在mysql的执行计划中:
id用来表示执行顺序,id相同的为一组,先执行id数字大的组,然后执行数字小的组。在id相同的一组内,顺序由上而下执行。
表示MySQL在表中找到所需行的方式,又称"访问类型",常见类型如下:
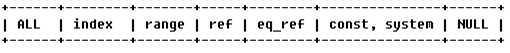
由左至右,由最差到最好。
ALL代表全表扫描,index代表索引全扫描,range索引范围扫描,ref是非唯一性索引扫描,常见的是作用在=的比较上,但是非唯一。eq_ref:唯一性索引扫描。
指出MySQL能使用哪个索引在表中找到行,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用。注:如果使用覆盖索引扫描,此处为空。
显示MySQL在查询中实际使用的索引,若没有使用索引,显示为NULL
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度
表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数
暂时观察,只有当type是ref的时候这个才有值。一般是const或者列。
use index:这里并不是表示使用了索引的意思。使用了索引可以通过key列来查看,而且key列显示了使用索引的名称。use index表示使用覆盖索引扫描。就是说,没有访问数据文件,所有的数据都是从索引文件中获取。
use where:这里并不是表示使用了where条件的意思,而是说服务层从存储引擎获取数据之后再进行where过滤。
Using index condition:表示使用索引条件去读取表中的数据,先扫描索引,然后根据索引指向的主健去读取对应的数据
Using filesort:使用了本地文件进行排序
Using temporary:使用了临时表
Impossible WHERE:出现在优化阶段,优化器根据表定义可以判断出where条件根本不可能成立,比如主健不可能为空
Using join buffer (Block Nested Loop):mysql使用了优化过的nest loop算法,一次读取多个块.
在解析一个sql之前,如果查询缓存是打开的,mysql会去检查这个查询(根据sql的hash作为key)是否存在缓存中,如果命中的话,那么这个sql将会在解析,生成执行计划之前返回结果。
oracle使用基于cost的优化器。
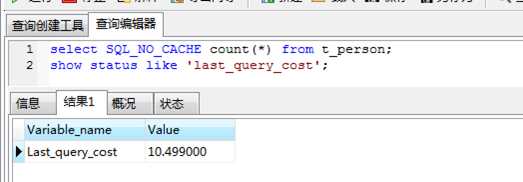
可以使用last_query_cost来获取当前回话的上一个查询的cost:
返回的结果10.499表示mysql查询优化器认为大概需要10个数据页的随机查找才能完成这个查询。这个结果是根据一系列的数据得出的,如每个表或者索引的页面个数,索引的基数,索引和数据行的长度,索引分布情况。
由于统计信息的不准确,或者mysql本身的实现机制,有些情况下,计算的成本并不准确。
原文:http://www.cnblogs.com/xiaolang8762400/p/6974048.html