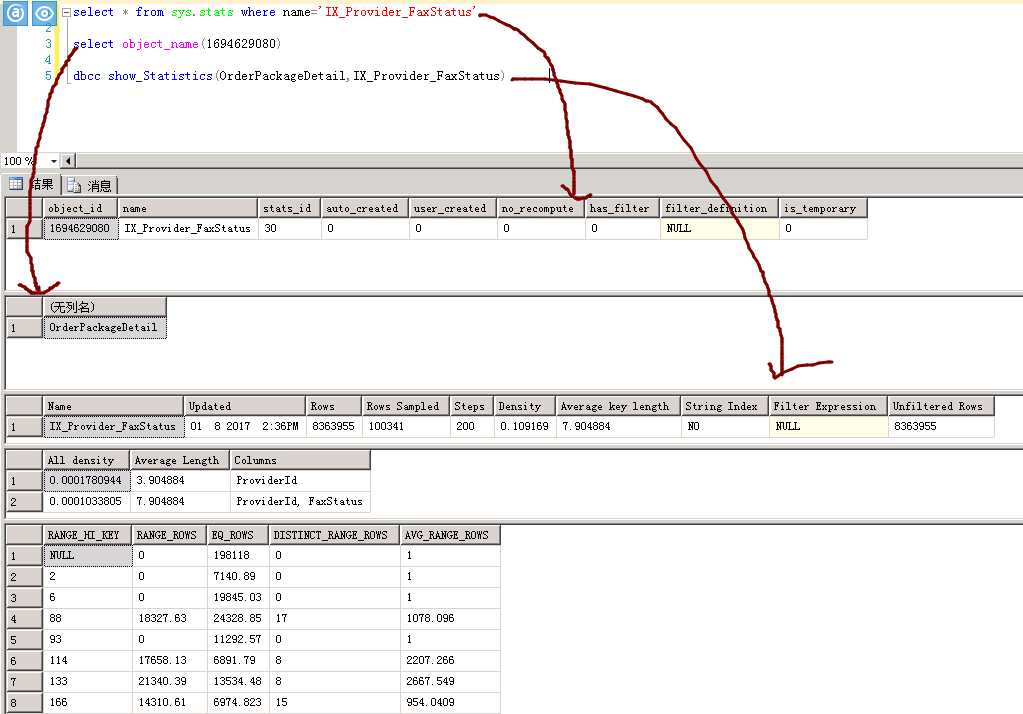
可以看到,统计信息分为三部分内容,头信息,数据字段选择性及直方图。
| 列名 | 说明 |
| Name | 统计信息的名称。 |
| Updated | 上次更新统计信息的日期何时间 |
| Rows | 预估表中的行数,不一定是精确的 |
| Rows Sampled | 统计信息的抽样行数,如果小于Rows,则说明直方图和密度结果是更加抽样行估计的 |
| Steps | 直方图中的梯级数。 Number of steps in the histogram. 每个梯级都跨越一个列值范围,后跟上限列值。 直方图梯级是根据统计信息中的第一个键列定义的。 最大梯级数为 200。 |
| Density | 计算公式为 1/统计信息对象第一个键列中的所有值(不包括直方图边界值)的非重复值。 查询优化器不使用此 Density 值,显示此值的目的是为了与 SQL Server 2008 之前的版本实现向后兼容。 |
| Average key length | 统计信息对象中所有键列的每个值的平均字节数。 |
| String Index | Yes 指示统计信息对象包含字符串摘要统计信息,以改进对使用 LIKE 运算符的查询谓词的基数估计;例如 WHERE ProductName LIKE ‘%Bike‘。 Yes indicates the statistics object contains string summary statistics to improve the cardinality estimates for query predicates that use the LIKE operator; for example, WHERE ProductName LIKE ‘%Bike‘. 字符串摘要统计信息与直方图分开存储,并当它是类型的统计信息对象第一个键列上创建char, varchar, nchar, nvarchar, varchar (max), nvarchar (max),文本,或ntext。 |
| Filter Expression | 包含在统计信息对象中的表行子集的谓词。 NULL = 未筛选的统计信息。 有关筛选的谓词的详细信息,请参阅Create Filtered Indexes。 有关筛选的统计信息的详细信息,请参阅统计信息。 |
| Unfiltered Rows | 应用筛选表达式前表中的总行数。 如果筛选表达式为 NULL,则 Unfiltered Rows 等于 Rows。 |
| 列名 | Description |
| Density | 密度为 1/非重复值。 结果显示统计信息对象中各列的每个前缀的密度,每个密度显示一行。 非重复值是每个行前缀和列前缀的列值的非重复列表。 例如,如果统计信息对象包含键列 (A, B, C),结果将报告以下每个列前缀中非重复值列表的密度:(A)、(A,B) 以及 (A, B, C)。 使用前缀 (A, B, C),以下每个列表都是一个非重复值列表:(3, 5, 6)、(4, 4, 6)、(4, 5, 6) 和 (4, 5, 7)。 使用前缀 (A, B),相同列值则具有以下非重复值列表:(3, 5)、(4, 4) 和 (4, 5) |
| Average Length | 存储列前缀的列值列表的平均长度(以字节为单位)。 例如,如果列表 (3, 5, 6) 中的每个值都需要 4 个字节,则长度为 12 个字节。 |
