1、ROLLUP()
生成某一维度的分组的小计行,还生成一个总计行。
示例表:
select * from student
我们来看一下具体示例:
select sex,sclass,sum(score) from student group by rollup(sex,sclass)

如图中所示,ROLLUP()为(sex,sclass),(sex)的每个唯一组合生成了一个带有小计的行,还有一个总计行。由此可以看出是从右向左进行顺序汇总的,列的顺序会影响ROLLUP的输出分组,结果集也会受到影响
2、CUBE()
生成所有cube表达式里面所有分组的小计行,以及总计行。
具体示例:
select sex,sclass,sum(score) from student group by cube(sex,sclass)

如图中所示:CUBE()为(sex,sclass),(sex),(sclass)的每个组合生成了一个小计行,还有一个总计行。列的顺序也不会影响结果的输出
3、GROUPING SETS()
在一个查询中指定数据的多个分组,相当于将多个group by联合起来。
a.group by联合
select sex,null sclass,sum(score) from student group by sex union all select null sex,sclass,sum(score) from student group by sclass
结果:

b.grouping sets()
select sex,sclass,sum(score) from student group by grouping sets(sclass,sex)
结果:
两者查询结果是一样的!
还有两个比较重要的函数grouping()和grouping_id(),两者都是用来区分标准值和有ROLLUP、CUBE或GROUPING SETS返回的空值的。
1、GROUPING()
在结果集中,如果GROUPING()返回1则表示是由聚合子句产生的空值,0表示是原有记录里面的空值。
示例:
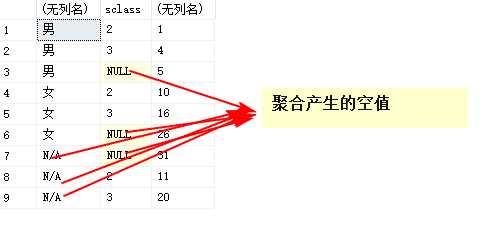
select case when grouping(sex)=‘1‘ then ‘N/A‘ else sex end,sclass,sum(score) from student group by cube(sclass,sex)
结果:
2、GROUPING_ID()
计算分组级别的函数,GROUPING_ID(列1,列2)的列必须包含在GROUP BY的列表达式中,GROUPING_ID()将GROUPING()在每个输出行中为其列列表中的每个列返回的对应值作为0、1字符串拼接起来,
然后将拼接起来的字符串解释为二进制数并返回对应的十进制整数。公式:
示例:
select sex,sclass,sum(score),grouping_id(sclass,sex) from student group by grouping sets(sclass,sex)
结果:
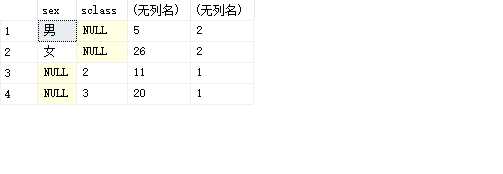
我们来看结果集中的第一行数据,grouping_id(sclass,sex)=grouping(sclass)*2^1+grouping(sex)*2^0
在第一行数据中,grouping(sclass)结果为1、grouping(sex)结果为0,拼接起来的二进制数据就是10,grouping_id(sclass,sex)=1*2^1+0*2^0结果为2,每个行中的grouping_id()都是通过这种方式计算的。
总结:
T-Sql语法:GROUP BY子句GROUPING SETS、CUBE、ROLLUP
原文:http://www.cnblogs.com/caoshiqing/p/6962851.html