其实说什么百万千万级别都是虚的,下面给出实现原理和测试结果,原理很简单,我就不上图了:
原理:为了简单明了,只支持单线程,每个协程共享一个4K的空间(你可以用堆,用匿名内存映射或者直接开个数组也都是可以的,总之得保证4K页对齐的空间),每个协程自己有私有栈空间指针privatestackptr,每个时刻只有一个协程在运行,此时栈空间在这个4K共享空间中(当然除了main以外),当切换协程时,动态分配一个堆内存,大小为此时协程栈实际大小(一般都很小,小的只有几十个Bytes, 大的有几百个Bytes,完全不用4KB),然后用privatestackptr指向它,把现在的栈里头的值复制进去。切换到下一个协程,当然这个协程和上一个切出的一样,已经有privatestackptr指针指向了自己的私有栈空间,我们只要用memcpy把这个栈复制回到4K共享空间中,然后用该协程私有的寄存器的值(保存在任务控制块结构体中)跳转即可。所以这样实现最大的开销就是不停的copy进copy出,不停地malloc和不停地free,低效的代价换来的是节约空间。有多节约?我写了个测试用例如下:

1 /************************* Test *************************/ 2 3 #include "ezthread.h" 4 #include <stdio.h> 5 #include <stdlib.h> 6 7 #define NUM 1000000 8 #define CAL 2 9 10 void *sum1tod(void *d) 11 { 12 int i, j=0; 13 14 for (i = 1; i <= d; ++i) 15 { 16 j += i; 17 printf("thread %d is grunting... %d\n",live.current->data->tid , i); 18 switch_to(0); // Give up control to next thread 19 } 20 21 return ((void *)j); 22 } 23 24 void *hello(void *d) 25 { 26 int i, j=0; 27 28 for (i = 1; i <= d; ++i) 29 { 30 printf("hello\n"); 31 switch_to(0); // Give up control to next thread 32 } 33 34 return ((void *)j); 35 } 36 37 int main(int argc, char const *argv[]) 38 { 39 int res = 0; 40 int i; 41 init(); 42 Thread_t *tid1[NUM]; 43 int *res1[NUM]; 44 for(i = 0; i<NUM; i++){ 45 threadCreat(&tid1[i], (i%2)?sum1tod:hello, CAL); 46 } 47 48 49 50 for (i = 1; i <= CAL; ++i){ 51 res+=i; 52 printf("main is grunting... %d\n", i); 53 switch_to(0); //Give up control to next thread 54 } 55 56 for(i = 0; i<NUM; i++){ 57 threadJoin(tid1[i], &res1[i]); //Collect and Release the resourse of tid1 58 res += (int)res1[i]; 59 } 60 61 printf("parallel compute: %d\n", (int)res); 62 printLoop(&dead);printLoop(&live); 63 destroyAll(); 64 return 0; 65 }
测试结果如下:
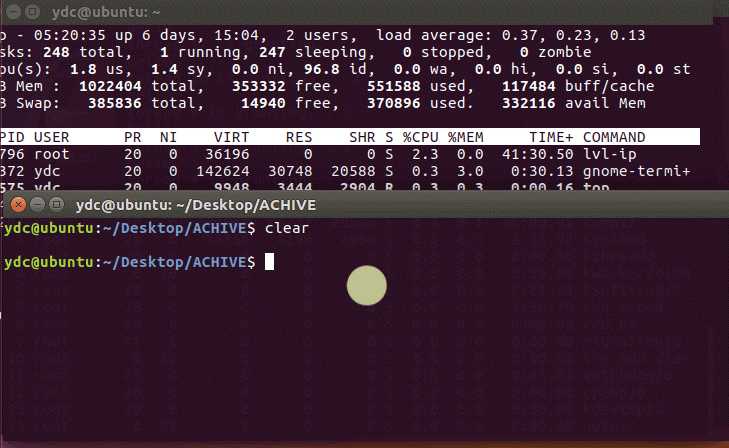
50W个协程做1+2,并返回计算结果3,另外50W个打印hello,用top指令看了下内存占用率,基本是1022404KB*27.2%/1000000 = 285Bytes/Coroutine, 即峰值是平均每个协程占用285Bytes。
1500003这个结果是3*500000+3(main也在无聊的计算1+2)得来的。
更具体的实现参见:http://www.cnblogs.com/github-Yuandong-Chen/p/6849168.html
具体代码放在GitHub:https://github.com/Yuandong-Chen/Easiest-Thread/tree/C1000K
现在代码还十分地buggy,只能在ubuntu,gcc,X86这个环境下运行,我不能保证不出现bus IO error 和 segment fault。因为具体实现我用了一些特殊的手段,smash了栈空间。以后会逐步改善,总的来说,这只是个小玩意,示例性大于实用性。
原文:http://www.cnblogs.com/github-Yuandong-Chen/p/6973932.html