| columns | 为其显示 All density 和 Average length 的前缀中的列的名称。 |
| 列名 | Description |
|---|---|
| RANGE_HI_KEY | 直方图梯级的上限列值。 列值也称为键值。 |
| RANGE_ROWS | 其列值位于直方图梯级内(不包括上限)的行的估算数目。 |
| EQ_ROWS | 其列值等于直方图梯级的上限的行的估算数目。 |
| DISTINCT_RANGE_ROWS | 非重复列值位于直方图梯级内(不包括上限)的行的估算数目。 |
| AVG_RANGE_ROWS | 重复列值位于直 方图梯级内(不包括上限)的平均行数(如果 DISTINCT_RANGE_ROWS > 0,则为 RANGE_ROWS / DISTINCT_RANGE_ROWS)。 |
每个表格或者索引视图 何时创建统计信息、基于哪些列创建统计信息及何时更新统计信息,需要根据 AUTO_CREATE_STATISTICS 、 AUTO_UPDATE_STATISTICS、 AUTO_UPDATE_STATISTICS_ASYNC 的设定值 来确定,这三个属于 数据库级别的选项,可以通过系统视图查看,也可以通过 图形界面选择数据库的“属性”,查看“选项”。

1 --查看数据库统计信息选项设定值 2 SELECT 3 name dbname, 4 is_auto_create_stats_on, 5 is_auto_update_stats_on, 6 is_auto_update_stats_async_on 7 FROM sys.databases
1 SELECT OBJECT_NAME(s.object_id) AS object_name, 2 COL_NAME(sc.object_id, sc.column_id) AS column_name, 3 s.name AS statistics_name 4 FROM sys.stats AS s JOIN sys.stats_columns AS sc 5 ON s.stats_id = sc.stats_id AND s.object_id = sc.object_id 6 WHERE s.name like ‘_WA%‘ 7 ORDER BY s.name;
常规情况下,查询优化器创建的统计信息就可以满足我们的大多数需求,但是如果出现以下情况,可以考虑手动创建:
1 --更新指定统计信息 2 UPDATE STATISTICS Sales.SalesOrderDetail AK_SalesOrderDetail_rowguid; 3 GO 4 5 --更新表格上的所有统计信息 6 UPDATE STATISTICS Sales.SalesOrderDetail; 7 GO 8 9 --更新整个数据库上的所有统计信息 10 EXEC sp_updatestats; 11 12 --删除统计信息 13 DROP STATISTICS Purchasing.Vendor.VendorCredit, Sales.SalesOrderHeader.CustomerTotal; 14 GO 15 16 --查看统计信息上一次更新时间 17 18 SELECT 19 OBJECT_NAME(OBJECT_ID) 20 FROM sys.stats 21 WHERE STATS_DATE(object_id, stats_id) is not null
原文:http://www.cnblogs.com/zhaolizhe/p/6953856.html