《cuda programming 》 Shane Cook 第5章 第一节
cpu和gpu有各自独立的内存空间,两者不可以直接访问。
每个线程的执行代码是一样的,数据不同。
Thread---->Warp------>Block------>Grid
入门代码是并行加法: 1.cpu端的数组
2.开辟gpu的buffer : cudaMalloc((void**)&dev_a,arraySize*sizeof(int));
3.把host数据传入buffer : cudaMemcpy(dev_a,a,arraySize*sizeof(int),cudaMemcpyHostToDevice);
4.在Kernel中每个Thread进行相应的计算: addKernelArray<<<1,arraySize>>>(dev_c,dev_b,dev_a);
5.把devcudaMemcpy(c,dev_c,arraySize*sizeof(int),cudaMemcpyDeviceToHost);
结果:
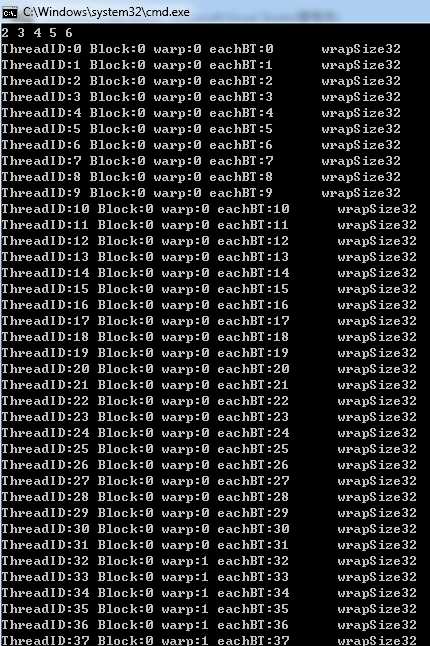
2 3 4 5 6
ThreadID:0 Block:0 warp:0 eachBT:0 wrapSize32
ThreadID:1
Block:0 warp:0 eachBT:1 wrapSize32
ThreadID:2 Block:0 warp:0 eachBT:2
wrapSize32
ThreadID:3 Block:0 warp:0 eachBT:3 wrapSize32
ThreadID:4
Block:0 warp:0 eachBT:4 wrapSize32
ThreadID:5 Block:0 warp:0 eachBT:5
wrapSize32
ThreadID:6 Block:0 warp:0 eachBT:6 wrapSize32
ThreadID:7
Block:0 warp:0 eachBT:7 wrapSize32
ThreadID:8 Block:0 warp:0 eachBT:8
wrapSize32
ThreadID:9 Block:0 warp:0 eachBT:9
wrapSize32
ThreadID:10 Block:0 warp:0 eachBT:10
wrapSize32
ThreadID:11 Block:0 warp:0 eachBT:11
wrapSize32
ThreadID:12 Block:0 warp:0 eachBT:12
wrapSize32
ThreadID:13 Block:0 warp:0 eachBT:13
wrapSize32
ThreadID:14 Block:0 warp:0 eachBT:14
wrapSize32
ThreadID:15 Block:0 warp:0 eachBT:15
wrapSize32
ThreadID:16 Block:0 warp:0 eachBT:16
wrapSize32
ThreadID:17 Block:0 warp:0 eachBT:17
wrapSize32
ThreadID:18 Block:0 warp:0 eachBT:18
wrapSize32
ThreadID:19 Block:0 warp:0 eachBT:19
wrapSize32
ThreadID:20 Block:0 warp:0 eachBT:20
wrapSize32
ThreadID:21 Block:0 warp:0 eachBT:21
wrapSize32
ThreadID:22 Block:0 warp:0 eachBT:22
wrapSize32
ThreadID:23 Block:0 warp:0 eachBT:23
wrapSize32
ThreadID:24 Block:0 warp:0 eachBT:24
wrapSize32
ThreadID:25 Block:0 warp:0 eachBT:25
wrapSize32
ThreadID:26 Block:0 warp:0 eachBT:26
wrapSize32
ThreadID:27 Block:0 warp:0 eachBT:27
wrapSize32
ThreadID:28 Block:0 warp:0 eachBT:28
wrapSize32
ThreadID:29 Block:0 warp:0 eachBT:29
wrapSize32
ThreadID:30 Block:0 warp:0 eachBT:30
wrapSize32
ThreadID:31 Block:0 warp:0 eachBT:31
wrapSize32
ThreadID:32 Block:0 warp:1 eachBT:32
wrapSize32
ThreadID:33 Block:0 warp:1 eachBT:33
wrapSize32
ThreadID:34 Block:0 warp:1 eachBT:34
wrapSize32
ThreadID:35 Block:0 warp:1 eachBT:35
wrapSize32
ThreadID:36 Block:0 warp:1 eachBT:36
wrapSize32
ThreadID:37 Block:0 warp:1 eachBT:37
wrapSize32
ThreadID:38 Block:0 warp:1 eachBT:38
wrapSize32
ThreadID:39 Block:0 warp:1 eachBT:39
wrapSize32
ThreadID:40 Block:0 warp:1 eachBT:40
wrapSize32
ThreadID:41 Block:0 warp:1 eachBT:41
wrapSize32........................................
