Requests是一个很方便的python网络编程库,用官方的话是“非转基因,可以安全食用”。里面封装了很多的方法,避免了urllib/urllib2的繁琐。
这一节使用requests库对猫眼电影的TOP100榜进行抓取。
首先确定要爬取的url为http://maoyan.com/board/4,通过requests模块,打印出页面的信息
def get_a_page(url): try: response = requests.get(url) if response.status_code == 200:#状态码,200表示请求成功 return response.text #返回页面信息 return None except RequestException : return None
上面是代码及注释,为了防止再抓取时候出现异常,requests的异常有这些,其中RequestException是异常的父类,故我们直接导入
from requests.exceptions import RequestException
作为异常处理。这样就得到了该url地址的网页内容。
首先看一些页面的大致情况,其中【霸王别姬】就是我们要抓取的栏目,栏目下面又分了一些小内容,如下面黑色箭头所示。
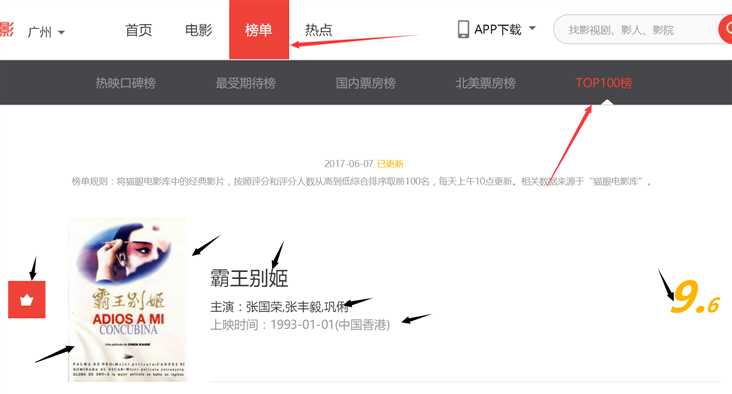
先看一下页面大致情况,右键【审查元素】
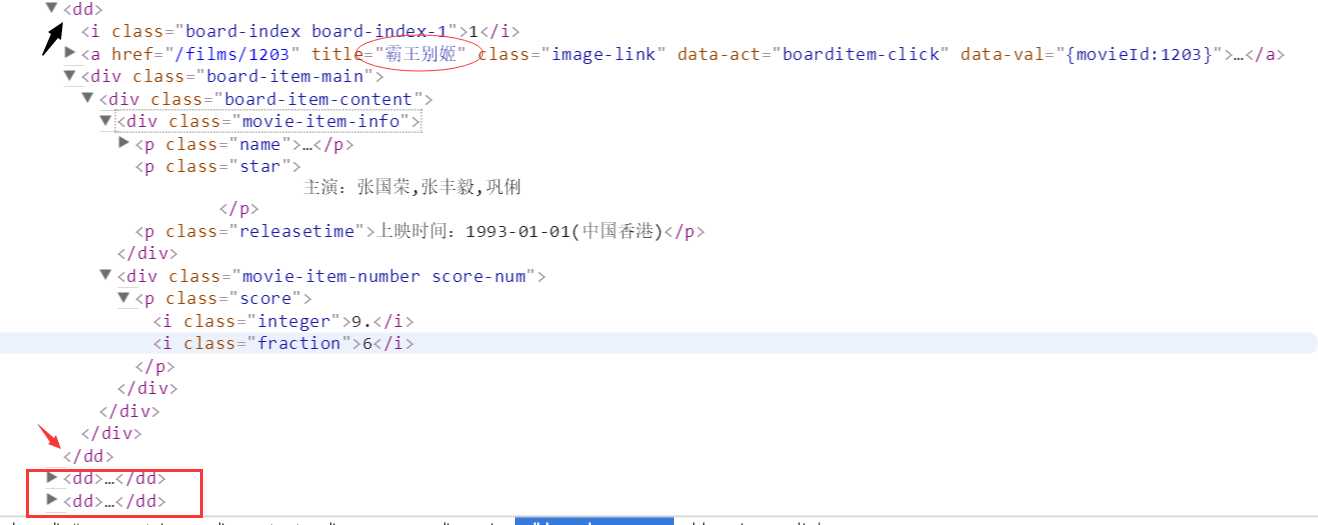
可以看出<dd>标签包裹着每一个电影的信息,用正则表达式找到想要的元素。
reg = re.compile(‘<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name">‘ + ‘<a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>‘ + ‘.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>‘,re.S)
依次捕获的是 排名,地址,名称,主演,时间,整数评分,小数评分。这里我用字典的形式存储,返回一个生成器。
items = reg.findall(html) for item in items: yield{ "index":item[0], "image":item[1], "title":item[2], "actor":item[3].strip()[3:], "time":item[4].strip()[5:], "score":item[5]+item[6] }
抓取到电影列表,剩下就是将电影列表写入文件中,由于返回的是一个字典对象,可以使用pickle方法进行序列化,但为了方便以后的查阅,这里用文本方式保存
def write_to_file(contents): c = "" with codecs.open("result.txt",‘a‘,encoding="utf-8",errors="ignore") as f: for key,value in contents.items(): c += key + ":" + value +"\t" f.write(c + "\n")
返回的是一个字典格式,可是借助json方法进行序列化
def write_to_file(contents): with codecs.open("result.txt",‘a‘,encoding="utf-8",errors="ignore") as f: f.write(json.dumps(contents,ensure_ascii=False) + ‘\n‘)
其中的dumps方法是将obj序列化为JSON格式的字符串,这里面要注意的是编码问题。最后就是抓取整个榜单了,可以加入多线程策略,最后的完整代码
# -*- coding: utf-8 -*- import requests,re import codecs from requests.exceptions import RequestException from multiprocessing import Pool import json def get_a_page(url): try: response = requests.get(url) if response.status_code == 200: return response.text return None except RequestException : return None def parse_a_page(html): #排名,地址,名称,主演,时间,评分1,评分2 reg = re.compile(‘<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name">‘ + ‘<a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>‘ + ‘.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>‘,re.S) items = reg.findall(html) for item in items: yield{ "index":item[0], "image":item[1], "title":item[2], "actor":item[3].strip()[3:], "time":item[4].strip()[5:], "score":item[5]+item[6] } def write_to_file(contents):#这里面两个方法。一种是用json,一种是转为字符串 c = "" with codecs.open("result.txt",‘a‘,encoding="utf-8",errors="ignore") as f: #for key,value in contents.items(): #c += key + ":" + value +"\t" f.write(json.dumps(contents,ensure_ascii=False) + ‘\n‘) #print c #f.write(c + "\n") def main(offset): url = "http://maoyan.com/board/4?offset=%s" %offset print url html = get_a_page(url) for item in parse_a_page(html): write_to_file(item) if __name__ == "__main__": ‘‘‘ for i in range(10): main(i*10) ‘‘‘ pool = Pool()#多线程 pool.map(main,[i*10 for i in range(10)])
原文:http://www.cnblogs.com/wxshi/p/6959816.html