................................................
疑问:现在还没想通:
当test_ThreadNums_BlockNums_WarpNums<<<2,64>>>里参数修改成《2,128》时,输出结果不理解。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98 |
#include "cuda_runtime.h"#include "device_launch_parameters.h"#include <stdio.h>#include<iostream>using
namespace std;__global__ void
addKernelArray(int*c,int* a,int*b){ int
i = threadIdx.x; c[i] = a[i]+b[i];}//calculate NO. __global__ void
test_ThreadNums_BlockNums_WarpNums(int* threadNum,int
*blockNums,int
*WarpNums,int
*threadIndex,int
*gpu_warpSize){ int
i = threadIdx.x + (blockIdx.x*blockDim.x);//thread ID threadNum[i] = threadIdx.x;//each block‘s thread NO. blockNums[i] = blockIdx.x; WarpNums[i] = threadIdx.x/warpSize; threadIndex[i] = i;//thread ID gpu_warpSize[i] = warpSize;}int
main(){ //BEGIN calculate two arrays add const
int arraySize = 5; int
a[arraySize] = {1,2,3,4,5}; int
b[arraySize] = {1,1,1,1,1}; int
c[arraySize] = {0}; int
*dev_a=0; int
*dev_b=0; int
*dev_c=0; //allocate gpu buffer cudaMalloc((void**)&dev_a,arraySize*sizeof(int)); cudaMalloc((void**)&dev_b,arraySize*sizeof(int)); cudaMalloc((void**)&dev_c,arraySize*sizeof(int)); //copy host memory to gpu buffer cudaMemcpy(dev_a,a,arraySize*sizeof(int),cudaMemcpyHostToDevice); cudaMemcpy(dev_b,b,arraySize*sizeof(int),cudaMemcpyHostToDevice); cudaMemcpy(dev_c,c,arraySize*sizeof(int),cudaMemcpyHostToDevice); addKernelArray<<<1,arraySize>>>(dev_c,dev_b,dev_a); //copy gpu buffer to host memory cudaMemcpy(c,dev_c,arraySize*sizeof(int),cudaMemcpyDeviceToHost); for(int
i=0;i<arraySize;i++) { std::cout<<c[i]<<" "; } std::cout<<std::endl; //END calculate two arrays add //BEGIN capture thread,block,warp num const
int cudaBlockNums =2; const
int cudaAllThreadNums =128; int
cpu_ThreadId[cudaAllThreadNums] = {0}; int
cpu_BlockNums[cudaAllThreadNums] = {0}; int
cpu_WarpNums[cudaAllThreadNums]={0}; int
cpu_eachBlockThreadNum[cudaAllThreadNums] = {0}; int
cpu_warpSize[cudaAllThreadNums] = {0}; int
*gpu_threadId=0; int
*gpu_block=0; int
*gpu_warp=0; int
*gpu_eachBlockThreadNums=0; int
*gpu_warpSize=0; //申请gpu buffer cudaMalloc((void**)&gpu_threadId,cudaAllThreadNums*sizeof(int)); cudaMalloc((void**)&gpu_block,cudaAllThreadNums*sizeof(int)); cudaMalloc((void**)&gpu_warp,cudaAllThreadNums*sizeof(int)); cudaMalloc((void**)&gpu_eachBlockThreadNums,cudaAllThreadNums*sizeof(int)); cudaMalloc((void**)&gpu_warpSize,cudaAllThreadNums*sizeof(int)); //记录数据 test_ThreadNums_BlockNums_WarpNums<<<2,64>>>(gpu_eachBlockThreadNums,gpu_block,gpu_warp,gpu_threadId,gpu_warpSize); //拷贝到cpu里 cudaMemcpy(cpu_ThreadId,gpu_threadId,cudaAllThreadNums*sizeof(int),cudaMemcpyDeviceToHost); cudaMemcpy(cpu_BlockNums,gpu_block,cudaAllThreadNums*sizeof(int),cudaMemcpyDeviceToHost); cudaMemcpy(cpu_WarpNums,gpu_warp,cudaAllThreadNums*sizeof(int),cudaMemcpyDeviceToHost); cudaMemcpy(cpu_eachBlockThreadNum,gpu_eachBlockThreadNums,cudaAllThreadNums*sizeof(int),cudaMemcpyDeviceToHost); cudaMemcpy(cpu_warpSize,gpu_warpSize,cudaAllThreadNums*sizeof(int),cudaMemcpyDeviceToHost); for(int
i=0;i<cudaAllThreadNums;i++) { std::cout<<"ThreadID:"<<cpu_ThreadId[i]<<" Block:"<<cpu_BlockNums[i]<<" warp:"<<cpu_WarpNums[i]<<" eachBT:"<<cpu_eachBlockThreadNum[i]<<" wrapSize"<<cpu_warpSize[i]<<endl; } //END capture thread,block,warp num return
0;} |
CUDA5.5入门1. host和gpu之间的通信,布布扣,bubuko.com
原文:http://www.cnblogs.com/dust-fly/p/3778839.html